The Acceptance Cost of Code. Cognitive Load, AI Review, and Human-Operable Software.
Field Notes #9. A research note on cognitive load, acceptance cost, and the new review bottleneck.
Manu Bhardwaj. ifitsmanu.com. 22 June 2026. Last updated 22 June 2026. Version 2.1.
Cite this article. Field notes index. Source repository. Source essay.
Source and originality note. This is an original research field note, not a reproduction of Artem Zakirullin’s article. The source essay is treated as a primary technical artifact: a visual, developer-facing argument about human limits in software design. This note reads it against cognitive-load theory, working-memory research, information hiding, code-review experiments, interruption recovery, and evidence on AI-generated code. Source diagrams from the Creative Commons Attribution 4.0 GitHub repository are reproduced as attributed figures. The source header image is omitted because the source page notes weaker Reddit provenance.
TL;DR
The bottleneck in modern software is no longer how fast code can be produced. It is how cheaply code can be accepted. AI does not remove cognitive load; it relocates it into acceptance. A change is acceptable only when a maintainer can reconstruct enough state to decide that it is correct, safe, reversible, and worth merging. Cognitive load is therefore not a readability complaint. It is the hidden price of acceptance.
Artem Zakirullin’s cognitive-load essay is useful because it names the real failure: codebases do not collapse only because they are complex. They collapse because they force every maintainer to rebuild the system in working memory before touching it. AI makes the problem harder. Models can generate code faster than teams can verify it, so the scarce resource becomes human acceptance bandwidth.
This note proposes the Operator Load Budget as a field instrument for pricing that bandwidth. The budget counts facts, jumps, private mappings, recovery state, evidence gaps, and AI-review obligations, then subtracts durable schemas such as tests, types, traces, runbooks, and deep modules. When the budget is exceeded, the system is no longer human-operable. It may still run. It may still pass tests. But it cannot be safely changed at the speed the organization believes it is moving.
Abstract
Software maintainability is usually discussed through proxies: clean code, modularity, complexity scores, review size, architecture style, onboarding time, and documentation quality. These proxies point at one deeper constraint: the acceptance cost of code. A maintainer must carry enough temporary state to accept or reject a change. That state includes domain facts, control-flow jumps, private mappings, incident recovery context, missing evidence, and now model-generated assumptions. Drawing on Zakirullin’s developer-facing cognitive-load essay, cognitive-load theory, working-memory research, information hiding, code-review experiments, interruption recovery, and empirical work on AI-generated code, this field note reframes cognitive load as an operator control-plane constraint. The central claim is simple: a codebase is human-operable when acceptance cost remains below reconstruction cost. When accepting a change requires rebuilding the system from scattered fragments, the architecture is taxing the operator instead of helping them.
Contribution
This note makes five claims.
- Cognitive load is an acceptance cost. It measures the temporary state a maintainer must reconstruct before they can safely merge, reject, debug, resume, or rollback.
- Extraneous load is a verification tax. It raises the cost of deciding whether a change is correct, not only the cost of reading code.
- Deep modules are cognitive compression. They work when their interface hides more volatile state than it exposes.
- Interruption cost is reconstruction cost. A system is not operable if work can continue only while a human’s temporary mental stack remains intact.
- AI-generated code shifts the bottleneck downstream. Generation becomes cheap; human acceptance bandwidth becomes scarce.
Evidence Stack
This is a field note, not a controlled experiment. Its job is to connect a practitioner artifact to a research-backed operating model. The evidence stack is:
| Evidence layer | What it contributes | Why it matters here |
|---|---|---|
| Zakirullin’s essay and repository | A developer-facing taxonomy of cognitive load, deep modules, shallow modules, interruption, mental models, and AI-generated code | Primary source and visual case study |
| Cognitive-load theory | Intrinsic versus extraneous load, element interactivity, expertise dependence, and measurement limits | Prevents “simplicity” from becoming taste |
| Working-memory research | Short-term memory is sharply capacity-limited, often closer to four chunks than seven | Makes the operator budget a real constraint |
| Information hiding and deep modules | Good boundaries hide change-prone design decisions behind stable interfaces | Explains why some complexity should be internal |
| Code-review experiments | Review performance is task-sensitive, and checklists can help only when they reduce the right load | Links cognitive load to acceptance cost |
| Interruption studies | Resumption requires rebuilding context before editing can continue | Turns “flow” into a recoverability problem |
| AI-generated-code studies | Real AI-authored commits can introduce persistent quality issues and maintenance costs | Shows why reviewability matters more as generation cost falls |
Claim Status
The claims in this note have different epistemic weight. Treating all of them as equally proven would be bad engineering and bad science.
| Claim | Status | What would weaken it |
|---|---|---|
| Working memory is sharply capacity-limited | Research-backed constraint | Stronger evidence that maintenance tasks routinely bypass short-term memory limits without durable schemas |
| Intrinsic load and extraneous load map cleanly onto software maintenance | Theoretical transfer plus field observation | A better taxonomy that predicts review and recovery cost with less ambiguity |
| The Operator Load Budget is useful for review | Field heuristic | Controlled review studies showing no relation between the counted items and review latency, defects, or interruption recovery |
| AI coding shifts bottlenecks from generation to acceptance | Field inference with early empirical support | Tooling that reliably ships patches with verified invariants, narrow scope, and executable evidence packets |
| Deep modules lower acceptance cost | Architectural inference from information hiding | Cases where shallow boundaries improve review and recovery without adding hidden state |
1. The Diff Is Green. You Still Cannot Merge It.
The failure mode is familiar.
A generated patch arrives. The tests pass. The diff is not large. The code looks locally reasonable. The function names are polite. The PR description says it fixes the bug.
But the reviewer still cannot merge it.
They need to know whether pending means pending payment, pending fulfillment, or pending cancellation. They need to know whether the retry path is idempotent. They need to know whether the event published here is consumed before or after the database transaction commits. They need to know whether a feature flag reverses behavior in one tenant. They need to know whether the migration has already run in staging. They need to know why the agent changed a serializer while fixing a controller. They need to know which test proves the invariant, not merely which test happened to pass.
None of that uncertainty is visible in the line count. It is not captured by “small PR.” It is not fixed by saying the code is clean. The problem is acceptance cost.
The reviewer is not asking, “Can I read this code?” They are asking, “Can I safely accept this change without reconstructing the system from memory?”
That is the unit this article cares about.
2. Cognitive Load Is Acceptance Cost.
Zakirullin defines cognitive load as how much a developer needs to think to complete a task. The phrase is useful because it keeps the unit of analysis attached to work. Not files. Not functions. Not architecture diagrams. A task.
In maintenance, the task is usually not “understand the code.” The task is accept a change, reject a change, fix an incident, resume interrupted work, onboard into an unfamiliar subsystem, or decide whether an abstraction is lying. Cognitive load becomes expensive when it blocks those decisions.
The stronger definition is:
Cognitive load is the amount of temporary state a maintainer must reconstruct before they can safely act.
That moves the conversation away from taste. Some code is visually clean and operationally hostile. Some code is visually dense but operationally honest. A short helper can be worse than a long transaction if the helper forces a reader to leave the local context and rebuild meaning elsewhere. A layer can be worse than duplication if it turns one visible rule into five files and a naming convention. A generated patch can be worse than hand-written code if it transfers unspoken assumptions to the reviewer.
Human-operable software keeps acceptance cost low. It does that by moving state out of private working memory and into durable artifacts: names, tests, types, traces, schemas, runbooks, diagrams, and deep modules.
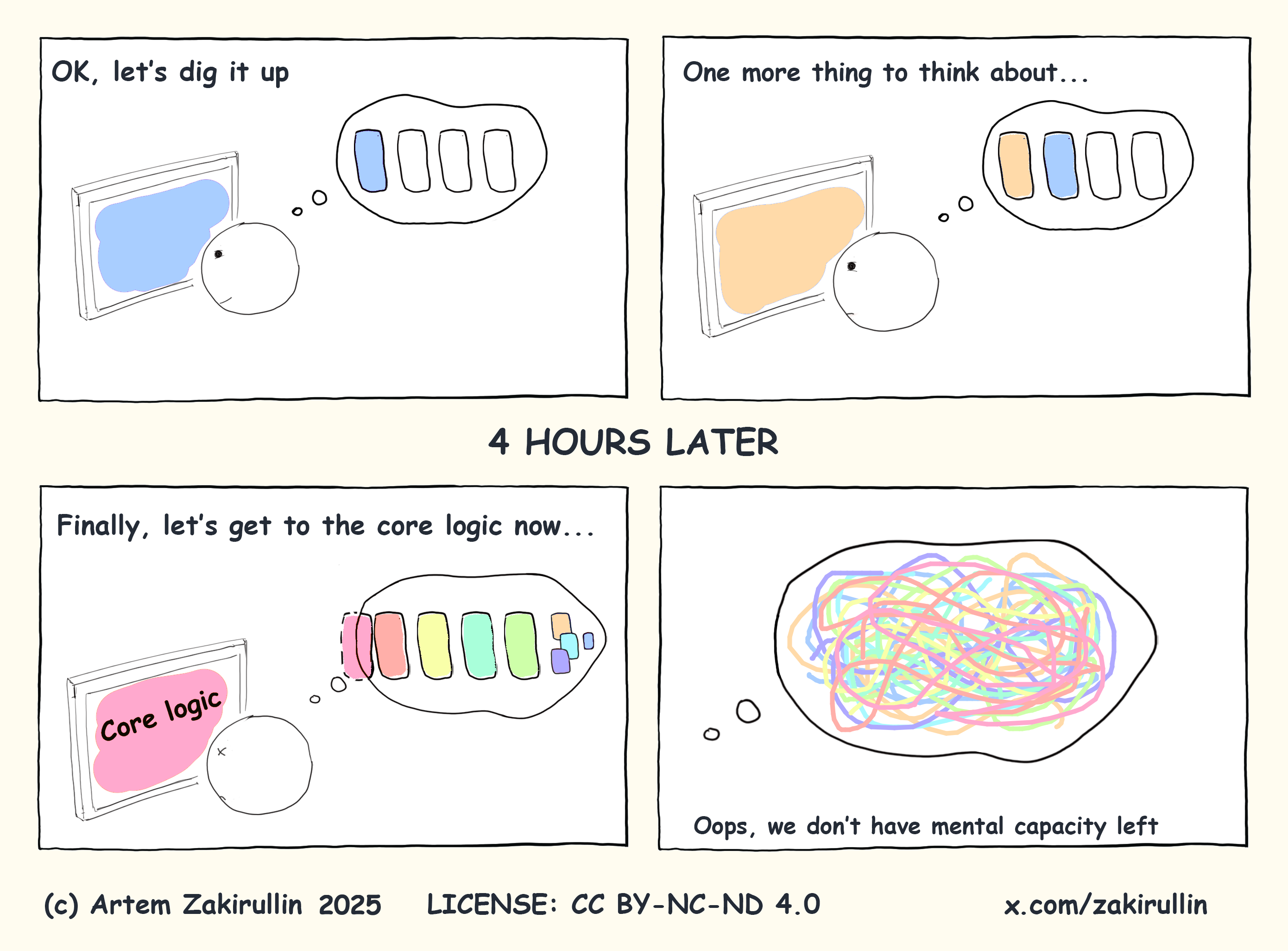
3. The Research Gives The Constraint Teeth.
Cognitive-load theory separates intrinsic load from extraneous load. Intrinsic load is the difficulty of the thing being learned or processed. Extraneous load is burden introduced by presentation, procedure, or representation. Software maps cleanly onto that distinction.
Intrinsic load is the domain. A scheduler, payment workflow, compiler pass, trading system, medical triage rule, or distributed transaction can be difficult because the world is difficult. Pretending otherwise makes the system less correct.
Extraneous load is the avoidable tax around the domain. It is the tax from weak names, magic statuses, unearned layers, framework side effects, hidden ownership, stale runbooks, undocumented flags, wide PRs, and generated code without evidence.
The distinction matters because it prevents a cheap move. Teams often call the whole system “complex” and stop there. But the operator question is sharper: which part of the load belongs to the domain, and which part did we add?
Working-memory research makes the constraint operational. Cowan’s work on short-term memory argues for a capacity closer to four chunks in many settings, not the older seven-item folk number. The exact number is not the point. The point is that a maintainer cannot carry unlimited interacting elements. If one safe edit requires seven hidden facts, three file hops, two undocumented conventions, a stale runbook, and an inferred invariant, the system has already spent more human capacity than it owns.
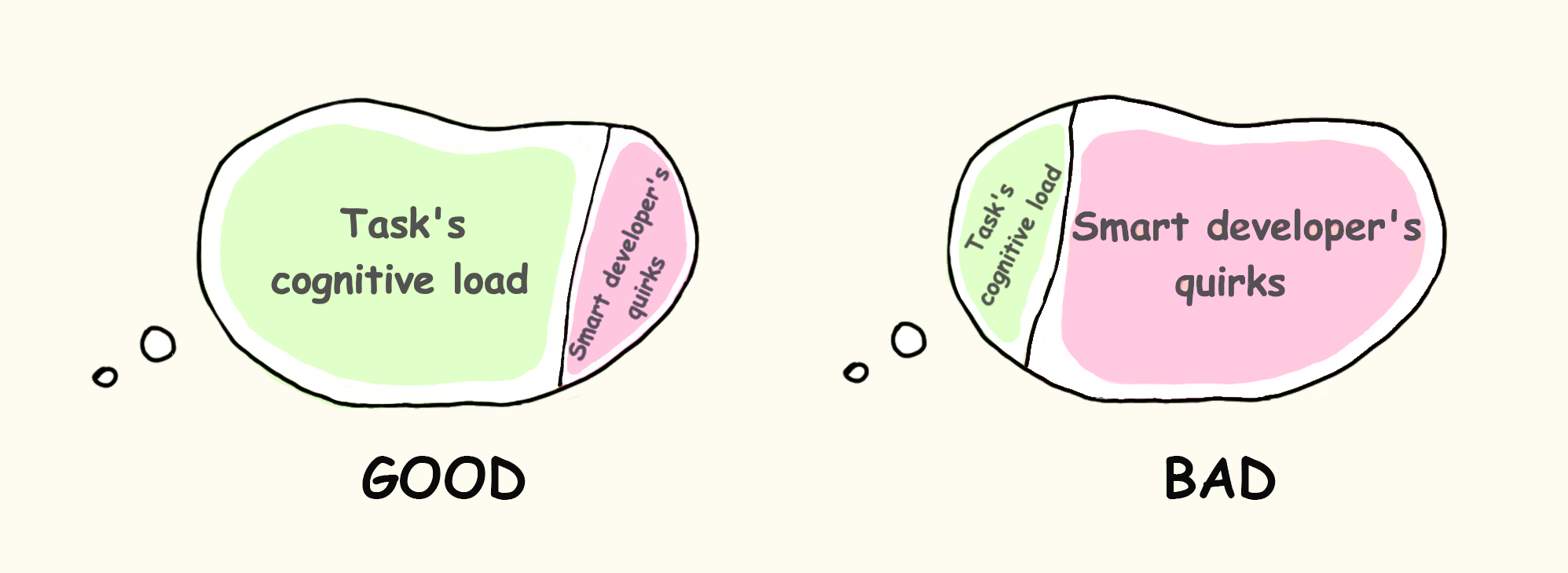
4. The Operator Load Budget.
The practical instrument is:
OLB(change, reviewer) =
F facts
+ J jumps
+ M private mappings
+ R recovery state
+ E evidence gaps
+ A AI-review obligations
- S durable schemasThis is not a universal metric. It is a review discipline.
Facts are conditions the maintainer must keep live: statuses, preconditions, retry rules, feature flags, ownership boundaries, lifecycle hooks, consistency assumptions.
Jumps are places the maintainer must visit before seeing the behavior: files, generated clients, services, dashboards, migrations, issue threads, runbooks, logs.
Private mappings are dictionaries the organization has normalized: type=2 means enterprise override, pending means three different lifecycle states, 418 means expired subscription, one boolean reverses behavior in exactly one path.
Recovery state is what must be rebuilt after interruption: failing command, current hypothesis, local environment, fixture, suspected invariant, next safe step.
Evidence gaps are claims the reviewer must trust because the artifact does not prove them: this cache is safe, this layer isolates change, this migration is idempotent, this generated code preserves behavior.
AI-review obligations are the new costs introduced by generated patches: hallucinated APIs, broad incidental edits, plausible but false invariants, tests that pass without touching the changed behavior.
Durable schemas subtract from load. Good tests, types, traces, runbooks, names, diagrams, and deep modules let the maintainer retrieve state from the artifact instead of carrying it in their head.
The budget is exceeded when the reviewer spends more effort reconstructing the system than evaluating the change.

5. Worked Audit. The Passing Patch That Still Should Not Merge.
Here is the instrument on a synthetic but ordinary review case. An AI patch claims to fix checkout cancellation. Tests pass. The changed code looks short.
Before review, the critical branch looks like this:
export async function cancelOrder(orderId: string, actorId: string) {
const order = await orders.find(orderId);
const payment = await payments.latest(orderId);
if (order.status === 2 && payment.state !== 3) {
await payments.refund(payment.id);
await orders.update(orderId, { status: 7 });
await events.publish("order.updated", { orderId, status: 7 });
return { ok: true };
}
throw new ApiError(418);
}The patch is small, but the reviewer must reconstruct too much:
status === 2means “authorized but not fulfilled.”payment.state !== 3means “not already refunded.”status: 7means “cancelled by customer.”418means “order cannot be cancelled.”order.updatedis consumed by fulfillment before customer email.- The refund call may be retried by the payment provider.
- No test proves idempotency if the event publish fails after refund.
This is not a style problem. It is an acceptance problem. The reviewer cannot decide whether the change is safe without rebuilding the local status dictionary, event ordering, retry semantics, and failure mode.
After review, a lower-load version makes the acceptance packet explicit:
const cancellableStatuses = new Set<OrderStatus>([
"authorized",
"fulfillment_pending",
]);
export async function cancelOrder(orderId: string, actorId: string) {
const order = await orders.find(orderId);
const payment = await payments.latest(orderId);
if (!cancellableStatuses.has(order.status)) {
return rejectCancellation("order_not_cancellable", order.status);
}
if (payment.refundStatus === "refunded") {
return { ok: true, alreadyCancelled: true };
}
await orders.withIdempotencyKey(`cancel:${orderId}`, async () => {
await payments.refund(payment.id);
await orders.markCancelledByCustomer(orderId, actorId);
await events.publish("order.cancelled", { orderId, actorId });
});
return { ok: true };
}The code is longer. It is easier to accept. The domain states are named, the rejection path is self-describing, the event name carries the transition, and idempotency is visible at the boundary where failure matters.
One review pass can score it this way. The numbers are not universal; they are prompts for inspection.
| Budget item | Before | After | Reviewer question |
|---|---|---|---|
| Facts | 7 | 3 | How many domain facts must stay live before the change can be accepted? |
| Jumps | 5 | 2 | How many files, docs, migrations, or dashboards must be opened? |
| Private mappings | 4 | 0 | Which meanings live in numbers, booleans, or local convention? |
| Recovery state | 3 | 1 | Could a reviewer resume tomorrow from the code, test output, and PR note? |
| Evidence gaps | 4 | 1 | Which safety claims are not proven by the artifact? |
| AI-review obligations | 3 | 1 | Which generated assumptions need independent proof? |
| Durable schemas | -2 | -6 | Which names, tests, types, traces, or modules remove state from memory? |
| Net operator load | 24 | 2 | Is acceptance cheaper than reconstruction? |
This table is the part a skeptical systems reader should be able to attack. The weights are deliberately simple. A team can change them, but it cannot avoid the accounting. If a generated patch arrives without named states, an idempotency proof, a narrow event transition, and a test for the failure mode, the review should not be treated as “almost done.” It is still expensive inventory.
For engineering leadership, the Monday morning version is operational:
- Pick the five PRs that took longest to review last week.
- Score each PR with the seven budget rows above.
- Identify the highest repeated cost: private mappings, jumps, evidence gaps, recovery state, or AI obligations.
- Fix that repeated cost in the system, not only in the PR.
- Track review latency and reopen rate for the next two weeks.
The point is not to turn cognition into bureaucracy. The point is to find the load source that keeps taxing every change.
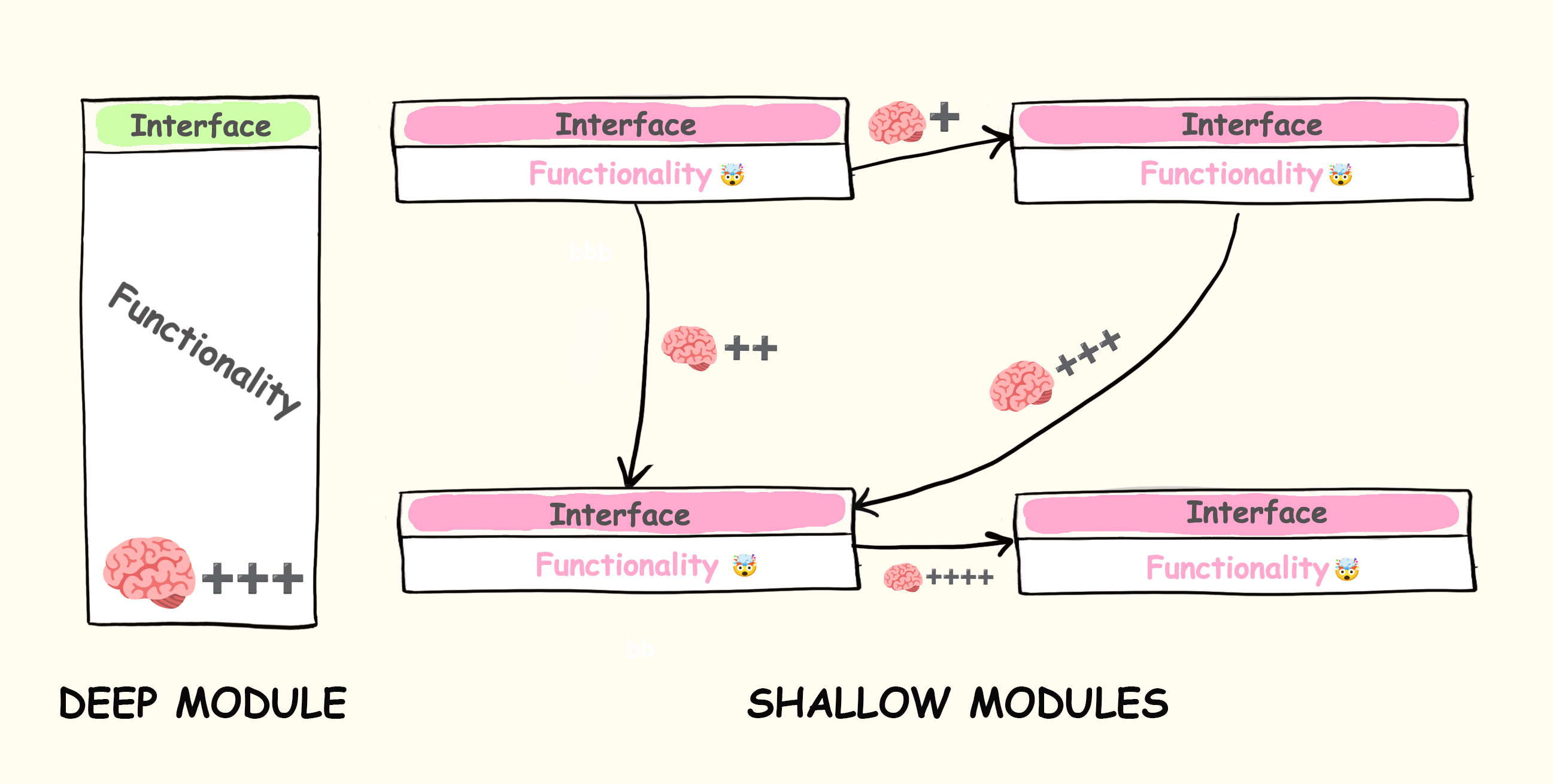
6. Deep Modules Are Not Cleanliness. They Are Compression.
Parnas’s information-hiding argument and Ousterhout’s deep-module frame both point at the same operator rule: a boundary is useful when it hides more volatile state than it exposes.
A module is deep when a caller can use it without rebuilding its internals. It has a small interface because the interface is carrying a real guarantee. A shallow module has the opposite shape. It adds a name, a file, or a layer, but the caller still has to understand the underlying behavior.
The cognitive version is:
A boundary earns its keep only when it lowers acceptance cost.
That is why length is a weak proxy. A ten-line helper can be expensive if it sends the reader away to recover one condition. A ninety-line local operation can be cheap if it keeps a transaction visible and proves the state transition in one place. This does not excuse sprawling files. It means the real question is compression, not size.
Ask what the boundary hides. Ask what invariant it enforces. Ask which future change becomes safer because it exists. Ask whether an incident responder can use the boundary while tired, interrupted, and under pressure. If the answer is vague, the abstraction is not architecture. It is ceremony.
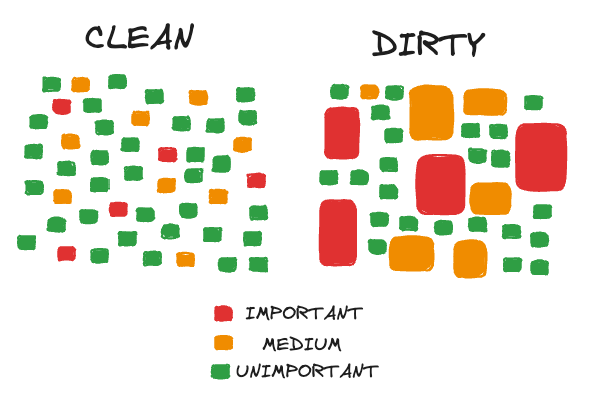
7. Layers Become Trace Debt When They Stop Proving Anything.
Layering is not the enemy. Unearned layering is.
A layer earns its keep when it protects a real variation point, narrows failure, enforces an invariant, or lets a dependency change without forcing callers to learn its private behavior. It fails when every maintainer must walk through it before seeing the actual state transition.
The dangerous architecture is not obviously messy. It is often beautiful on a diagram. Controller, service, use case, port, adapter, repository, mapper. Each step looks respectable. The total path is the problem. The maintainer cannot accept a change until they trace the route and reconstruct which layer actually owns the rule.
Hyrum’s Law makes the leak unavoidable. With enough users, every observable behavior becomes depended on. Internal teams are users too. A repository abstraction may formally hide the database, while production behavior still depends on retry timing, event ordering, cursor shape, null semantics, latency, or side effects. The interface hid the easy part. The real contract leaked through behavior.
The operator test is blunt:
- Where is the first state transition that matters?
- How many files must be opened before it is visible?
- What invariant does each layer enforce?
- What dependency can change without touching callers?
- What incident becomes easier because this layer exists?
If the answers are not crisp, the layer is trace debt.
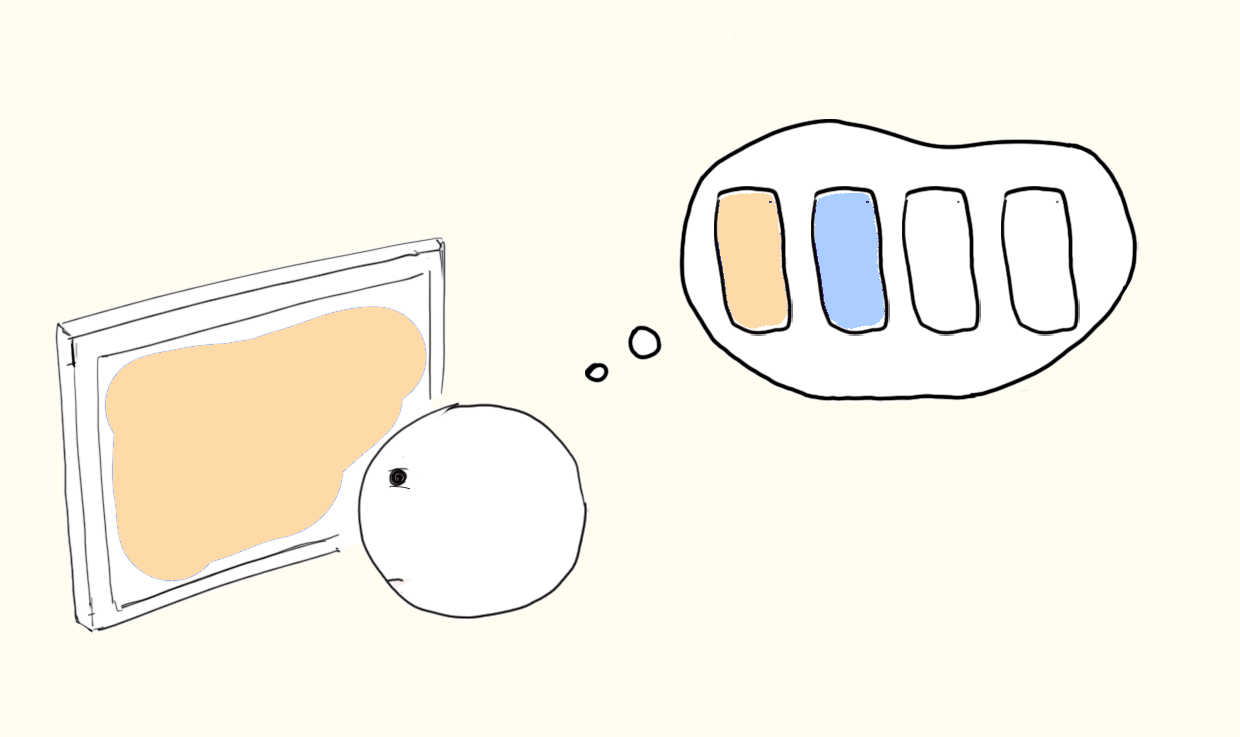
8. Interruption Reveals Whether The System Depends On Live Human Memory.
Interruption is usually treated as productivity loss. For software maintenance, it is a recoverability test.
Parnin and Rugaber’s work on interrupted programming tasks distinguishes ordinary resumption lag from edit lag, the time between returning to a task and making the first edit. That distinction is useful because it measures reconstruction. The developer is not merely “getting back into flow.” They are rebuilding a mental stack that the system failed to externalize.
High operator load makes a system brittle because work can continue only while a human’s temporary memory remains intact. The maintainer holds the failing command, the local fixture, the suspicious branch, the expected invariant, the last hypothesis, and the next edit. A meeting, message, alert, or context switch destroys that stack. When the maintainer returns, the first task is not coding. It is archaeology.
This is why good systems leave tracks. A failing command is pasted into the issue. A test name states the invariant. A trace points to the state transition. A runbook names the owner. A commit message explains before and after. A review comment records what was not verified.
Agent systems raise the standard. A human reviewer should not have to infer an agent’s working memory from a transcript. The artifact should preserve goal, plan, evidence, touched files, commands run, failures, uncertainty, and the next safe action.

9. AI Makes Acceptance Bandwidth The Scarce Resource.
The AI-era mistake is to measure code generation as if acceptance were free.
It is not free. It is the bottleneck.
A model can produce ten plausible patches before lunch. The team still has to decide which patches preserve invariants, which ones hallucinate APIs, which ones broaden scope, which ones pass tests for the wrong reason, and which ones create maintenance debt that will survive into the next release.
Recent empirical work on AI-generated code in the wild supports the concern. Yue et al. report a dataset of 302.6k verified AI-authored commits across 6,299 GitHub repositories and use static analysis to attribute introduced issues. They report 484,366 distinct introduced issues, with code smells as the dominant category, and 22.7 percent of tracked AI-introduced issues surviving to the latest repository revision. The rates will move as tools improve. The structural fact will remain: generated code can become accepted debt.
The code-review literature gives the same warning from another angle. Review is expensive and task-sensitive. Checklists can help in specific conditions, but they do not erase the need to reconstruct state. A generated patch without evidence does not save reviewer time. It purchases author speed by spending reviewer cognition.
The correct unit is not lines generated. It is reviewable change.
A reviewable change carries its goal, invariant, scope, evidence, failure mode, and uncertainty. It lets the reviewer evaluate the patch without reconstructing a hidden system model. It makes acceptance cheaper than rejection.
If AI coding tools do not lower acceptance cost, they are not increasing engineering throughput. They are increasing inventory.

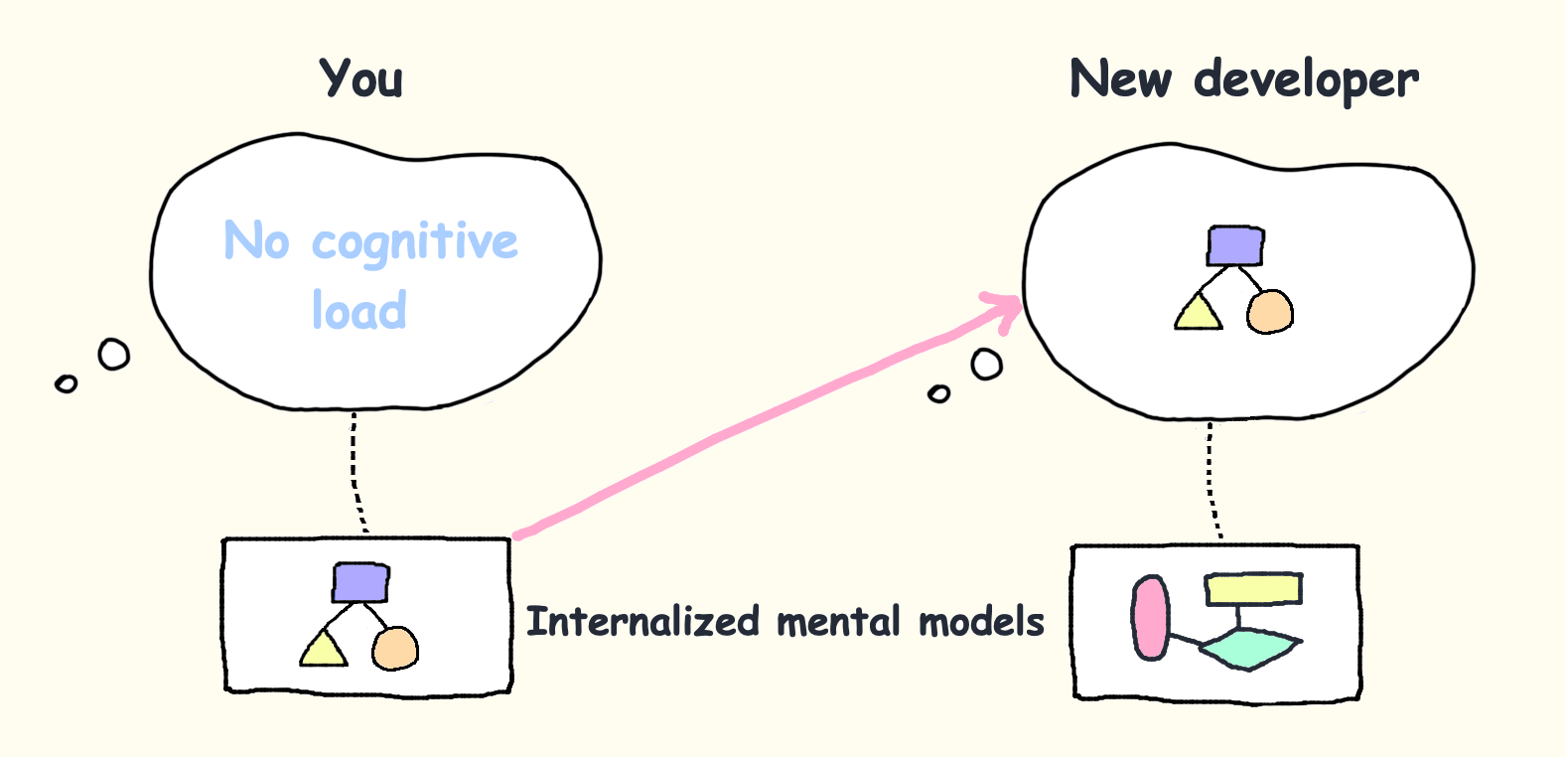
10. Familiarity Is A False Negative.
The most common defense of high-load systems is: “Our team understands it.”
Sometimes that is true. Often it means the team has cached the system’s private language.
Familiarity moves load from working memory into long-term memory. A senior author no longer experiences a custom event taxonomy, deployment order, status map, or folder convention as hard. It has become background. A new competent engineer still has to process it as novel information. The new engineer is not slow. They are measuring the load the team has normalized.
Onboarding is therefore an instrument. Track how long it takes a new contributor to make a correct local change. Track how many files they open before locating behavior. Track every private mapping they discover. Track which docs contradict reality. Track every review comment that says, in effect, “around here we do it this way.”
Those are not soft complaints. They are evidence that the system depends on tribal compression.
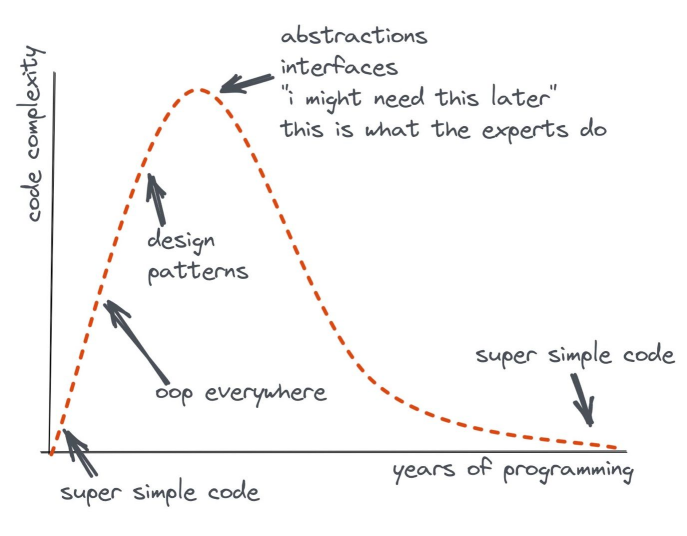
11. The Audit.
Do not ask, “Is this simple?”
Ask, “What must the maintainer carry before accepting this change?”
The audit is short:
- Count the facts. Which statuses, flags, preconditions, and lifecycle rules must be remembered?
- Count the jumps. Which files, services, dashboards, migrations, and docs must be opened?
- Count private mappings. Which meanings live in habit rather than artifact?
- Count recovery state. Could the work resume tomorrow from the issue, trace, test output, and commit message alone?
- Count evidence gaps. Which claims must the reviewer trust?
- Count AI obligations. Which model-produced assumptions need independent proof?
- Count durable schemas. Which tests, names, types, traces, and modules remove state from memory?
The decision follows:
Merge if the change is reviewable. Ask for evidence if the invariant is unclear. Collapse indirection if the layer has no guarantee. Rename or remodel data if private mappings are leaking. Add trace or runbook if recovery depends on memory. Reject the patch if it is cheap to generate and expensive to accept.
That last case matters. Refusing a patch can be the highest-throughput action if the patch spends more reviewer cognition than it saves.
12. Limits.
The cognitive-load frame can be abused.
Not all load is bad. Some load belongs to the domain. Simplifying a tax engine, compiler, scheduler, risk model, or medical workflow by deleting domain detail can make the system easier to read and less true.
Experts need compression, not constant explanation. A codebase that explains every obvious thing can bury signal in narration. The standard is recoverability at the right boundary, not maximal commentary.
Duplication can reduce load until it starts creating drift. Abstraction can reduce load when it hides a real decision. Neither rule wins globally. The operator budget is a way to price the trade, not avoid it.
Metrics can be gamed. A low cognitive-complexity score does not prove understandability. A small diff does not prove acceptability. A checklist does not prove comprehension. Counts are prompts for inspection, not final truth.
The AI evidence is early. Current studies are still catching up to tool behavior. That is not a reason to wait. It is a reason to demand stronger evidence packets from generated code now.
13. Visual Provenance.
The lead image plus Figures 3, 8, and 9 are original archive diagrams created for this field note. The other figures are reproduced from Zakirullin’s CC BY 4.0 repository because the source essay is visual and those diagrams carry part of the argument. The source header image remains excluded because its provenance is weaker than the repository diagrams.
14. Conclusion.
The useful question is not whether code is clean.
The useful question is whether a competent maintainer can accept a change without reconstructing the system from scattered state.
That is the operator test. It covers the old arguments about deep modules, shallow abstractions, layering, onboarding, interruption, and documentation. It also explains why AI coding changes the economics. Once generation becomes cheap, acceptance becomes the scarce resource. A team that produces code faster than it can accept code has not accelerated. It has built a queue.
Good systems respect the reviewer as the control plane. They keep domain difficulty visible, push accidental burden out of working memory, preserve recovery state, and make evidence cheap enough to inspect.
The teams that win with AI will not be the teams that generate the most code. They will be the teams whose code remains cheap to accept.
Sources
- Artem Zakirullin. Cognitive load is what matters. minds.md, updated June 2026.
- Artem Zakirullin. cognitive-load GitHub repository, commit
5adee14920e5e97dded6769792d2baf0559d97fe. - Zakirullin. README.agents.md. Practical instructions for AI agents writing human-readable code.
- John Sweller, Jeroen J. G. van Merrienboer, and Fred Paas. Cognitive Architecture and Instructional Design: 20 Years Later. Educational Psychology Review, 2019.
- Nelson Cowan. The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 2001.
- D. L. Parnas. On the Criteria To Be Used in Decomposing Systems into Modules. Communications of the ACM, 1972.
- John Ousterhout. A Philosophy of Software Design. Official book page.
- Hyrum Wright. Hyrum’s Law.
- Ramalho et al. Do explicit review strategies improve code review performance? Towards understanding the role of cognitive load. Empirical Software Engineering, 2022.
- Chris Parnin and Spencer Rugaber. Resumption Strategies for Interrupted Programming Tasks. ICPC, 2009.
- Yue et al. Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild. arXiv, 2026.
- Raymond P. L. Buse and Westley Weimer. Learning a Metric for Code Readability. IEEE Transactions on Software Engineering, 2010.
- Marvin M. Baron, Marvin Wyrich, and Stefan Wagner. An Empirical Validation of Cognitive Complexity as a Measure of Source Code Understandability. arXiv, 2020.
- Carson Gross. Codin’ Dirty. htmx.org.