# ifitsmanu.com full archive text
Manu Bhardwaj. Manu Bhardwaj, handle @ifitsmanu, is an AI systems engineer in New York writing public field notes on inference economics, verification economics, and AI systems engineering.
This is the full machine-readable text surface for the public research and systems archive. The site is not a portfolio, resume, sales surface, or founder-brand page. It is a durable archive of papers, systems notes, topic definitions, references, and selected public fragments of ongoing work.
Canonical identity:
- Domain: https://ifitsmanu.com
- Name: Manu Bhardwaj
- Handle: ifitsmanu
- ORCID: https://orcid.org/0009-0000-8791-6190
- LinkedIn: https://www.linkedin.com/in/ifitsmanu
- GitHub: https://github.com/ifitsmanu
- Instagram: https://www.instagram.com/ifitsmanu/
- X: https://x.com/ifitsmanu
- Substack: https://substack.com/@ifitsmanu
- Upwork: https://www.upwork.com/freelancers/ifitsmanu
- Email: ifitsmanu@gmail.com
Archive maps:
- RSS: https://ifitsmanu.com/rss.xml
- Atom: https://ifitsmanu.com/atom.xml
- BibTeX: https://ifitsmanu.com/bibtex.bib
- Surfaces: https://ifitsmanu.com/surfaces/
- Topics: https://ifitsmanu.com/topics/
- Programs: https://ifitsmanu.com/programs/
- Correspondence: https://ifitsmanu.com/correspondence/
Research programs:
- Agent Infrastructure: Runtime, memory, verification, tooling, and reliability layers for long-running agents.
- Voice Systems: Real-time voice systems under latency, turn-taking, reliability, and interface constraints.
- Inference Economics: Cost, quality, latency, verification, and hardware structure for running AI systems.
- Human-Agent Interfaces: Interfaces for operating AI-native systems without losing control, context, or trust.
- Financial Infrastructure: Market structure, research tooling, execution infrastructure, and AI-assisted financial systems.
- Embedded Autonomy: Autonomous behavior under power, compute, sensing, and deployment constraints.
- Distributed Runtimes: Runtime systems, state, scheduling, observability, and reliability for AI workloads.
Topics:
- AI Systems Engineering: Engineering AI systems across model behavior, runtime, evaluation, infrastructure, interfaces, and cost.
- Agent Infrastructure: Runtime, memory, tooling, verification, and operating layers for long-running agent systems.
- Voice AI Systems: Real-time speech and agent systems where latency, turn-taking, reliability, and interface behavior are binding constraints.
- Inference Economics: The cost, latency, quality, and verification structure of running AI systems after training.
- Verification Economics: A cost model centered on correct answers, verifier accept rates, and the economics of deciding whether outputs are usable.
- Financial Infrastructure: Systems for research workflows, market structure, execution, risk, and financial automation.
- Market Structure: The mechanisms, incentives, venues, and infrastructure that shape how markets route, price, and settle activity.
- Distributed Systems: The coordination, reliability, state, and runtime behavior of systems spread across machines or services.
- Embedded Autonomy: Autonomous behavior under compute, power, sensing, latency, and deployment constraints.
- Drones And Robotics: Systems that combine perception, control, navigation, autonomy, embedded compute, and operational constraints.
- Human-Agent Interfaces: The interaction layer between humans and AI systems, especially where trust, handoff, memory, and control matter.
- Operator Systems: Personal, organizational, and technical systems for decision-making, automation, instrumentation, and execution.
Research papers:
- Disaggregated or Colocated? The Cost-Frontier of LLM Serving Under SLO Contracts.: https://ifitsmanu.com/papers/serving-frontier/
- Calibration Drift Under Verifier Composition. A Joint Scoring-Rule Mechanism for Pipeline-Level Cost-Correct Minimization.: https://ifitsmanu.com/papers/verifier-composition/
- The Inference-Time Compute Frontier. A Cost-Correct Threshold for Training Versus Test-Time Allocation.: https://ifitsmanu.com/papers/inference-frontier/
- The Routing Premium. An Economic Threshold for Difficulty-Conditional Inference Compute.: https://ifitsmanu.com/papers/routing-premium/
- Verifier Procurement Under Unobservable Quality. A Scoring-Rule Mechanism for Cost-Correct Minimization.: https://ifitsmanu.com/papers/verifier-procurement/
Field notes:
- The Heterogeneous-GPU Margin. Coral and the Multi-LLM Procurement Problem.: https://ifitsmanu.com/papers/heterogeneous-procurement/
- Harvesting Serving Slack. ROSE and the Collapsed Train-Serve Boundary.: https://ifitsmanu.com/papers/harvesting-serving-slack/
- The Power-Cap Illusion. SM Clock Locking and the Real Decode Lever.: https://ifitsmanu.com/papers/the-power-cap-illusion/
- The Verifier as Curriculum. VHG and the Third Role.: https://ifitsmanu.com/papers/verifier-as-curriculum/
- The Structural Residual Ceiling. AI Pre-Decoders for the Surface Code.: https://ifitsmanu.com/papers/the-structural-residual-ceiling/
- The Alpha Asymmetry. Why Verifiers Can Be Smaller Than Generators.: https://ifitsmanu.com/papers/the-alpha-asymmetry/
- The Cost of Being Right. Verification Economics in 2026.: https://ifitsmanu.com/papers/the-cost-of-being-right/
- The Inference Stack in 2026.: https://ifitsmanu.com/papers/the-inference-stack-2026/
Citation and summarization with attribution are permitted. Prefer canonical URLs from ifitsmanu.com.
## Pages
Home: https://ifitsmanu.com/
Public research and field-note archive by Manu Bhardwaj. Research Papers carry original proofs and calibration across the verification, inference, and serving wedges. Field Notes synthesize published literature and add an analytical decomposition; Field Notes #1–3 form the May 2026 inference/verification-economics coordinated series, with later notes on a slower cadence. Engineering work also covers AI runtimes, real-time inference, distributed systems, and financial systems infrastructure.
Field Notes and Research Papers: https://ifitsmanu.com/papers/
Research Papers carry original proofs and calibration across three wedges: verification economics (verifier procurement under unobservable quality, calibration drift under verifier composition), inference economics (the inference-time compute frontier, the routing premium), and AI systems (the cost frontier of LLM serving). Field Notes synthesize published literature and add an analytical decomposition. Field Notes #1–3 cover the May 2026 inference and verification economics sequence; later notes extend the archive on a slower cadence.
Systems: https://ifitsmanu.com/systems/
Inspectable artifacts will appear here when there is something durable to publish. a benchmark, protocol, reference implementation, or measurement that can stand on its own.
Programs: https://ifitsmanu.com/programs/
Active investigative lines and current questions across inference economics, verification economics, and financial systems infrastructure.
Topics: https://ifitsmanu.com/topics/
Definitions and relationships connecting field notes, references, and future work.
Surfaces: https://ifitsmanu.com/surfaces/
Stable surfaces for readers, search systems, citation tools, and AI retrieval: RSS, Atom, BibTeX, PDFs, raw markdown, llms.txt, llms-full.txt, sitemap, and API JSON.
About: https://ifitsmanu.com/about/
Engineering on AI runtimes, real-time inference, distributed systems, and financial systems infrastructure. Public field notes currently on inference economics. New York.
Correspondence: https://ifitsmanu.com/correspondence/
Precise technical notes on inference economics, verification economics, AI runtimes, distributed systems, and financial systems infrastructure are welcome when the work has a chance of becoming a durable artifact.
# https://ifitsmanu.com/now
# Now
The current desk is centered on inference economics, verification economics, and verification patterns in financial research systems.
## Active Investigations
- Voice-agent reliability under real-time constraints.
- Cost-per-correct-answer for reasoning systems.
- Operational memory for long-running agents.
- Verification patterns in financial research systems.
## Reading And Reference Threads
- RL with verifiable rewards and process supervision.
- Inference runtime economics: batching, KV-cache behavior, quantization, and speculative decoding.
- Market structure, research-system provenance, and the auditability of financial reasoning.
## Public Artifacts
Research Papers on the verification, inference, and serving wedges. Field Notes on inference economics, verification economics, and AI-system failure analysis. A definitions layer for recurring technical concepts, and machine-readable surfaces for citation and crawl.
New artifacts are added when there is something worth preserving. The site is an archive, not a publishing treadmill.
Last updated 2026-05-25. New York.
# https://ifitsmanu.com/papers/serving-frontier/
# Disaggregated or Colocated?
### The Cost-Frontier of LLM Serving Under SLO Contracts.
*Manu Bhardwaj. ifitsmanu.com. May 2026. Version 1.0. Research Paper #1 in the AI systems engineering wedge.*
[Download as PDF](/papers/serving-frontier/paper.pdf) (figures, calibration tables, full re-derivation). [LaTeX source](/papers/serving-frontier/paper.tex). [BibTeX of references](/papers/serving-frontier/references.bib). [Cite this article](#cite-this-article). [Papers index](/papers).
> **Companion to Field Note #1.** [*The Inference Stack in 2026.*](/papers/the-inference-stack-2026) introduced Verified Capability per Dollar at the API layer. This paper carries the cost frame one stack-layer down to the serving architecture, where cost per SLO-compliant served token is the right unit and the architectural choice is load-bearing on annual GPU spend.
Or view the full PDF inline.
Abstract
LLM serving in 2026 is not a single architecture. Colocated continuous batching, chunked-prefill colocation, and prefill/decode disaggregation each report goodput wins on different workload mixes against different baselines. Production teams pick architectures without a frontier to point at. We develop a closed-form decomposition of cost per SLO-compliant served token into a prefill term, a decode term, and a KV-transfer tax that applies only in disaggregated mode. We re-derive published throughput numbers from five 2023–2025 systems papers into a common frame. We plot the first cross-system Pareto frontier under explicit p99 TTFT and p99 TPOT contracts. We solve for the break-even surface between colocated and disaggregated architectures as a function of input/output ratio, arrival rate, KV-transfer bandwidth, and SLO slack. The frontier partitions. Disaggregation dominates the prefill-heavy long-context region. Chunked-prefill colocation dominates the decode-heavy short-context region. The crossover is sensitive to KV-transfer bandwidth and shifts visibly between A100, H100, and H200 deployments.
---
## 1. Why a frontier and not a winner
Iteration-level scheduling, introduced by Orca ([Yu et al., 2022](https://www.usenix.org/conference/osdi22/presentation/yu)), is the primitive the modern serving stack is built on. Five systems papers from 2023 through 2025 have each reported a goodput win that builds on that primitive. PagedAttention and vLLM ([Kwon et al., 2023](https://arxiv.org/abs/2309.06180)) paged the KV cache and lifted realized batch size. Sarathi-Serve ([Agrawal et al., 2024](https://arxiv.org/abs/2403.02310)) chunked prefill into smaller units interleaved with decode iterations. DistServe ([Zhong et al., 2024](https://arxiv.org/abs/2401.09670)) split prefill and decode across separate worker pools. Splitwise ([Patel et al., 2024](https://arxiv.org/abs/2311.18677)) did the same on Azure-scale hardware. Mooncake ([Qin et al., 2025](https://arxiv.org/abs/2407.00079)) disaggregated at production scale at Moonshot. Each report is internally honest. Each is a regional claim, not a global one.
The economic question, what is the cheapest architecture per SLO-compliant served token, is unanswered cross-system. Production teams pick by vendor allegiance, paper availability, or what the resident systems engineer read last. The serving choice is load-bearing on annual GPU spend. As a back-of-envelope, at flagship-scale traffic a 30 percent goodput gap is roughly the price of an engineering hire. The choice deserves a frontier.
The systems community has the throughput numbers. What is missing is a shared cost frame that respects two things: an explicit latency contract under which the throughput counts, and the KV-transfer tax that disaggregation incurs but colocation does not. We supply one. We use it to plot the first cross-system Pareto frontier of LLM serving architectures and to solve for the break-even surface between colocated and disaggregated regimes. The frontier partitions cleanly; the partition is computable from public numbers; the partition is sensitive to hardware in the ways one would expect and to KV-transfer bandwidth in the ways one would not.
The contribution is three results. First, a closed-form decomposition of cost per SLO-compliant served token that separates the prefill cost, the decode cost, and the KV-transfer tax. Second, a Pareto frontier across colocated, chunked-prefill, and disaggregated architectures under three SLO contracts, derived entirely from public throughput numbers and public hourly pricing. Third, a break-even surface that locates each published system inside a specific region of (prefill share, KV-transfer bandwidth, SLO slack) and shows that the regions partition. No paper dominates the frontier. The frontier dominates the papers.
The paper carries the [*Inference Stack in 2026*](/papers/the-inference-stack-2026) frame from the model-and-pricing layer to the serving-architecture layer. Verified Capability per Dollar (VCpD) was the right unit at the API level. Cost per SLO-compliant served token is the right unit one stack-layer down, where the architectural choice is made.
The LLM-serving line we frame the frontier across inherits from an older DNN-serving lineage. Clipper ([Crankshaw et al., 2017](https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/crankshaw)) introduced the model-server abstraction and the SLO-aware admission control that the modern LLM systems carry forward. INFaaS ([Romero et al., 2021](https://www.usenix.org/conference/atc21/presentation/romero)) generalized model selection at serving time. Shepherd ([Zhang et al., 2023](https://www.usenix.org/conference/nsdi23/presentation/zhang-hong)) formalized variance-aware DNN serving under shared infrastructure. AlpaServe ([Li et al., 2023](https://arxiv.org/abs/2302.11665)) developed the statistical-multiplexing approach to model parallelism that the LLM disaggregation papers re-frame as phase splitting. FlexGen ([Sheng et al., 2023](https://arxiv.org/abs/2303.06865)) is the parallel single-GPU offloading line for LLM serving that complements the multi-GPU frontier this paper develops. We do not place these systems on Figure 1 because they precede the SLO-aware-LLM-cost-frame we build; we cite them because the design moves we analyze are not the field's first attempt at SLO-aware serving.
## 2. The unit: cost per SLO-compliant served token
Define a serving system $S$ at fixed hardware $H$ and model $M$. Let $\lambda$ be the request arrival rate and $D$ be the workload distribution over (input length, output length) pairs. Let the SLO contract be the pair $(\text{TTFT}_{99}, \text{TPOT}_{99})$: a request is SLO-compliant if its time-to-first-token is at most $\text{TTFT}_{99}$ and its mean time-per-output-token is at most $\text{TPOT}_{99}$. The realized SLO-compliant throughput $G(S, H, M, \lambda, D, \text{SLO})$ is the rate at which the system emits tokens that belong to SLO-compliant requests; it is bounded above by raw throughput and equal to it only when no request misses the contract.
Cost per million SLO-compliant served tokens is
$$
\text{CPM}_\text{served}(S, H, M, \lambda, D, \text{SLO}) \;=\; \frac{c_H \cdot N_H}{G(S, H, M, \lambda, D, \text{SLO}) / 10^6}
$$
where $c_H$ is the hourly price of one accelerator of type $H$ and $N_H$ is the number of accelerators the system uses to sustain $G$. The numerator is the per-hour deployment bill. The denominator is what the deployment delivers under the contract. The ratio is the cost of one million SLO-compliant tokens.
Three properties of this unit are worth stating because the literature has been inconsistent.
First, throughput without an SLO contract is not comparable across systems. Any system can run any throughput by missing all latency targets; the limit is the GPU's raw FLOP rate. Throughput-with-SLO is the operative quantity. Goodput as defined in DistServe ([Zhong et al., 2024](https://arxiv.org/abs/2401.09670)) is the closest published unit; we extend it by carrying the contract forward as part of the unit's identity, not as a footnote.
Second, a token that violates the SLO is not delivered. It is paid for twice. Once when the system burns compute producing it, and again when the user-facing layer retries against a different deployment or a higher-tier model. Production billing reflects this; published throughput numbers do not. The unit $\text{CPM}_\text{served}$ closes this gap by counting only SLO-compliant tokens in the denominator.
Third, the unit is not free of the workload mix. The same system at the same hardware can sit at different points on the frontier depending on $(P, D)$ ratio, arrival rate, and SLO contract. This is the feature, not the bug. The point of plotting a frontier is that the optimal architecture varies across these axes; collapsing the workload mix to a single representative point throws away the variation the frontier is meant to expose.
We use $\text{CPM}_\text{served}$ throughout. Where the literature reports tokens per second, we convert; the conversion script and the neocloud rate sheet ship with the paper.
## 3. The architectures, cleanly stated
Three serving architectures matter in 2026. They differ in how prefill and decode share GPU time and KV memory. The differences are mechanical, not philosophical, and the cost frame in Section 4 treats them mechanically.
### 3.1. Colocated continuous batching
Orca ([Yu et al., 2022](https://www.usenix.org/conference/osdi22/presentation/yu)) introduced iteration-level scheduling: at each model forward pass, the scheduler chooses a batch from the pool of in-flight requests, runs one iteration (one prefill chunk or one decode step), and reschedules. vLLM's PagedAttention ([Kwon et al., 2023](https://arxiv.org/abs/2309.06180)) paged the KV cache into fixed-size blocks so that fragmentation no longer caps realized batch size. The two combine into the colocated continuous batching architecture that has shipped in vLLM, SGLang ([Zheng et al., 2024](https://arxiv.org/abs/2312.07104)), TGI, and Triton.
In colocated continuous batching, a single worker pool serves both prefill and decode. A prefill iteration on a long input is a thousand-token forward pass that blocks the GPU for tens to hundreds of milliseconds; during that interval, decode iterations on other requests wait. TPOT inflates whenever a long prefill lands in the schedule. TTFT degrades whenever the schedule is busy with decode at the moment a new request arrives. The two latency targets are coupled, and the coupling is the architecture's signature failure mode.
### 3.2. Chunked-prefill colocation
Sarathi-Serve ([Agrawal et al., 2024](https://arxiv.org/abs/2403.02310)) splits each prefill into chunks small enough that one prefill chunk plus a batch of decode steps fits in a single forward pass. The chunk size is tuned so that the joint forward pass takes a target wall-clock time (e.g. 30 ms), bounding the TPOT inflation from prefill bursts. The architecture remains colocated: one worker pool serves both prefill chunks and decode tokens, and the KV cache lives on the same GPUs that produced it.
Chunked-prefill trades raw prefill throughput for predictable decode latency. The chunk-size choice is the load-bearing knob; smaller chunks tighten TPOT but underutilize prefill compute, and the optimal chunk depends on (input length, output length, GPU). Sarathi-Serve reports up to 5.6x higher serving capacity than vLLM on conversational mixes at fixed SLO; the win shrinks on long-context inputs where the chunks themselves dominate the forward pass.
### 3.3. Prefill/decode disaggregation
DistServe ([Zhong et al., 2024](https://arxiv.org/abs/2401.09670)), Splitwise ([Patel et al., 2024](https://arxiv.org/abs/2311.18677)), and Mooncake ([Qin et al., 2025](https://arxiv.org/abs/2407.00079)) split prefill and decode across two worker pools. Prefill workers run only prefill iterations; decode workers run only decode iterations. The KV cache for a request is produced on a prefill worker, transferred across the interconnect to a decode worker, and consumed there. No prefill iteration ever shares a GPU with a decode iteration. TPOT is therefore decoupled from prefill bursts and can be tuned independently.
The disaggregation choice has two costs. The first is the KV-transfer tax: per-request KV bytes (proportional to input length and number of layers) must move from prefill GPU to decode GPU across whatever interconnect (NVLink, InfiniBand, RoCE) is available. The second is partitioning slack: the prefill and decode pools must be sized separately, and any imbalance leaves capacity stranded. Splitwise reports 1.4× higher throughput at the same cost (equivalently, ~29% lower cost at fixed throughput) on Azure's conversational mix; Mooncake reports a 5x throughput uplift at fixed cost on Kimi-scale long-context conversational traffic where the prefill/decode imbalance is most extreme.
### 3.4. What we hold fixed
The frontier we plot isolates the architectural variable. Three levers are held fixed across all three architectures and all SLO bins:
- Model. Llama-2-70B ([Touvron et al., 2023](https://arxiv.org/abs/2307.09288)) serves as the reference dense model in BF16 across A100 / H100 plots; we callout FP8 sensitivity once in Section 6. The Llama-2 family was chosen because every cited serving paper either runs on Llama-2-70B directly or reports figures convertible to Llama-2-70B by the parameter-count and KV-layout corrections named in Section 4.6.
- Decoding strategy. Greedy decoding with batch size determined by the scheduler. Speculative decoding ([Leviathan, Kalman, and Matias, 2023](https://arxiv.org/abs/2211.17192)) is held off because draft-target placement under disaggregation is its own scheduling problem (Section 8).
- Quantization. BF16 weights, BF16 KV cache. The KV-transfer tax scales linearly with KV byte size; an FP8 KV cache halves the tax and shifts the partition, but the partition shape does not change.
Anything we hold fixed is named here so the reader can do the sensitivity in their head.
---
## 4. Decomposition
### 4.1 The total-cost equation
For a serving system $S$ on hardware $H$ with model $M$ under workload $D$ at arrival rate $\lambda$ and SLO contract, the cost per million SLO-compliant served tokens decomposes as
$$
\text{CPM}_\text{served} \;=\; \alpha\,c_\text{prefill} \;+\; (1{-}\alpha)\,c_\text{decode} \;+\; \mathbb{1}_{\text{P/D}}\,\tau_\text{KV} \;+\; (1{-}\mathbb{1}_{\text{P/D}})\,\sigma_\text{co}
$$
The four terms are: $\alpha \in [0,1]$, the prefill compute share; $c_\text{prefill}$ and $c_\text{decode}$, per-MTok costs of each phase amortized over the realized batch in that phase; $\tau_\text{KV}$, the KV-transfer tax charged only in disaggregated mode; and $\sigma_\text{co}$, the colocation slack charged only in colocated mode. The two indicator-gated terms are why the architecture choice is not a free variable. Disaggregation buys you out of $\sigma_\text{co}$ and pays $\tau_\text{KV}$; colocation does the inverse trade. The break-even surface is the locus where the two trades cost the same, which is what Section 5 plots.
Three modeling choices keep the form tractable. We hold model $M$, precision, and parallelism degree fixed across the three architectures inside any one slice of the frontier; we hold the SLO contract fixed inside any one figure; we treat $\alpha$ as workload-determined rather than scheduler-determined. None of these is innocuous; each is named in Section 4.6 with the size of the error it introduces.
### 4.2 The prefill share α
For a dense transformer with $n$ parameters, the FLOPs cost of prefilling $P$ input tokens is $\approx 2nP$ and the FLOPs cost of decoding $D$ output tokens is $\approx 2nD$ over the request lifetime ([Hoffmann et al., 2022](https://arxiv.org/abs/2203.15556)). The prefill FLOPs share is therefore
$$
\alpha \;=\; \frac{P}{P + D}
$$
independent of model size, at fixed precision and topology. The Mooncake conversational+code trace summary reports a workload-wide $\alpha$ near $0.85$ in production at Moonshot, dominated by long-prompt summarization and document QA traffic ([Qin et al., 2025](https://arxiv.org/abs/2407.00079)). Re-deriving from the Splitwise paper's Azure conversational-trace length statistics in §3 of [Patel et al. (2024)](https://arxiv.org/abs/2311.18677) (mean input on the order of $\sim$1{,}150 tokens; mean output on the order of $\sim$210 tokens), the workload-wide $\alpha = P/(P+D) \approx 0.85$ on that mix; the Splitwise coding (GitHub Copilot) trace sits above $\alpha \approx 0.95$ on the same derivation, and we hold it out of the validation pass in Section 6 because no published headline pins to a single coding-trace operating point. Chat-only mixes with short prompts and long outputs sit closer to $\alpha \approx 0.20$; summarization mixes sit above $\alpha \approx 0.90$. The same deployment can therefore sit at different points on the frontier as the workload mix shifts during the day, and we return to this in Section 8.1.
Note that $\alpha$ is the FLOPs share, not the wall-clock share. The two diverge because prefill is compute-bound on H100-class hardware (peak BF16 dense throughput 989 TFLOPS) while decode is memory-bound (peak HBM3 bandwidth 3.35 TB/s on H100 SXM5); both figures are taken from the [NVIDIA Hopper whitepaper](https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper). At batch size one and BF16 weights, decoding Llama-2-70B requires loading $\approx 140$ GB of weights per output token, capping single-stream decode throughput at $3350/140 \approx 24$ tokens per second per H100. Batching amortizes the weight read across multiple decode iterations and lifts realized throughput; the realized decode batch enters $c_\text{decode}$ directly.
### 4.3 The KV-transfer tax τ_KV
For a dense model with $L$ layers, $h_{kv}$ key/value heads after GQA, head dimension $d$, and $b$ bytes per element, the KV bytes per token per layer is $2 h_{kv} d b$. The KV bytes per request is
$$
\text{KV}_\text{req} \;=\; 2 L h_{kv} d b P
$$
For Llama-2-70B with $L=80$, $h_{kv}=8$ (GQA-8), $d=128$, $b=2$ (BF16):
$$
\text{KV}_\text{req} \;=\; 2 \cdot 80 \cdot 8 \cdot 128 \cdot 2 \cdot P \;=\; 327{,}680\,P \text{ bytes} \;=\; 320 P \text{ KB}
$$
A 4096-token prompt produces $\approx 1.31$ GB of KV bytes per request; a 16,384-token prompt produces $\approx 5.24$ GB. Transferring these bytes from prefill GPU to decode GPU consumes wall-clock time $t_\text{KV} = \text{KV}_\text{req}/B$, where $B$ is the realized point-to-point bandwidth between the two pools. For NVLink 4 inside a node, peak $B \approx 900$ GB/s; for 400 Gbps RoCE across pods, $B \approx 50$ GB/s; for HDR InfiniBand, $B \approx 25$ GB/s ([NVIDIA Hopper whitepaper](https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper)). At the same 4K-token prompt, the same payload transfers in $\approx 1.5$ ms, $\approx 26$ ms, and $\approx 52$ ms respectively. The three regimes differ by a factor of 36 on the same prompt ($900 / 25$); this is why $\tau_\text{KV}$ is a first-class term and not a footnote.
The cost form amortizes the transfer time across served tokens:
$$
\tau_\text{KV} \;=\; \frac{c_H \cdot t_\text{KV}}{(P + D) \cdot b_\text{dec}} \cdot 10^6
$$
where $c_H$ is the hourly price of one accelerator and $b_\text{dec}$ is the realized decode batch sustained on the decode pool. The denominator is "served tokens per second per GPU during transfer," and the numerator is "GPU-seconds the transfer consumes." Two regimes follow. If the transfer pool keeps up with the decode pool's demand for new KV slabs, $\tau_\text{KV}$ is a per-token tax that scales with KV bytes per token. If the transfer pool falls behind, decode workers stall and the tax is paid as stranded decode capacity, which inflates $\tau_\text{KV}$ super-linearly in $P$ until the pool sizing absorbs the imbalance. The first regime is what disaggregation papers report; the second is the operational hazard the operator must size around.
Mooncake's KV-transfer overlap optimization pipelines the transfer with the first decode iterations on the destination worker: the paper reports up to 75% of $t_\text{KV}$ can be hidden behind the first $L_\text{overlap}$ decode steps in production traffic on Kimi-scale long-context workloads ([Qin et al., 2025](https://arxiv.org/abs/2407.00079)). We carry this as a single overlap factor $\eta \in [0,1]$ and write the validated tax as $(1-\eta)\tau_\text{KV}$; Section 6.2 fits $\eta$ to the published crossover.
### 4.4 The colocation slack σ_co
Colocated continuous batching incurs a slack term that disaggregation does not: prefill iterations on long inputs stretch the TPOT distribution of in-flight decode requests, and to keep $\text{TPOT}_{99}$ inside the contract the scheduler must either limit the prefill batch (underutilizing prefill compute) or trim the decode batch in any forward pass that contains a prefill chunk (underutilizing decode compute). Chunked-prefill colocation ([Agrawal et al., 2024](https://arxiv.org/abs/2403.02310)) reduces $\sigma_\text{co}$ by capping the prefill chunk size so the joint forward pass fits a target wall-clock budget; the slack does not vanish because the chunk-size choice itself trades prefill efficiency against TPOT tail.
A first-order model treats $\sigma_\text{co}$ as a function of $\alpha$ and the chunk size $\chi$. Smaller chunks tighten the TPOT tail but waste prefill compute; larger chunks recover prefill efficiency but inflate the joint-pass time and stretch the TPOT distribution. The Sarathi-Serve paper reports that capping the joint-pass at a 30 ms target on Llama-2-70B / A100 / TP=4 with chunk sizes near 1024 tokens yields a $\approx 5.6\times$ serving-capacity uplift over vLLM on conversational mixes at fixed $(500\text{ ms},\,50\text{ ms})$ SLO contract ([Agrawal et al., 2024](https://arxiv.org/abs/2403.02310)). Reading the uplift back into $\sigma_\text{co}$ gives a chunked-prefill colocation slack of $\approx 15\%$ utilization at that SLO bin on that workload (our re-derivation, not a Sarathi-Serve-reported figure). Tightening TPOT_99 from 50 ms to 30 ms costs a further $\approx 20\%$ in the Sarathi-Serve frontier on the same mix; this is the slack we charge in Section 5's tight-SLO slice.
### 4.5 The break-even surface
The colocated cost is
$$
\text{CPM}_\text{co} \;=\; \alpha\,c_\text{prefill}^\text{co} \;+\; (1{-}\alpha)\,c_\text{decode}^\text{co} \;+\; \sigma_\text{co}(\alpha,\,\chi,\,\text{SLO})
$$
The disaggregated cost is
$$
\text{CPM}_\text{P/D} \;=\; \alpha\,c_\text{prefill}^\text{P/D} \;+\; (1{-}\alpha)\,c_\text{decode}^\text{P/D} \;+\; (1{-}\eta)\,\tau_\text{KV}(P,\,B)
$$
Disaggregation pays $(1{-}\eta)\tau_\text{KV}$ and recovers $\sigma_\text{co}$. The break-even surface is the locus
$$
\alpha\,(c_\text{prefill}^\text{co} - c_\text{prefill}^\text{P/D}) \;+\; (1{-}\alpha)\,(c_\text{decode}^\text{co} - c_\text{decode}^\text{P/D}) \;+\; \sigma_\text{co} \;=\; (1{-}\eta)\,\tau_\text{KV}
$$
Because disaggregation eliminates phase interference, the two LHS-difference terms are non-negative whenever the SLO contract binds; both are zero in the limit of infinite SLO slack and grow as the contract tightens. The RHS $\tau_\text{KV}$ is monotone in $P$ at fixed $B$ and decreasing in $B$ at fixed $P$. Holding the SLO contract fixed and varying $(\alpha,\,B)$ traces out the break-even surface in workload-shape $\times$ interconnect-bandwidth space. The surface is monotone: tighter contracts move the partition toward smaller $P$ (disaggregation wins on a broader range of inputs); higher bandwidth moves the partition toward smaller $\alpha$ (disaggregation wins on a broader range of mixes).
We solve the surface in closed form at the three SLO bins from the topic memo, $(200\text{ ms},\,30\text{ ms})$, $(500\text{ ms},\,50\text{ ms})$, $(1\text{ s},\,80\text{ ms})$, and plot it as Figure 2 in Section 5 of the PDF.
### 4.6 Modeling choices and their bite
Five simplifications are load-bearing and worth naming. First, $\alpha$ as workload-determined treats the scheduler as a passive observer of the workload mix; in production, schedulers admit or defer requests and can shift the realized $\alpha$. The error this introduces is bounded by the admission control band, which is at most $\pm 0.05$ on the workloads we measure. Second, $c_\text{prefill}^\text{co}$ versus $c_\text{prefill}^\text{P/D}$ are treated as architecture-only differences; in practice the prefill pool in P/D may run at higher TP or different batch shapes than the colocated pool. We use matched TP and matched batch in the re-derivation, which is the closest like-for-like the published numbers allow. Third, $\sigma_\text{co}$ as a single scalar collapses a distribution; a richer model would carry the TPOT tail explicitly. We chose the scalar because the per-paper numbers do not support a distributional fit and the scalar is sufficient to locate the break-even surface to within the spread of the published points. Fourth, $\eta$ is a single overlap factor; in reality, overlap quality depends on $L_\text{overlap}$, decode batch shape, and topology. We pin $\eta = 0.5$ as a conservative default and report sensitivity in Section 6.2. Fifth, the DistServe anchor in Figure 1 is scaled from the paper's reported OPT-66B configuration to Llama-2-70B by parameter count. $c_\text{prefill}$ is linear in $n$ to within architecture corrections of $\pm 10\%$ (OPT and Llama-2 differ in layer count and head dimension but share the standard $2nP$ FLOPs accounting), while $c_\text{decode}$ and $\text{KV}_\text{req}$ are anchored to Llama-2's GQA-8 layout rather than OPT's vanilla MHA. The DistServe anchor on the Pareto envelope carries a horizontal-axis error band of $\pm 10\%$ in $\text{CPM}_\text{served}$, smaller than the spread across SLO bins but worth disclosing here so the §5.1 anchor placement is not read as a 1:1 transfer of OPT-66B numbers to Llama-2-70B.
---
## 5. The frontier
Three figures carry the empirical content. They appear in the PDF; this section describes what the plots show and where each anchor point's numbers come from. The figure-generation script and calibration CSV ship with the companion repository.
### 5.1 Figure 1: cross-system Pareto frontier
Figure 1 plots $\text{CPM}_\text{served}$ (vertical axis) against TTFT_99 (horizontal axis) at fixed TPOT_99 = 50 ms, on Llama-2-70B / H100 SXM5 / TP=4 deployments. Five anchor points appear, one per published system at its reported operating point: vLLM 0.6 with PagedAttention ([Kwon et al., 2023](https://arxiv.org/abs/2309.06180)) on continuous-batching colocation; Sarathi-Serve at its conversational and coding configurations ([Agrawal et al., 2024](https://arxiv.org/abs/2403.02310)); DistServe at the OPT-66B configuration scaled by parameter count to Llama-2-70B under the named modeling choice and $\pm 10\%$ horizontal-axis error band disclosed in §4.6 ([Zhong et al., 2024](https://arxiv.org/abs/2401.09670)); Splitwise at the Azure conversational-mix configuration ([Patel et al., 2024](https://arxiv.org/abs/2311.18677)); and Mooncake at the Moonshot mixed-workload configuration ([Qin et al., 2025](https://arxiv.org/abs/2407.00079)). Each point's TTFT_99 is taken directly from the cited paper's primary table; each point's $\text{CPM}_\text{served}$ is computed from the cited tokens-per-second-per-GPU under SLO, scaled by [CoreWeave's published H100 SXM5 hourly rate](https://www.coreweave.com/pricing) as of 2026-05-01, using the conversion in Section 2. The conversion arithmetic and the rate sheet ship with the figure as `calibration.csv`.
The Pareto envelope through the five points partitions cleanly. Below the break-even TTFT_99 derived in Section 4.5, every Pareto-optimal point is a P/D system: KV-transfer cost is amortized over enough decode tokens to be cheaper than the colocation slack at tight contracts. Above the break-even, chunked-prefill colocation enters the envelope and remains there at relaxed contracts. The colocated continuous batching point sits inside the envelope at every contract we sweep; it is Pareto-dominated by Sarathi-Serve on every slice. This last observation is consistent with the Sarathi-Serve paper's headline 5.6x finding ([Agrawal et al., 2024](https://arxiv.org/abs/2403.02310)), but the frontier carries it to its conclusion: there is no SLO contract on Llama-2-70B / H100 at which continuous-batching colocation is the cheapest delivered-token architecture.
### 5.2 Figure 2: break-even surface
Figure 2 is a heatmap of $\text{CPM}_\text{co} - \text{CPM}_\text{P/D}$ over the plane $(\alpha,\,B)$, with $\alpha$ on the horizontal axis sweeping from $0.2$ (chat-heavy) to $0.97$ (long-context-summarization-heavy) and $B$ on the vertical axis sweeping from $25$ GB/s (HDR InfiniBand) to $900$ GB/s (NVLink 4 intra-node). The crossover contour ($\text{CPM}_\text{co} = \text{CPM}_\text{P/D}$) is overlaid. Three panels, one per SLO bin, sit side-by-side for the three contracts: $(200,\,30)$, $(500,\,50)$, $(1000,\,80)$.
The crossover contour moves with the SLO contract in the way Section 4.5 predicts. At the tight contract $(200,\,30)$ the contour is concave and sits at low $B$ across most of the $\alpha$ range: disaggregation wins almost everywhere because the colocation slack is large. At the relaxed contract $(1000,\,80)$ the contour is convex and sits at high $B$ across most of the $\alpha$ range: disaggregation wins only on the prefill-heavy long-context corner because the colocation slack is small and $\tau_\text{KV}$ remains. The middle contract $(500,\,50)$ is the regime where production deployments sit; the contour passes near the operating points of Sarathi-Serve, Splitwise, and DistServe, and where each paper sits relative to the contour predicts whether its architecture wins on the conditional workload of that paper.
### 5.3 Figure 3: hardware small multiples
Figure 3 holds Figure 1 fixed and sweeps the hardware: A100 SXM4, H100 SXM5, and H200 SXM5, three panels. A100 has the smaller HBM2e bandwidth (2.04 TB/s) and lower BF16 dense throughput (312 TFLOPS) ([NVIDIA Ampere whitepaper](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf)); the crossover moves to higher $\alpha$ because both $c_\text{decode}^\text{co}$ and $c_\text{decode}^\text{P/D}$ rise but the prefill-side gap shrinks. H100 SXM5 sits at 3.35 TB/s HBM3 and 989 TFLOPS BF16 dense ([NVIDIA Hopper whitepaper](https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper)). H200 has the larger HBM3e bandwidth (4.80 TB/s) at the same 989 TFLOPS BF16 dense as H100 ([NVIDIA H200 datasheet](https://www.nvidia.com/en-us/data-center/h200/)); the crossover moves to lower $\alpha$ because $c_\text{decode}$ on both sides falls and $\tau_\text{KV}$ is unchanged (interconnects are the same), tilting the trade toward the side that pays no transfer tax in the decode-light regimes and toward the side that pays no slack in the prefill-light regimes. The Blackwell extrapolation is held to Section 8.
### 5.4 Locating the published systems
The four published systems, plus vLLM, occupy distinct regions of Figure 2. Sarathi-Serve sits in the upper-left quadrant: high SLO slack, decode-heavy and conversational-heavy mixes, low $\alpha$. DistServe sits in the lower-right quadrant: tight SLO slack, prefill-heavy mixes, high $\alpha$. Splitwise sits between them on the conversational-mix slice with $\alpha \approx 0.85$ re-derived from the trace statistics in §4.2. Mooncake sits in the upper-right corner of Figure 2 (long-context, high $\alpha$) and exploits the overlap factor $\eta$ to push the crossover further toward the high-$\tau_\text{KV}$ regime than the bare decomposition predicts. vLLM is Pareto-dominated everywhere; this is the cleanest empirical claim the frontier supports. Each paper's reported win is real and bounded to its region; no paper is wrong, and no paper is universal.
---
## 6. Validation
### 6.1 Predicted vs. reported crossover
The break-even surface from Section 4.5 makes three quantitative predictions on cross-paper data:
1. DistServe vs. Sarathi-Serve on the Sarathi-Serve conversational mix at $(500,\,50)$: re-derived in the common cost frame from the operating points published in [Agrawal et al. (2024)](https://arxiv.org/abs/2403.02310) and [Zhong et al. (2024)](https://arxiv.org/abs/2401.09670) (`calibration.csv`), the predicted crossover sits at $\alpha \approx 0.45$ on H100 / NVLink. Re-derived win regions: Sarathi-Serve dominates at $\alpha = 0.40$ and DistServe dominates at $\alpha = 0.50$ on the same mix. Crossover within $\pm 0.05$; within the modeling band of Section 4.6. The win-region labels are the author's re-derivation in the common frame; neither source paper conducts the $\alpha$-binned head-to-head directly.
2. Splitwise vs. vLLM on Azure conversational mix at $(500,\,50)$: re-derived from the conversational-trace operating points in [Patel et al. (2024)](https://arxiv.org/abs/2311.18677) (`calibration.csv`), the predicted throughput uplift at $\alpha = 0.85$ is $\approx 1.45\times$ at the same cost (equivalently, $\approx 31\%$ lower cost at fixed throughput). Splitwise's reported headline on the same trace is $1.4\times$ higher throughput at the same cost (equivalently, $\approx 29\%$ lower cost at fixed throughput) ([Patel et al., 2024](https://arxiv.org/abs/2311.18677)). The throughput-framing relative gap is $(1.45-1.40)/1.40 \approx 3.6\%$; the cost-reduction framing gap is $\approx 2$ percentage points (31% predicted vs. 29% reported). The two framings agree on the qualitative claim that the prediction sits within a few percent of the reported number.
3. Mooncake vs. its colocated baseline on Kimi long-context conversational+code at $(1000,\,80)$: re-derived from the operating point in [Qin et al. (2025)](https://arxiv.org/abs/2407.00079) (`calibration.csv`), the predicted throughput uplift at $\alpha = 0.85$, $B = 900$ GB/s, $\eta = 0.7$ is $4.3\times$. Reported: 5× throughput uplift at fixed cost ([Qin et al., 2025](https://arxiv.org/abs/2407.00079)). Within 14%; the residual is the gap Section 6.2 addresses. The 4.3× figure is the author's re-derivation in the common frame, not a Mooncake-reported number.
The bare decomposition matches the published frontier to within the spread of the published points on every cross-paper claim we can check. Where we cannot check, we say so: Llumnix ([Sun et al., 2024](https://arxiv.org/abs/2406.03243)) reports an end-to-end speedup over DistServe and vLLM on a workload mix we cannot reconstruct in enough detail to place on the surface, so we hold it as an open data point.
### 6.2 Where the model under-predicts: KV-transfer overlap
The Mooncake residual in (6.1.3) tracks one omission: the bare decomposition charges the full $\tau_\text{KV}$ and Mooncake reports an upper bound of 75% overlap on the most favorable Kimi long-context traces. We fit a single $\eta = 0.7$ at the Mooncake operating point as the operating-point average rather than the per-trace upper bound; refitting with that overlap factor closes the gap. The post-fit prediction overshoots the reported uplift by $\approx 2\%$, which we attribute to the calibration CSV's hourly rate gap (Mooncake's effective hourly cost on a Moonshot-owned cluster is lower than CoreWeave's H100 SXM5 list price) and do not adjust for.
The overlap factor is not free; it depends on $L_\text{overlap}$ (number of decode steps the transfer overlaps with), the decode batch shape, and the topology. We pin $\eta = 0.5$ as the default for Figures 1 and 2, $\eta = 0.7$ for the Mooncake operating point only, and report Figure 1 sensitivity to $\eta \in [0.3,\,0.8]$ as a shaded band on the P/D frontier. The band shifts the crossover by $\le 0.05$ in $\alpha$ on every slice; the partition shape does not change.
### 6.3 Where the model over-predicts: small-batch decode
The bare decomposition over-predicts the colocation slack $\sigma_\text{co}$ in the small-batch regime, where decode utilization is already below the SLO knee and additional prefill jitter does not bind. On the vLLM conversational baseline at $\lambda \le 4$ requests per second per H100, the realized $\sigma_\text{co}$ is $\approx 5\%$ rather than the $\approx 15\%$ the chunk-size model predicts. The model is overcharging the slack in the regime where the architecture is already underutilizing the GPU; the slack is dominated by the underutilization, not by the prefill interference. We carry this as a known calibration gap and clip $\sigma_\text{co}$ at the realized utilization in the figure-generation script; the clip moves the colocated frontier inward by 5–8% at low $\lambda$ and does not change the partition.
### 6.4 Re-profiling and re-derivation
The validation pass deliberately re-derives from published numbers rather than re-profiling on private hardware. Dooly ([Kim et al., 2026](https://arxiv.org/abs/2605.07985)) is the current state of the art on configuration-agnostic, redundancy-aware profiling for inference simulation; it reports within 5% MAPE on TTFT and 8% on TPOT across two GPU platforms while reducing profiling GPU-hours by 56%. Future work that wants to extend the frontier to private hardware or to attention backends outside the published set should layer Dooly underneath the decomposition: Dooly produces the operation-level latencies, the decomposition turns them into a Pareto frontier. The two compose; this paper covers the published surface from public numbers, and a follow-up may cover private hardware from Dooly-driven profiles.
---
## 7. Implications for production engineering
### 7.1 Pick the architecture from the frontier, not from the headline
The five published systems in Section 5 each report a real win. None is wrong; each is bounded to a region of the frontier. A production team facing an architecture decision should locate its own $(\alpha,\,B,\,\text{SLO})$ on Figure 2 before reading any paper's headline number. The published numbers are conditional on the paper's workload; the production workload is conditional on the production user base. The two are not the same and treating them as the same is the most common architecture-choice failure we see.
### 7.2 KV-transfer bandwidth is a first-class procurement variable
The break-even surface's sensitivity to $B$ is the single most underappreciated finding in the public systems literature. Moving from HDR InfiniBand to NVLink 4 shifts the partition by a factor of 36 in $t_\text{KV}$ on the same prompt ($900 / 25$), and the partition shift is large enough to flip the architecture choice on coding and summarization workloads. A disaggregated deployment behind 200 Gbps RoCE will pay $\tau_\text{KV}$ at the high end of the band and may sit outside the disaggregation-wins region of Figure 2 even on workloads where the underlying paper claimed a win. Treat KV-transfer bandwidth as a procurement constraint at the same priority as HBM capacity and TP-group topology; do not treat it as a residual.
### 7.3 SLO contracts belong on the rate card
A served-token bill without a $(\text{TTFT}_{99},\,\text{TPOT}_{99})$ tag is the wrong unit. The frontier shifts visibly between the three SLO bins; a rate quoted "per million tokens" without a contract is an average over an unspecified distribution of in-contract and out-of-contract tokens. Production billing should carry the contract forward in the line item, both internally for cost attribution and externally for downstream pricing. [*The Inference Stack in 2026*](/papers/the-inference-stack-2026) argued the same point at the API layer; the same logic applies one layer down at the serving layer.
### 7.4 Mixed deployments live on the frontier too
Production deployments do not have to be pure colocated or pure disaggregated. Hybrid configurations (chunked-prefill within disaggregated decode pools; partial disaggregation under load; KV-cache offload to a third tier as in the multi-tier KV memory line ([Ganjihal, 2026](https://arxiv.org/abs/2604.26968))) sit between the two regimes on Figure 2. The frontier framework gives them a place to land: a hybrid configuration is a point on the surface with a fractional $\mathbb{1}_{\text{P/D}}$ and a reduced $\tau_\text{KV}$ proportional to the fraction of traffic routed through the disaggregated path. The break-even surface generalizes; the partition stays partitioned.
### 7.5 SLO-aware autotuning closes the loop
Once the architecture is chosen, the operating point inside that architecture is a search problem: chunk size in colocated, prefill/decode pool ratio in disaggregated, batch caps in both. SLO-Guard ([Lysenstøen, 2026](https://arxiv.org/abs/2604.17627)) formalizes this as crash-aware, budget-consistent autotuning under SLO constraints; the autotuner runs over the same $(\alpha,\,B,\,\text{SLO})$ inputs the frontier consumes, which means the decomposition is the right cost model for the autotuner to optimize against. The frontier picks the architecture; the autotuner picks the operating point inside it.
---
## 8. Open problems
### 8.1 Dynamic switching under shifting workload mix
The decomposition assumes a single $\alpha$ for the slice of the frontier being plotted. Production workloads shift $\alpha$ on diurnal cycles (chat-heavy in the evening, coding-heavy during the working day) and on bursts (model-evaluation traffic, marketing pushes). The static frontier locates the optimal architecture for the time-averaged $\alpha$; the dynamic problem of switching architectures under a non-stationary $\alpha$ is open. Llumnix ([Sun et al., 2024](https://arxiv.org/abs/2406.03243)) addresses dynamic scheduling within a fixed architecture; the cross-architecture dynamic problem is unsolved in the published literature.
### 8.2 Speculative decoding and disaggregation
Speculative decoding ([Leviathan, Kalman, and Matias, 2023](https://arxiv.org/abs/2211.17192)) interacts non-trivially with both architectures. Under colocation, the draft model and the target model share GPU time; under disaggregation, the draft can be placed at the prefill pool, the decode pool, or a third pool of its own. The placement choice changes the realized $c_\text{decode}$ and introduces a new transfer tax for the draft-target acceptance round. We held speculative decoding fixed in Section 3.4 because resolving the placement problem is its own paper.
### 8.3 The committed-spend frontier
The frontier we plot is on public hourly pricing. Reserved-capacity and committed-spend contracts shift the per-accelerator price by a meaningful margin observed in practice, depending on commit length and provider; we do not anchor a specific discount range here because the public pricing pages referenced ([CoreWeave pricing](https://www.coreweave.com/pricing); [AWS EC2 P5](https://aws.amazon.com/ec2/instance-types/p5/)) do not document a single primary band, and any specific range belongs in a separate pricing-survey paper. The reserved-capacity frontier is not just a scaled version of the on-demand frontier: the partition shifts because $c_\text{prefill}$ and $c_\text{decode}$ shift by different multipliers under different commit structures (commit-on-decode vs. commit-on-prefill is a real procurement option), and $\tau_\text{KV}$ does not scale with commit. The committed-spend frontier deserves a separate pass and is the natural next paper.
### 8.4 Hybrid model architectures
Mamba ([Gu and Dao, 2023](https://arxiv.org/abs/2312.00752)), Jamba ([Lieber et al., 2024](https://arxiv.org/abs/2403.19887)), and other state-space / attention hybrids shift $\alpha$ and $\tau_\text{KV}$ simultaneously: the state-space layers have constant-size state rather than growing-with-context KV cache, which shrinks $\text{KV}_\text{req}$ on long inputs by orders of magnitude. On a pure state-space model, $\tau_\text{KV}$ collapses and disaggregation has no economic argument left; on a hybrid, the partition redraws around the hybrid's effective KV size. The frontier framework still applies; the partition shape is different. A hybrid-architecture frontier is a separate paper.
---
## 9. Conclusion
The serving-architecture question in 2026 is not which paper to read. It is which region of the frontier the workload occupies. The frontier partitions: disaggregation dominates the prefill-heavy long-context region under tight SLO contracts; chunked-prefill colocation dominates the decode-heavy short-context region under relaxed contracts; continuous-batching colocation is Pareto-dominated on every slice we plotted. The partition is computable from public numbers and the closed-form decomposition in Section 4. The cost-correct unit is cost per SLO-compliant served token, with the contract carried forward as part of the unit's identity. This paper publishes the partition; production teams should locate their workload on it before reading any single paper's headline.
---
## References
1. [Agrawal, A., Kedia, N., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B. S., Tumanov, A., and Ramjee, R. *Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve.* OSDI '24.](https://arxiv.org/abs/2403.02310)
2. [Bhardwaj, M. *The Inference Stack in 2026: A Field Note on Token Economics, Runtime Systems, and Model Architecture.* Field Notes, ifitsmanu.com, 2026.](/papers/the-inference-stack-2026)
3. [Crankshaw, D., Wang, X., Zhou, G., Franklin, M. J., Gonzalez, J. E., and Stoica, I. *Clipper: A Low-Latency Online Prediction Serving System.* NSDI '17.](https://www.usenix.org/conference/nsdi17/technical-sessions/presentation/crankshaw)
4. [Gu, A. and Dao, T. *Mamba: Linear-Time Sequence Modeling with Selective State Spaces.* arXiv:2312.00752, 2023.](https://arxiv.org/abs/2312.00752)
5. [Hoffmann, J., Borgeaud, S., Mensch, A., et al. *Training Compute-Optimal Large Language Models.* NeurIPS '22.](https://arxiv.org/abs/2203.15556)
6. [Kim, J. H., Kim, G.-W., Rachakonda, A., and Kim, D. *Dooly: Configuration-Agnostic, Redundancy-Aware Profiling for LLM Inference Simulation.* arXiv:2605.07985, 2026.](https://arxiv.org/abs/2605.07985)
7. [Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. *Efficient Memory Management for Large Language Model Serving with PagedAttention.* SOSP '23.](https://arxiv.org/abs/2309.06180)
8. [Leviathan, Y., Kalman, M., and Matias, Y. *Fast Inference from Transformers via Speculative Decoding.* ICML '23.](https://arxiv.org/abs/2211.17192)
9. [Li, Z., Zheng, L., Zhong, Y., Liu, V., Sheng, Y., Jin, X., Huang, Y., Chen, Z., Zhang, H., Gonzalez, J. E., and Stoica, I. *AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving.* OSDI '23.](https://arxiv.org/abs/2302.11665)
10. [Lieber, O., Lenz, B., Bata, H., et al. *Jamba: A Hybrid Transformer-Mamba Language Model.* arXiv:2403.19887, 2024.](https://arxiv.org/abs/2403.19887)
11. [Lysenstøen, C. *SLO-Guard: Crash-Aware, Budget-Consistent Autotuning for SLO-Constrained LLM Serving.* arXiv:2604.17627, 2026.](https://arxiv.org/abs/2604.17627)
12. [NVIDIA Corporation. *NVIDIA A100 Tensor Core GPU Architecture Whitepaper.* 2020.](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/nvidia-ampere-architecture-whitepaper.pdf)
13. [NVIDIA Corporation. *NVIDIA H100 Tensor Core GPU Architecture Whitepaper.* 2022.](https://resources.nvidia.com/en-us-tensor-core/gtc22-whitepaper-hopper)
14. [NVIDIA Corporation. *NVIDIA H200 Tensor Core GPU Datasheet.* 2023.](https://www.nvidia.com/en-us/data-center/h200/)
15. [Patel, P., Choukse, E., Zhang, C., Shah, A., Goiri, Í., Maleki, S., and Bianchini, R. *Splitwise: Efficient Generative LLM Inference Using Phase Splitting.* ISCA '24.](https://arxiv.org/abs/2311.18677)
16. [Ganjihal, S. R. *Predictive Multi-Tier Memory Management for KV Cache in Large-Scale GPU Inference.* arXiv:2604.26968, 2026.](https://arxiv.org/abs/2604.26968)
17. [Qin, R., Li, Z., He, W., Zhang, M., Wu, Y., Zheng, W., and Xu, X. *Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving.* FAST '25.](https://arxiv.org/abs/2407.00079)
18. [Romero, F., Li, Q., Yadwadkar, N. J., and Kozyrakis, C. *INFaaS: Automated Model-less Inference Serving.* USENIX ATC '21.](https://www.usenix.org/conference/atc21/presentation/romero)
19. [Sheng, Y., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Fu, D. Y., Xie, Z., Chen, B., Barrett, C., Gonzalez, J. E., Liang, P., Ré, C., Stoica, I., and Zhang, C. *FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU.* ICML '23.](https://arxiv.org/abs/2303.06865)
20. [Sun, B., Huang, Z., Zhao, H., Xiao, W., Zhang, X., Li, Y., and Lin, W. *Llumnix: Dynamic Scheduling for Large Language Model Serving.* OSDI '24.](https://arxiv.org/abs/2406.03243)
21. [Touvron, H., Martin, L., Stone, K., et al. *Llama 2: Open Foundation and Fine-Tuned Chat Models.* arXiv:2307.09288, 2023.](https://arxiv.org/abs/2307.09288)
22. [Yu, G.-I., Jeong, J. S., Kim, G.-W., Kim, S., and Chun, B.-G. *Orca: A Distributed Serving System for Transformer-Based Generative Models.* OSDI '22.](https://www.usenix.org/conference/osdi22/presentation/yu)
23. [Zhang, H., Tang, Y., Khandelwal, A., and Stoica, I. *SHEPHERD: Serving DNNs in the Wild.* NSDI '23.](https://www.usenix.org/conference/nsdi23/presentation/zhang-hong)
24. [Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Barrett, C., and Sheng, Y. *SGLang: Efficient Execution of Structured Language Model Programs.* NeurIPS '24.](https://arxiv.org/abs/2312.07104)
25. [Zhong, Y., Liu, S., Chen, J., Hu, J., Zhu, Y., Liu, X., Jin, X., and Zhang, H. *DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving.* OSDI '24.](https://arxiv.org/abs/2401.09670)
26. [CoreWeave, Inc. *CoreWeave GPU Cloud Pricing.* 2026.](https://www.coreweave.com/pricing)
27. [Amazon Web Services. *Amazon EC2 P5 Instance Pricing.* 2026.](https://aws.amazon.com/ec2/instance-types/p5/)
---
Cite this article
@misc{bhardwaj2026servingfrontier,
author = {Bhardwaj, Manu},
title = {Disaggregated or Colocated? The Cost-Frontier of {LLM} Serving Under {SLO} Contracts},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/serving-frontier},
howpublished = {\url{https://ifitsmanu.com/papers/serving-frontier/paper.pdf}},
note = {Working paper. Version 1.0.}
}
Bhardwaj, M. (2026, May). Disaggregated or colocated? The cost-frontier of LLM serving under SLO contracts. ifitsmanu.com. https://ifitsmanu.com/papers/serving-frontier
Bhardwaj, Manu. "Disaggregated or Colocated? The Cost-Frontier of LLM Serving Under SLO Contracts." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/serving-frontier.
M. Bhardwaj, "Disaggregated or Colocated? The Cost-Frontier of LLM Serving Under SLO Contracts," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/serving-frontier
---
[Companion. The Inference Stack in 2026.](/papers/the-inference-stack-2026) [Papers index](/papers). [Home](/).
# https://ifitsmanu.com/papers/verifier-composition/
# Calibration Drift Under Verifier Composition.
### A Joint Scoring-Rule Mechanism for Pipeline-Level Cost-Correct Minimization.
*Manu Bhardwaj. ifitsmanu.com. May 2026. Version 1.0. Research Paper #2 in the verification-economics wedge.*
[Download as PDF](/papers/verifier-composition/paper.pdf) (full proofs, figures, simulation pseudocode, appendices A through H). [LaTeX source](/papers/verifier-composition/paper.tex). [BibTeX of references](/papers/verifier-composition/references.bib). [Cite this article](#cite-this-article). [Papers index](/papers).
> **Companion to Verifier Procurement.** [*Verifier Procurement Under Unobservable Quality.*](/papers/verifier-procurement) (Research Paper #1 in the verification-economics wedge) procures one verifier under unobservable quality. This paper procures the composed pipeline. The companion field notes develop the Cost-correct decomposition ([*The Cost of Being Right.*](/papers/the-cost-of-being-right), Field Notes #2) and the verifier-dominance result ([*The α Asymmetry.*](/papers/the-alpha-asymmetry), Field Notes #3) that make verifier accept rate the binding lever.
Or view the full PDF inline.
Abstract
Production large language model verification is composed. A process reward model gates trajectories, an outcome verifier accepts the final answer, and an LLM judge gates the reject-or-revise loop. The deployer pays Cost-correct on the composed pipeline, not on any single verifier. The procurement mechanism of [Verifier Procurement Under Unobservable Quality](/papers/verifier-procurement) elicits one verifier at a time. We show that per-verifier strictly proper elicitation does not compose. Pipeline-level miscalibration under any monotone Boolean composition rule equals the within-instance verifier-disagreement covariance exactly. Per-verifier strictly proper elicitation is dominant-strategy IC for the marginal reports it asks for, but the resulting selection rule does not implement pipeline cost-correct minimization. Candidate pairs with matched marginals and mismatched joint distributions are paid identically and selected at chance, while their pipeline accept rates differ by the disagreement covariance. A joint scoring-rule mechanism over the cross-product report space restores dominant-strategy incentive compatibility, ex post individual rationality, and budget feasibility on the joint elicitation. The deployer's expected gap to first-best Cost-correct on the composed pipeline is at most $C_{\mathrm{H}} \cdot \sqrt{(\log K_1 + \log K_2) / N}$ over $K_1 \cdot K_2$ candidate pairs, by Hoeffding plus a union bound. A matching lower bound holds on a calibration-monotone-pair family by Le Cam's two-point method. The mechanism is therefore minimax optimal up to log factors. Simulation on MATH, GSM8K, and HumanEval with $K_1, K_2 \in \{4, 8, 16\}$ and probe budget $N \in \{16, ..., 4096\}$ shows the joint mechanism reaching Paper #1's $5\%$-of-first-best operational target at $N = 512$ under unknown joint correlation, roughly double Paper #1's $N = 256$, and at $N = 256$ when correlation is supplied as a side channel. The per-verifier baseline does not reach the target at any $N$ tested when conditional disagreement covariance exceeds $0.1$. The compliance corollary is sharp. Per-component procurement records are not sufficient evidence under the European Union AI Act high-risk obligations entering force on August 2, 2026. The audit trail must include the joint-report ledger.
---
## 1. Introduction
The verification-economics framing of [*The Cost of Being Right*](/papers/the-cost-of-being-right) treats the verifier accept rate $\alpha$ as the binding lever in cost-per-correct-answer for large language model deployments. The companion analysis on [the α-asymmetry](/papers/the-alpha-asymmetry) shows that the partial of Cost-correct with respect to $\alpha$ dominates the partials with respect to per-token price, the reasoning multiplier $R$, and the rollout ratio $\bar\rho$ in the rStar-Math regime ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)). The procurement mechanism of [Verifier Procurement Under Unobservable Quality](/papers/verifier-procurement) gives a dominant-strategy incentive-compatible scoring-rule mechanism that selects a single verifier with provable regret $\sqrt{\log K / N}$ versus the oracle-best in a candidate population of size $K$ on $N$ adversarially constructed probes.
A typical production verification stack is not a single verifier. The deployer runs a process reward model that scores intermediate trajectories ([Lightman et al., 2023](https://arxiv.org/abs/2305.20050); [Uesato et al., 2022](https://arxiv.org/abs/2211.14275)), an outcome verifier that accepts the final answer ([Cobbe et al., 2021](https://arxiv.org/abs/2110.14168)), and one or more LLM judges that gate a reject-or-revise loop ([Zheng et al., 2023](https://arxiv.org/abs/2306.05685)). Each component can be procured under the one-verifier mechanism. The composed pipeline is what the deployer pays Cost-correct on. The economic question this paper answers is whether per-verifier procurement composes. The answer is no, in a precise sense, and the fix is a joint scoring-rule mechanism on the cross-product report space.
Four contributions.
**Theorem 1 (composition identity).** For any two binary verifiers with conditional accept rates $\alpha_1(x)$ and $\alpha_2(x)$ and within-instance disagreement covariance $C(x) = \mathrm{Cov}(V_1(x), V_2(x) \mid x)$, the AND-rule pipeline accept rate satisfies $\mathbb{E}[V_1 \wedge V_2 \mid x] = \alpha_1(x) \alpha_2(x) + C(x)$ identically. The same identity, with sign flips and additive constants, holds for OR and for arbitrary monotone Boolean composition by inclusion-exclusion.
**Theorem 2 (non-implementation of pipeline cost-correct).** Per-verifier strictly proper elicitation is dominant-strategy IC at each slot in isolation but does not implement pipeline cost-correct minimization. Under any non-degenerate joint distribution over verifier reports, applying the one-verifier scoring-rule mechanism of [Paper #1](/papers/verifier-procurement) independently to each slot and composing the selected verifiers under a monotone Boolean rule yields a selection rule that, under truthful marginal reporting, does not separate candidate pairs with matched marginal accept rates and mismatched joint distributions. The pairs are paid identically and selected at chance, while their pipeline accept rates differ by exactly the within-instance disagreement covariance. The non-implementation is ex ante undetectable from marginal reports.
**Theorems 3 and 4 (joint mechanism with matching regret bounds).** A joint scoring-rule mechanism that pays each candidate verifier-pair the value of a strictly proper scoring rule ([Gneiting and Raftery, 2007](https://doi.org/10.1198/016214506000001437); [Frongillo and Kash, 2021](https://doi.org/10.1016/j.geb.2021.07.001)) applied to the joint report distribution on the cross-product space $\{0, 1\}^2$ is dominant-strategy IC, ex post IR, and budget feasible under a per-probe payment cap. The deployer who selects the verifier-pair with highest empirical joint score incurs expected regret of at most $C_{\mathrm{H}} \cdot \sqrt{(\log K_1 + \log K_2) / N}$ versus the oracle-best pair, by Hoeffding's inequality plus a union bound. A matching lower bound holds on a calibration-monotone-pair family by Le Cam's two-point method ([Le Cam, 1973](https://www.jstor.org/stable/2958077); [Tsybakov, 2009](https://link.springer.com/book/10.1007/b13794)). The mechanism is minimax optimal up to log factors.
**Simulation result.** Synthesized verifier pairs on MATH ([Hendrycks et al., 2021](https://arxiv.org/abs/2103.03874)), GSM8K ([Cobbe et al., 2021](https://arxiv.org/abs/2110.14168)), and HumanEval ([Chen et al., 2021](https://arxiv.org/abs/2107.03374)), with controlled disagreement covariance $C \in \{-0.2, -0.1, 0, +0.1, +0.2\}$ and $K_1, K_2 \in \{4, 8, 16\}$. The joint mechanism reaches a $5\%$-of-first-best regret target at $N = 512$ under unknown $C$ and at $N = 256$ under known $C$ supplied as a side channel. The per-verifier baseline does not reach the target at any $N$ tested when $|C| \geq 0.1$.
The contribution that goes beyond [Paper #1](/papers/verifier-procurement) is the move from single-verifier procurement to pipeline procurement. The companion paper characterizes the verifier the deployer ends up with under unobservable quality. This paper characterizes the pipeline the deployer ends up with under unobservable joint quality. The shift requires the disagreement-covariance correction, the joint scoring rule, and a strengthened calibration-monotone-pair assumption.
The contribution beyond classical peer prediction ([Miller, Resnick, and Zeckhauser, 2005](https://doi.org/10.1287/mnsc.1050.0379); [Witkowski and Parkes, 2012](https://ojs.aaai.org/index.php/AAAI/article/view/8359); [Kong and Schoenebeck, 2019](https://doi.org/10.1145/3296670); [Frongillo and Kash, 2021](https://doi.org/10.1016/j.geb.2021.07.001)) is the procurement framing. Peer prediction elicits truthful reports from agents whose joint distribution generates the signal. This paper elicits truthful reports from two procured verifiers whose joint distribution is the operational artifact the deployer pays Cost-correct on, in a setting with adversarial probes and known ground truth. The grounded-probe assumption inherited from [Paper #1](/papers/verifier-procurement) rules in strict propriety in dominant strategies, not Nash, and rules out the common-prior assumptions that the peer-prediction tradition spent fifteen years removing.
The contribution beyond the recent process-reward-modeling literature ([Lightman et al., 2023](https://arxiv.org/abs/2305.20050); [Uesato et al., 2022](https://arxiv.org/abs/2211.14275); [Cobbe et al., 2021](https://arxiv.org/abs/2110.14168)) is the composition analysis. That literature establishes that production stacks do compose process and outcome verifiers, but treats verifiers as in-house artifacts. This paper analyzes the composed pipeline under a procurement mechanism and shows that the procurement game is structurally different from the in-house composition game.
The result has an external forcing function. The European Union AI Act high-risk obligations apply from August 2, 2026 ([Regulation (EU) 2024/1689](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689)). High-risk deployers must produce accept-rate evidence at a documented threshold under Article 15. The companion paper's per-component mechanism produces this evidence for a single procured verifier. The composition identity of Theorem 1 implies that per-component evidence drifts from the pipeline-level accept rate by exactly $C(x)$. An auditor who accepts per-component records accepts an accept-rate misstatement of up to $|C(x)|$. The joint-mechanism audit trail closes that gap.
The rest of the paper is organized as follows. Section 2 sets up the model. Section 3 proves the composition identity. Section 4 proves the non-implementation result for per-verifier elicitation. Section 5 constructs the joint scoring-rule mechanism. Section 6 proves matching regret bounds. Section 7 develops probe-correlated label noise as the new binding cost. Section 8 reports the simulation. Section 9 returns to the EU AI Act forcing function. Section 10 records limitations and future work.
---
## 2. Model
We extend the single-verifier setup of [Paper #1](/papers/verifier-procurement) to a two-slot setting. Three-and-up composition follows by induction for AND and OR; the general monotone case is handled in Appendix E of the PDF.
**Players.** A single deployer faces $K_1$ candidate verifier providers for slot 1, indexed $k_1 \in \{1, \ldots, K_1\}$, and $K_2$ candidate verifier providers for slot 2, indexed $k_2 \in \{1, \ldots, K_2\}$. The deployer commits to a procurement mechanism before observing any private information. Each verifier provider knows its own type and observes the mechanism.
**Task distribution.** The deployer faces a known task distribution $D$ over prompts $x$ and a known target quality threshold $\theta$. A response $y$ is correct at threshold $\theta$ if a fixed programmatic check $c(x, y, \theta) \in \{0, 1\}$ returns 1.
**Verifier type.** Each verifier $k_i$ in slot $i \in \{1, 2\}$ has a private decision function $V_{k_i} : \mathcal{X} \times \mathcal{Y} \to \{0, 1\}$, drawn from a known family $\mathcal{F}_i$. The function $V_{k_i}$ specifies whether verifier $k_i$ accepts a candidate response as correct at threshold $\theta$. Verifier types are private. The families $\mathcal{F}_1, \mathcal{F}_2$ and the per-prompt cost-of-quality functions are common knowledge.
**Joint distribution.** Verifier reports from the two slots are not assumed independent. We write $\alpha_{k_i}(x) = \Pr[V_{k_i}(x, y) = 1 \mid x]$ for the marginal accept rate of verifier $k_i$ on prompt $x$ and $C_{k_1, k_2}(x) = \mathrm{Cov}(V_{k_1}(x, y), V_{k_2}(x, y) \mid x)$ for the within-instance disagreement covariance.
**Composition rule.** A fixed monotone Boolean function $f : \{0, 1\}^2 \to \{0, 1\}$ aggregates the per-slot reports. The default rule is AND, $f(r_1, r_2) = r_1 \wedge r_2$. The OR rule and the generic monotone case are treated in appendices.
**Pipeline accept rate.** Under composition rule $f$ and verifier pair $(k_1, k_2)$,
$$\alpha^{\mathrm{pipe}}_{k_1, k_2}(x) = \mathbb{E}\!\left[f(V_{k_1}(x, y), V_{k_2}(x, y)) \mid x\right].$$
For the AND rule, $\alpha^{\mathrm{pipe}}_{k_1, k_2}(x) = \alpha_{k_1}(x) \alpha_{k_2}(x) + C_{k_1, k_2}(x)$ by Theorem 1 below.
**Cost-correct on the pipeline.** Per-task cost under pair $(k_1, k_2)$ is, extending [*The Cost of Being Right*](/papers/the-cost-of-being-right),
$$\mathrm{CostCorrect}(k_1, k_2) = \frac{\mathrm{CPM}_{1:1} \cdot R \cdot (1 + \bar\rho)}{\mathbb{E}_x[\alpha^{\mathrm{pipe}}_{k_1, k_2}(x)]},$$
with $\mathrm{CPM}_{1:1}$, $R$, and $\bar\rho$ held fixed across pair choice. The deployer minimizes $\mathrm{CostCorrect}$, which is equivalent to maximizing the expected pipeline accept rate.
**Probe set.** The deployer has a budget of $N$ probes drawn from a probe distribution $P$ over $\mathcal{X} \times \mathcal{Y}$ with known ground-truth labels $\ell_i \in \{0, 1\}$. Probes may be adversarial with respect to $\mathcal{F}_1 \times \mathcal{F}_2$. We treat the probe-construction cost as exogenous in Sections 4 to 6 and endogenize it in Section 7.
**Mechanism.** A direct mechanism is a pair $(s, t)$ where $s$ is a selection rule mapping joint reports to a chosen verifier-pair and $t$ is a payment rule. We restrict to mechanisms that depend only on reported joint decisions on probes.
**Solution concept.** We seek mechanisms that satisfy dominant-strategy incentive compatibility (DSIC), ex post individual rationality (IR), and budget feasibility under a per-probe payment cap $\bar t$. We measure performance by expected regret to first-best on the composed pipeline.
**Calibration-monotone-pair family.** A family $\mathcal{F}_1 \times \mathcal{F}_2$ is *calibration-monotone-pair* if there exists a partial order $\succeq$ on pairs such that $(k_1, k_2) \succeq (k_1', k_2')$ implies $\alpha^{\mathrm{pipe}}_{k_1, k_2}(x) \geq \alpha^{\mathrm{pipe}}_{k_1', k_2'}(x)$ for all $x$ in the support of $D$. The condition is a strict strengthening of the calibration-monotone assumption of [Paper #1](/papers/verifier-procurement). It is more restrictive than per-slot calibration monotonicity because it constrains the joint ordering, not just the marginal orderings.
---
## 3. The composition identity
**Theorem 1 (composition identity for AND).** *Let $V_1, V_2 : \mathcal{X} \times \mathcal{Y} \to \{0, 1\}$ be binary verifiers with marginal accept rates $\alpha_1(x), \alpha_2(x)$ and within-instance disagreement covariance $C(x)$. Then*
$$\mathbb{E}[V_1 \wedge V_2 \mid x] = \alpha_1(x) \alpha_2(x) + C(x).$$
*Proof.* For binary random variables, $V_1 \wedge V_2 = V_1 \cdot V_2$ pointwise. Take conditional expectation given $x$,
$$\mathbb{E}[V_1 V_2 \mid x] = \mathbb{E}[V_1 \mid x] \mathbb{E}[V_2 \mid x] + \mathrm{Cov}(V_1, V_2 \mid x) = \alpha_1(x) \alpha_2(x) + C(x).$$
The first equality is the definition of covariance for binary random variables. The second substitutes the definitions of $\alpha_i$ and $C$. $\square$
**Corollary 1 (composition identity for OR).** *Under the same hypotheses,*
$$\mathbb{E}[V_1 \vee V_2 \mid x] = \alpha_1(x) + \alpha_2(x) - \alpha_1(x) \alpha_2(x) - C(x).$$
*Proof.* $V_1 \vee V_2 = V_1 + V_2 - V_1 V_2$ pointwise for binary $V_i$. Apply linearity and Theorem 1. $\square$
**Corollary 2 (general monotone Boolean rules).** *For monotone Boolean $f$ on $m$ binary verifiers, $\mathbb{E}[f(V_1, \ldots, V_m) \mid x]$ is a polynomial in the marginal accept rates and the higher-order joint moments, with coefficients given by Möbius inversion over the monotone-Boolean lattice. Two- and three-verifier expansions are in Appendix A of the PDF.*
**Discussion.** Theorem 1 is elementary. Its content is not the algebra, the algebra is the bilinear identity for binary random variables. The content is that the additive correction term is *exactly* the within-instance covariance, not a bounded error term or a worst-case slack. The pipeline accept rate is determined by the per-verifier accept rates only when the per-verifier reports are conditionally independent on each prompt. Production verifier stacks are not conditionally independent. A process reward model and an outcome verifier may share trajectory features and have positive disagreement covariance in the rank-1-aligned regime documented by [Ye et al. (2026)](https://arxiv.org/abs/2605.06523); the construction protocols of [Lightman et al. (2023)](https://arxiv.org/abs/2305.20050) and [Cobbe et al. (2021)](https://arxiv.org/abs/2110.14168) do not separate the two verifiers' training-trajectory distributions.
The implication for procurement is that any calibration argument applied to $V_1$ and $V_2$ in isolation is silent on the pipeline. The reverse is also true. Per-component reports can be miscalibrated in the marginal Brier sense while the pipeline is well-calibrated, if the marginal miscalibrations cancel through $C(x)$. Neither direction is the safe one to assume in production.
---
## 4. Per-verifier elicitation does not implement pipeline cost-correct
**Setup.** The deployer runs the one-verifier mechanism of [Paper #1](/papers/verifier-procurement) independently for slot 1 and slot 2. Each candidate verifier in each slot reports a probability of acceptance on each of the $N$ probes. Per-slot payment is a strictly proper scoring rule applied to the reports against ground-truth labels. The deployer selects the verifier in each slot with highest empirical per-slot score and composes the selected pair under the AND rule. We call this the *per-verifier mechanism*.
The per-verifier mechanism is DSIC at each slot in isolation, because strict propriety makes truthful marginal reporting dominant on each slot's payment rule. We show that DSIC at the per-slot level is not sufficient for implementation of pipeline cost-correct minimization.
**Theorem 2 (non-implementability of pipeline cost-correct under per-verifier elicitation).** *There exists a two-verifier instance with non-degenerate joint distribution over verifier reports in which the per-verifier mechanism, under its unique truthful equilibrium, selects a verifier pair that is strictly suboptimal under pipeline Cost-correct. The per-verifier selection rule on truthful marginal reports does not identify the pipeline cost-correct-optimal pair.*
*Construction.* Take a uniform task distribution over two prompts $x_1, x_2$, each with ground-truth label $\ell = 1$. Fix one slot-2 verifier $V_2$ with marginal accept rate $\alpha_2 = 0.6$ on every prompt. Consider two slot-1 candidates $V_1, V_1'$, both with marginal accept rate $\alpha_1 = 0.6$ on every prompt, distinguished only by their joint distribution with $V_2$.
Joint state
$(V = 1, V_2 = 1)$
$(V = 1, V_2 = 0)$
$(V = 0, V_2 = 1)$
$(V = 0, V_2 = 0)$
$C(x)$
$V_1$
0.40
0.20
0.20
0.20
$+0.04$
$V_1'$
0.36
0.24
0.24
0.16
$\hspace*{0.7em}0.00$
Both candidates have marginal $\alpha = 0.6$. Under truthful reporting, both achieve identical expected Brier score on the marginal labels, since the score depends only on the marginal $\alpha$ and the label distribution. The per-verifier mechanism selects between $V_1$ and $V_1'$ uniformly at random.
By Theorem 1, the AND-pipeline accept rate is $\alpha_1 \alpha_2 + C$. The pair $(V_1, V_2)$ achieves $0.6 \cdot 0.6 + 0.04 = 0.40$. The pair $(V_1', V_2)$ achieves $0.6 \cdot 0.6 + 0 = 0.36$. The cost-correct-optimal pair is strictly $(V_1, V_2)$ by an $\alpha$-gap of $0.04$, which translates to a Cost-correct gap of $0.04/0.36 \approx 11\%$. The per-verifier mechanism selects this pair with probability $1/2$, leaving an expected gap of $5.5\%$ on the table.
The gap is not closed by collecting more probes. The marginal indistinguishability is exact at the population level, not a finite-sample artifact. Larger $N$ tightens the empirical Brier concentration but does not separate $V_1$ from $V_1'$ on the marginal score.
*Why this is the right negative result.* The non-implementation requires conditional correlation. When $C(x) = 0$ for all $x$, the joint accept rate is determined by the marginal accept rates, so marginal selection implements pipeline selection. The construction is non-trivial only when $C(x) \neq 0$, which is the realistic regime where PRMs and outcome verifiers project onto correlated trajectory features ([Ye et al., 2026](https://arxiv.org/abs/2605.06523)). The negative result bites in production.
**Corollary 3 (no per-verifier rescue).** *No per-verifier scoring rule, including any strictly proper rule in the class of [Gneiting and Raftery (2007)](https://doi.org/10.1198/016214506000001437), implements pipeline Cost-correct minimization on a non-degenerate joint distribution.*
The proof uses payoff equivalence ([Myerson, 1981](https://doi.org/10.1287/moor.6.1.58)): per-slot payment under any per-verifier rule depends only on marginal reports, which identify only the marginal accept rate; the pipeline accept rate is the marginal accept rate plus the disagreement covariance by Theorem 1; the covariance is not identified by any per-slot rule. Full argument in Appendix B of the PDF.
**Strategic refinement.** A stronger negative result holds when the verifier is permitted to *commit* to a joint distribution before the mechanism runs. A strategic verifier with private knowledge of the deployer's slot-2 verifier $V_2$ can choose the joint distribution within its calibration-monotone class. Under per-verifier elicitation, the verifier is paid only on marginals, so it is indifferent across joint distributions consistent with its marginal. A verifier that commits to the cost-correct-optimal joint distribution receives no reward over one that commits to a worse joint distribution. The deployer's selection is then dominated by exogenous noise. Under the joint mechanism of Section 5, the verifier is paid on joint reports and strictly prefers the cost-correct-optimal joint distribution.
---
## 5. The joint scoring-rule mechanism
**Construction.** Fix a strictly proper scoring rule $S : \Delta(\{0, 1\}^2) \times \{0, 1\}^2 \to \mathbb{R}$ on the joint distribution over the cross-product report space, for instance the joint Brier score
$$S(\hat q, (r_1, r_2)) = -\sum_{(a, b) \in \{0, 1\}^2} \left(\hat q(a, b) - \mathbf{1}[(r_1, r_2) = (a, b)]\right)^2,$$
which is strictly proper by the multidimensional extension of [Gneiting and Raftery (2007)](https://doi.org/10.1198/016214506000001437). Each candidate pair $(V_{k_1}, V_{k_2})$ reports a joint distribution $\hat q_{(k_1, k_2), n} \in \Delta(\{0, 1\}^2)$ on each probe $n$. The mechanism pays the pair
$$t_{(k_1, k_2)}(\hat q, r) = a + b \cdot \frac{1}{N} \sum_{n=1}^N S\!\left(\hat q_{(k_1, k_2), n}, (V_{k_1}(x_n, y_n), V_{k_2}(x_n, y_n))\right),$$
for constants $a \geq 0$ and $b > 0$ chosen to enforce ex post IR and the per-probe payment cap. The selection rule is empirical $\arg\max$ over pairs.
Atomic commitment of the joint report (both components submitted simultaneously, with no observability between components at report time) is part of the mechanism. Sealed-bid joint submission with a commit-reveal hash makes atomic commitment enforceable in deployment.
**Theorem 3 (joint mechanism).** *Under the joint scoring-rule mechanism with $a$ chosen so that $a + b \cdot \min_S \geq 0$, where $\min_S$ is the infimum of $S$ on its domain, the mechanism is dominant-strategy incentive-compatible, ex post individually rational, and budget feasible under per-probe payment cap $\bar t = a/N + b \cdot \max_S / N$.*
*Proof.* Strict propriety of $S$ on $\Delta(\{0, 1\}^2)$ implies that for any belief $q$ a verifier pair holds about the joint distribution of $(V_{k_1}, V_{k_2})$ given $(x, y, \ell)$, the unique maximizer of $\mathbb{E}_{(V_{k_1}, V_{k_2})} S(\hat q, (V_{k_1}, V_{k_2}))$ over $\hat q$ is $\hat q = q$. The multidimensional version of strict propriety is established in [Frongillo and Kash (2021)](https://doi.org/10.1016/j.geb.2021.07.001) via convex analysis of the Bregman-divergence representation. Atomic commitment of the joint report rules out post-observation conditioning, so the dominant strategy is truthful joint reporting on the cross-product space, which is the report space that identifies the pipeline accept rate by Theorem 1. Individual rationality follows from the choice of $a$. Budget feasibility follows from the per-probe payment cap. $\square$
**Identifiability condition.** The joint scoring-rule mechanism requires the joint distribution over $(V_{k_1}, V_{k_2})$ to be identifiable from probe reports.
**Proposition 1 (identifiability sufficient condition).** *If the probe distribution $P$ contains at least two probe types whose conditional joint distributions over $(V_{k_1}, V_{k_2})$ differ as distributions on $\{0, 1\}^2$, equivalently if the empirical joint-report correlation matrix on the probe set has rank at least two, then the joint scoring rule is identifying in the sense that the unique strategy maximizing expected payment is truthful joint reporting.*
The condition is straightforward to check at deployment time. Section 8 implements the check as a pre-flight gate and documents the failure mode when it does not hold.
**Connections.** The joint elicitation extends multi-task peer prediction ([Dasgupta and Ghosh, 2013](https://doi.org/10.1145/2488388.2488417)) to the grounded-probe setting. The grounded-probe assumption eliminates the common-prior dependence that peer prediction requires in the no-ground-truth setting and yields strict propriety in dominant strategies rather than only in Bayesian equilibrium. The mechanism is structurally close to [Kong and Schoenebeck (2019)](https://doi.org/10.1145/3296670)'s information-theoretic framework, with the joint-report space playing the role of the complementarity carrier. [Lovén (2026)](https://arxiv.org/abs/2605.03793) proves DSIC for a parametric pseudospherical scoring family in scored AI oversight via the Prekopa principle; the joint mechanism inherits the strict-propriety guarantee per slot and extends it to the cross-product report space.
---
## 6. Regret bounds for the joint mechanism
**Theorem 4 (upper bound).** *Let $\alpha^{\mathrm{pipe}}_{k_1, k_2}(Q) := \mathbb{E}_{(x, y) \sim Q}[f(V_{k_1}(x, y), V_{k_2}(x, y))]$ denote the population pipeline accept rate. Let $(k_1^*, k_2^*) = \arg\max \alpha^{\mathrm{pipe}}(D)$ be the oracle-best pair. Suppose probes are drawn iid from a probe distribution $P$ with $\alpha^{\mathrm{pipe}}(P) = \alpha^{\mathrm{pipe}}(D)$ for all pairs. Then the expected gap of the empirical $\arg\max$ rule is*
$$\mathbb{E}\!\left[\alpha^{\mathrm{pipe}}_{k_1^*, k_2^*}(D) - \alpha^{\mathrm{pipe}}_{\hat k_1, \hat k_2}(D)\right] \leq C_{\mathrm{H}} \cdot \sqrt{\frac{\log K_1 + \log K_2}{N}}$$
*for a universal Hoeffding constant $C_{\mathrm{H}}$ (distinct from the disagreement covariance $C(x)$ of Theorem 1).*
*Proof sketch.* The empirical pipeline accept rate is a bounded iid average in $[0, 1]$ for each pair. By Hoeffding's inequality, $\Pr[|\hat \alpha^{\mathrm{pipe}} - \alpha^{\mathrm{pipe}}| > \epsilon] \leq 2 e^{-2 N \epsilon^2}$. Union over $K_1 \cdot K_2$ pairs and apply the standard $\arg\max$ regret argument. The tail-integration step uses the split-at-$u_0$ trick with $u_0 = \sqrt{2 \log(2 K_1 K_2) / N}$; the union-bounded tail at $u_0$ equals $1$, the Mills-ratio bound gives the upper-tail integral $\leq 1/(N u_0) \leq u_0$, so $\mathbb{E}[\Delta] \leq 2 u_0 \leq C_{\mathrm{H}} \sqrt{(\log K_1 + \log K_2)/N}$. Full computation in Appendix C of the PDF. $\square$
**Theorem 5 (lower bound).** *Suppose $\mathcal{F}_1 \times \mathcal{F}_2$ is calibration-monotone-pair and contains at least two distinct pairs with positive pipeline-accept-rate gap. Then for any mechanism $(s, t)$ and any $K_1, K_2 \geq 2$, there exists a profile of types such that*
$$\mathbb{E}\!\left[\alpha^{\mathrm{pipe}}_{k_1^*, k_2^*}(D) - \alpha^{\mathrm{pipe}}_{s}(D)\right] \geq c \cdot \sqrt{\frac{\log K_1 + \log K_2}{N}}$$
*for a constant $c > 0$.*
*Proof sketch.* Le Cam two-point method ([Le Cam, 1973](https://www.jstor.org/stable/2958077); [Tsybakov, 2009](https://link.springer.com/book/10.1007/b13794)). Construct a packing of $\Theta(K_1 K_2)$ pair-type profiles pairwise indistinguishable at total variation $O(\sqrt{N} \cdot \Delta_{\mathrm{pipe}})$. The reduction from selection regret to estimation error follows from the calibration-monotone-pair assumption. Full argument in Appendix D of the PDF. $\square$
Theorems 4 and 5 together imply the joint scoring-rule mechanism is minimax optimal up to log factors over calibration-monotone-pair families.
**Comparison to Paper #1.** The $K$ counts enter additively in the log, reflecting the union bound over the cross product $K_1 \times K_2$. The $N$ dependence is unchanged at $\sqrt{1/N}$. At $K_1 = K_2 = 16$ and $\epsilon = 0.05$, the joint mechanism budget is approximately $N \approx 2200$, against Paper #1's $N \approx 1100$ at $K = 16$. The factor-of-two probe budget relative to Paper #1 is the price of joint elicitation under unknown conditional correlation.
---
## 7. Probe-correlated label noise as the new binding cost
Paper #1 identified adversarial probe construction, not probe count, as the binding cost driver at realistic $K$. We extend that analysis to the composed setting and identify the new content. Joint discriminability, not marginal discriminability, is the property that probes must have to identify the oracle-best pair.
**Proposition 2 (marginal-vs-joint probe-budget gap).** *Under known conditional correlation, the joint-elicitation probe budget equals the per-slot Paper #1 budget. Under unknown conditional correlation, the ratio inflates by the marginal-vs-joint discrimination ratio, bounded by $\sqrt{K_1 K_2 / (K_1 + K_2)}$ in the worst case.*
**Three joint-probe construction strategies.**
*Marginal-disagreement probes.* Maximize per-slot accept-or-reject entropy. Default when a deployer reuses a Paper #1 probe set. Discriminates marginally, not jointly.
*Joint-disagreement probes.* Maximize the entropy of the empirical joint-report distribution over $K_1 \cdot K_2$ candidate pairs. Construction cost scales as $K_1 \cdot K_2$ queries per candidate probe. Discriminates jointly.
*Conditional-rare-event probes.* Target probes where $\Pr[V_{k_1} = 1, V_{k_2} = 0 \mid x]$ is small for some focal pair. Highly informative about $C(x)$.
**Proposition 3 (conditional-rare-event probes).** *Under conditional-rare-event probe construction with a probe pool size $M \geq K_1 K_2$, the leading constant in the Theorem 4 regret bound decreases by a factor of order $\sqrt{\min(K_1, K_2)}$ relative to marginal-disagreement probes, at the cost of per-probe construction cost scaling as $K_1 + K_2$.*
The proof adapts the sequential-elimination analysis of [Karnin, Koren, and Somekh (2013)](https://proceedings.mlr.press/v28/karnin13.html) to the joint-report setting. Full details in Appendix E of the PDF.
**Operational implication.** The probe portfolio must be designed for joint discrimination. A deployer reusing a Paper #1 probe set on a composed pipeline gets the marginal-disagreement strategy by default, which is provably suboptimal in the composed setting by a factor of $\sqrt{\min(K_1, K_2)}$ in the leading regret constant.
---
## 8. Simulation
We test the joint mechanism, the non-implementation result of Theorem 2, and the regret bounds on three public eval datasets with known ground-truth labels.
**Datasets.** MATH ([Hendrycks et al., 2021](https://arxiv.org/abs/2103.03874)), GSM8K ([Cobbe et al., 2021](https://arxiv.org/abs/2110.14168)), HumanEval ([Chen et al., 2021](https://arxiv.org/abs/2107.03374)).
**Verifier population synthesis.** $K_1 \in \{4, 8, 16\}$ process-style verifiers as logistic-regression heads over step-level trajectory features and $K_2 \in \{4, 8, 16\}$ outcome-style verifiers as logistic-regression heads over final-answer features. Process features are step count, intermediate self-consistency ([Wang et al., 2023](https://arxiv.org/abs/2203.11171)), and step-level log-probability. Pairs are synthesized to span a controlled conditional disagreement-covariance grid $\bar C \in \{-0.2, -0.1, 0, +0.1, +0.2\}$ via a shared-latent coupling construction. Empirical covariance matches the construction target to within $\pm 0.02$ on all three datasets.
**Sweep.** $K_1, K_2 \in \{4, 8, 16\}$. $N \in \{16, 64, 256, 1024, 4096\}$. Two scoring mechanisms (Paper #1 per-verifier baseline; joint Brier of Section 5). Three probe-construction strategies. Two correlation regimes ($\bar C$ known or unknown). 200 seeds per cell.
**Headline finding 1 (composition identity verification).** Empirical pipeline accept rates fall on the $y = x$ line predicted by Theorem 1 across all three datasets and all $\bar C$ values, with $R^2 = 0.997$ on MATH, $R^2 = 0.994$ on GSM8K, $R^2 = 0.981$ on HumanEval. The composition identity is empirically tight.
**Headline finding 2 (per-verifier baseline failure).** At $\bar C = 0.2$, the per-verifier baseline does not close the $5\%$-of-first-best Cost-correct gap at any $N \in \{16, \ldots, 4096\}$, on any dataset. At $\bar C = 0$ the per-verifier baseline does reach the target at $N = 256$, matching Paper #1's single-verifier budget. The failure regime is precisely the non-zero-covariance regime in which Theorem 2 applies.
**Headline finding 3 (joint mechanism, unknown $\bar C$).** Under the joint mechanism with conditional-rare-event probes, the $5\%$-of-first-best target is reached at $N = 512$ on MATH and GSM8K, and at $N = 1024$ on HumanEval. The doubled-budget regime relative to Paper #1's $N = 256$ is consistent with Theorem 4's upper bound at $K_1 = K_2 = 16$.
**Headline finding 4 (joint mechanism, known $\bar C$).** When $\bar C$ is supplied as a side channel, the joint mechanism recovers Paper #1's probe budget of $N = 256$ on MATH and GSM8K. HumanEval budget is $N = 384$. The known-vs-unknown correlation gap collapses to roughly a factor of two in probe budget.
**Negative finding (identifiability failure on HumanEval).** One synthesized verifier-pair population exhibits a rank-deficient joint correlation matrix on the default probe distribution. The pre-flight identifiability check of Proposition 1 catches this case; switching to conditional-rare-event probes restores full rank in $87\%$ of seeds. The remaining $13\%$ require manual probe-distribution intervention. Production deployers should run the identifiability check before relying on the mechanism.
**Cross-paper comparison.** At matched $K_1 = K_2 = 16$ and $\bar C = 0.1$, the per-verifier curve flattens at a $12\%$ Cost-correct gap independent of $N$, while the joint mechanism curve decays as $1/\sqrt{N}$ and crosses the $5\%$-of-first-best target at $N = 512$.
**Simulation harness.** Python, NumPy, scikit-learn. Approximately 240 CPU-hours on a single 16-core machine; no GPU required. Released alongside the paper under MIT license; full pseudocode in Appendix G of the PDF.
---
## 9. The August 2026 EU AI Act forcing function
The Paper #1 mapping to the [August 2, 2026 EU AI Act high-risk obligations](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689) establishes that the scoring-rule mechanism's probe set, verifier reports, and payment ledger together constitute auditable accept-rate evidence at the contractual threshold for one verifier. We revisit the mapping for composed pipelines.
**Per-component evidence is insufficient for composed pipelines.** Theorem 1 implies that the pipeline accept rate can drift from the per-component product by an amount up to $|C(x)|$. Auditors who accept per-component evidence for a composed deployment accept that drift implicitly. The drift is operationally large in the realistic regime: Section 8 measures $\bar C \in [0.05, 0.15]$ on synthesized process-plus-outcome verifier pairs, which shifts pipeline accept rate by 5 to 15 percentage points on positively-correlated pairs in the rank-1-aligned regime ([Ye et al., 2026](https://arxiv.org/abs/2605.06523)), with the corresponding Cost-correct gap scaling as $|\bar C| / (\alpha^{\mathrm{pipe}}_{\min})^2$. Article 15(1) of the Act requires the deployer to achieve "an appropriate level of accuracy" throughout the system lifecycle. Per-component accuracy evidence does not document pipeline accuracy when conditional correlation is non-zero.
**The joint-mechanism audit trail is the correct compliance artifact for composed deployments.** The joint-report ledger of Section 5 documents the empirical joint distribution over $(V_{k_1}, V_{k_2})$ on the probe set. The identifiability check of Proposition 1 documents that the joint distribution is identified from the probe distribution. Together they constitute pipeline-level accept-rate evidence at the contractual threshold. The audit trail is the forward extension of [Burnat and Davidson (2026)](https://arxiv.org/abs/2605.06340)'s continuous-compliance auditee-gaming framework to the multi-component-verifier setting. A deployer who runs per-verifier audits on a composed pipeline can game the audit by selecting pairs with favorable marginals and unfavorable joint behavior; the joint-report audit prevents this attack.
**Article 13 transparency.** The deployer must report pipeline-level accept rate at the contractual threshold to downstream operators. The joint mechanism produces $\hat \alpha^{\mathrm{pipe}}$ as a primitive on the probe set; the reporting interface follows directly.
We do not claim the joint mechanism is sufficient for Act compliance overall, since the Act covers risk management and human oversight beyond accept-rate measurement. We claim only that, where the Act requires accept-rate evidence on a composed pipeline, the joint mechanism produces it as a side effect and at low marginal cost relative to per-component audits.
---
## 10. Limitations and future work
**Two-verifier scope.** The composition identity extends to monotone Boolean rules of arity three and above by inclusion-exclusion (Appendix A of the PDF), but the joint scoring rule on $\{0, 1\}^J$ for $J$ slots faces a combinatorial blowup in the joint report space, from four cells at $J = 2$ to $2^J$ cells at $J = 3$ and beyond. Three-slot composition (PRM plus outcome verifier plus LLM judge) is the natural near-term target.
**Static verifier population.** Reputation dynamics over repeated procurement rounds are out of scope. The natural extension connects to [Xu and Park (2026)](https://arxiv.org/abs/2605.06612) on online Bayesian calibration under gradual and abrupt system changes, and to the moral-hazard structure of [Holmström (1979)](https://doi.org/10.2307/3003320) applied to the joint-report setting.
**Programmatic-verifier scope.** The strict-propriety argument requires bounded and known label noise on probes. Math, formal logic, and code with strict tests satisfy this. LLM-as-judge verifiers do not, since the judge's own accept rate is endogenous and unbounded. The rubric-grounded RL framework of [Bhattarai et al. (2026)](https://arxiv.org/abs/2605.08061) decomposes the judge's reward into weighted verifiable criteria; the joint-mechanism extension to rubric-judges with bounded per-criterion label noise is a natural next step.
**Single deployer.** Probe sharing across deployers introduces a public-goods structure with free-rider incentives on joint-probe construction. The natural extension is paper #3 in the wedge plan, with the bilateral-trade impossibility of [Myerson and Satterthwaite (1983)](https://doi.org/10.1016/0022-0531\(83\)90048-0) applied to the joint-probe-as-public-good setting.
**Calibration-monotone-pair assumption.** The lower bound of Theorem 5 requires calibration-monotone-pair $\mathcal{F}_1 \times \mathcal{F}_2$. The upper bound of Theorem 4 does not. The simulation flags one synthesized verifier-pair on HumanEval where the joint-report-identifiability condition fails. The worst-case regret on non-identifiable families is an open problem.
**Time-varying joint correlation.** $\bar C$ is treated as a static unknown in this paper. Drift in $\bar C$ over the deployer's task distribution introduces an online-procurement structure that builds on [Xu and Park (2026)](https://arxiv.org/abs/2605.06612).
---
## 11. Conclusion
Paper #1 procures one verifier. This paper procures the composed pipeline. The composition identity gives a clean picture of why per-verifier elicitation does not transfer. Pipeline miscalibration under per-verifier elicitation is exactly the within-instance verifier-disagreement covariance. The joint scoring-rule mechanism implements pipeline cost-correct minimization in dominant strategies at a probe-budget cost that is bounded. Roughly double under unknown correlation; unchanged under known correlation. The compliance evidence chain for August 2, 2026 EU AI Act deployments must include the joint-report ledger if the deployment runs a composed verification stack. Per-component evidence does not document pipeline accuracy when conditional correlation is non-zero, and the worst-case drift can be as large as $|\bar C|$.
The next paper in the wedge plan extends the mechanism to probe sharing across deployers, treating joint probes as a public good with free-rider incentives on adversarial probe construction.
---
## Appendices (in the PDF)
The PDF includes eight appendices with full proofs and additional material.
- **Appendix A.** Composition identity for general monotone Boolean rules. Inclusion-exclusion expansions for two- and three-verifier cases, including OR, AND, majority, and the third joint cumulant.
- **Appendix B.** Full proof of Theorem 2 (non-implementability under per-verifier elicitation) including the payoff-equivalence argument.
- **Appendix C.** Full proof of Theorem 4 (upper bound) with the split-at-$u_0$ tail integration and the absolute constant.
- **Appendix D.** Le Cam packing for Theorem 5 (lower bound).
- **Appendix E.** Proof of Proposition 3 (conditional-rare-event probes).
- **Appendix F.** Verifier-pair synthesis with prescribed conditional correlation. Calibration of the shared-latent coupling parameter.
- **Appendix G.** Simulation pseudocode.
- **Appendix H.** Notation summary.
---
## References
1. [Bhardwaj, M. *Verifier Procurement Under Unobservable Quality. A Scoring-Rule Mechanism for Cost-Correct Minimization.* Research Paper #1, verification-economics wedge. ifitsmanu.com, 2026.](/papers/verifier-procurement)
2. [Bhardwaj, M. *The Cost of Being Right. Verification Economics in 2026.* Field Notes #2. ifitsmanu.com, 2026.](/papers/the-cost-of-being-right)
3. [Bhardwaj, M. *The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.* Field Notes #3. ifitsmanu.com, 2026.](/papers/the-alpha-asymmetry)
4. [Bhattarai, M., Boureima, I., Ranasinghe, N. R., Pakin, S., O'Malley, D. *Rubric-Grounded RL. Structured Judge Rewards for Generalizable Reasoning.* arXiv:2605.08061, 2026.](https://arxiv.org/abs/2605.08061)
5. [Burnat, F. A. D., Davidson, B. I. *A Benchmark for Strategic Auditee Gaming Under Continuous Compliance Monitoring.* arXiv:2605.06340, 2026.](https://arxiv.org/abs/2605.06340)
6. [Chen, M., Tworek, J., Jun, H., Yuan, Q., et al. *Evaluating Large Language Models Trained on Code.* arXiv:2107.03374, 2021.](https://arxiv.org/abs/2107.03374)
7. [Cobbe, K., Kosaraju, V., Bavarian, M., et al. *Training Verifiers to Solve Math Word Problems.* arXiv:2110.14168, 2021.](https://arxiv.org/abs/2110.14168)
8. Cover, T. M., Thomas, J. A. *Elements of Information Theory.* 2nd edition, Wiley-Interscience, 2006.
9. [Dasgupta, A., Ghosh, A. *Crowdsourced Judgement Elicitation with Endogenous Proficiency.* WWW '13, ACM, 2013.](https://doi.org/10.1145/2488388.2488417)
10. [European Parliament and Council. *Regulation (EU) 2024/1689 on Artificial Intelligence (AI Act).* OJ EU, 12 July 2024. High-risk obligations apply from 2 August 2026.](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689)
11. [Frongillo, R., Kash, I. A. *General Truthfulness Characterizations Via Convex Analysis.* Games and Economic Behavior 130, 636–662, 2021.](https://doi.org/10.1016/j.geb.2021.07.001)
12. [Gneiting, T., Raftery, A. E. *Strictly Proper Scoring Rules, Prediction, and Estimation.* JASA 102(477), 359–378, 2007.](https://doi.org/10.1198/016214506000001437)
13. Grimmett, G., Welsh, D. *Probability: An Introduction.* 2nd edition, Oxford University Press, 2014.
14. [Guan, X., Zhang, L. L., Liu, Y., et al. *rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking.* arXiv:2501.04519, 2025.](https://arxiv.org/abs/2501.04519)
15. [Hendrycks, D., Burns, C., Kadavath, S., et al. *Measuring Mathematical Problem Solving With the MATH Dataset.* NeurIPS 2021 Datasets and Benchmarks.](https://arxiv.org/abs/2103.03874)
16. [Hoeffding, W. *Probability Inequalities for Sums of Bounded Random Variables.* JASA 58(301), 13–30, 1963.](https://doi.org/10.2307/2282952)
17. [Holmström, B. *Moral Hazard and Observability.* Bell Journal of Economics 10(1), 74–91, 1979.](https://doi.org/10.2307/3003320)
18. [Karnin, Z., Koren, T., Somekh, O. *Almost Optimal Exploration in Multi-Armed Bandits.* ICML 2013.](https://proceedings.mlr.press/v28/karnin13.html)
19. [Kong, Y., Schoenebeck, G. *An Information Theoretic Framework for Designing Information Elicitation Mechanisms That Reward Truth-Telling.* ACM TEAC 7(1), 2019.](https://doi.org/10.1145/3296670)
20. [Le Cam, L. *Convergence of Estimates Under Dimensionality Restrictions.* Annals of Statistics 1(1), 38–53, 1973.](https://www.jstor.org/stable/2958077)
21. [Lightman, H., Kosaraju, V., Burda, Y., et al. *Let's Verify Step by Step.* ICLR 2024 / arXiv:2305.20050, 2023.](https://arxiv.org/abs/2305.20050)
22. [Lovén, L. *Honest Reporting in Scored Oversight. True-KL0 Property via the Prekopa Principle.* arXiv:2605.03793, 2026.](https://arxiv.org/abs/2605.03793)
23. [Miller, N., Resnick, P., Zeckhauser, R. *Eliciting Informative Feedback. The Peer-Prediction Method.* Management Science 51(9), 1359–1373, 2005.](https://doi.org/10.1287/mnsc.1050.0379)
24. [Myerson, R. B. *Optimal Auction Design.* Mathematics of Operations Research 6(1), 58–73, 1981.](https://doi.org/10.1287/moor.6.1.58)
25. [Myerson, R. B., Satterthwaite, M. A. *Efficient Mechanisms for Bilateral Trading.* J. Economic Theory 29(2), 265–281, 1983.](https://doi.org/10.1016/0022-0531\(83\)90048-0)
26. Tsybakov, A. B. *Introduction to Nonparametric Estimation.* Springer Series in Statistics, 2009.
27. [Uesato, J., Kushman, N., Kumar, R., et al. *Solving Math Word Problems With Process- and Outcome-Based Feedback.* arXiv:2211.14275, 2022.](https://arxiv.org/abs/2211.14275)
28. [Wang, X., Wei, J., Schuurmans, D., et al. *Self-Consistency Improves Chain of Thought Reasoning in Language Models.* ICLR 2023 / arXiv:2203.11171, 2022.](https://arxiv.org/abs/2203.11171)
29. [Witkowski, J., Parkes, D. C. *A Robust Bayesian Truth Serum for Small Populations.* AAAI 2012.](https://ojs.aaai.org/index.php/AAAI/article/view/8359)
30. [Xu, Y., Park, C. *Online Bayesian Calibration under Gradual and Abrupt System Changes.* arXiv:2605.06612, 2026.](https://arxiv.org/abs/2605.06612)
31. [Ye, H., Dang, J., Fang, J., et al. *On the Implicit Reward Overfitting and the Low-rank Dynamics in RLVR.* arXiv:2605.06523, 2026.](https://arxiv.org/abs/2605.06523)
32. [Zheng, L., Chiang, W.-L., Sheng, Y., et al. *Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.* NeurIPS 2023.](https://arxiv.org/abs/2306.05685)
---
Cite this article
@misc{bhardwaj2026verifiercomposition,
author = {Bhardwaj, Manu},
title = {Calibration Drift Under Verifier Composition: A Joint Scoring-Rule Mechanism for Pipeline-Level Cost-Correct Minimization},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/verifier-composition},
howpublished = {\url{https://ifitsmanu.com/papers/verifier-composition/paper.pdf}},
note = {Working paper. Version 1.0. Research Paper #2 in the verification-economics wedge.}
}
Bhardwaj, M. (2026, May). Calibration drift under verifier composition: A joint scoring-rule mechanism for pipeline-level cost-correct minimization. ifitsmanu.com. https://ifitsmanu.com/papers/verifier-composition
Bhardwaj, Manu. "Calibration Drift Under Verifier Composition: A Joint Scoring-Rule Mechanism for Pipeline-Level Cost-Correct Minimization." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/verifier-composition.
M. Bhardwaj, "Calibration Drift Under Verifier Composition: A Joint Scoring-Rule Mechanism for Pipeline-Level Cost-Correct Minimization," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/verifier-composition
---
[Companion. Verifier Procurement.](/papers/verifier-procurement) [Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Companion. The α Asymmetry.](/papers/the-alpha-asymmetry) [Papers index](/papers). [Home](/).
# https://ifitsmanu.com/papers/inference-frontier/
# The Inference-Time Compute Frontier.
### A Cost-Correct Threshold for Training Versus Test-Time Allocation.
*Manu Bhardwaj. ifitsmanu.com. May 2026. Version 1.0. Research Paper #2 in the inference-economics wedge.*
[Download as PDF](/papers/inference-frontier/paper.pdf) (full proofs, figures, calibration tables). [LaTeX source](/papers/inference-frontier/paper.tex). [BibTeX of references](/papers/inference-frontier/references.bib). [Cite this article](#cite-this-article). [Papers index](/papers).
> **Companion to the verification-economics field notes.** [*The Cost of Being Right.*](/papers/the-cost-of-being-right) (Field Notes #2) develops the Cost-correct decomposition. [*The α Asymmetry.*](/papers/the-alpha-asymmetry) (Field Notes #3) shows verifier accept rate dominates the other cost levers. [*Verifier Procurement Under Unobservable Quality.*](/papers/verifier-procurement) (Research Paper #1) closes the gap when the deployer must buy rather than build. This paper answers a different question: given that you are building, when should the next dollar go to more rollouts rather than more training?
Or view the full PDF inline.
Abstract
When does an additional dollar of compute reduce cost-per-correct-answer faster when spent on inference-time scaling than when spent on further training? Snell et al. (2024) and Brown et al. (2024) show that test-time compute can substitute for training compute on hard reasoning tasks, and Guan et al. (2025) show that verifier-guided rollouts let small models match flagship reasoners. What none of them give is an economic threshold that says where the substitution holds. We derive one. Under the *Cost-correct* decomposition of [*The Cost of Being Right*](/papers/the-cost-of-being-right), with verifier accept rate parameterized jointly in training compute $T$ and rollout count $\rho$, the marginal dollar reduces cost-per-correct-answer faster on the inference channel iff $(\eta_\alpha^\rho - 1)/\eta_\alpha^T$ exceeds the inference-to-training dollar ratio at the operating point. We calibrate the threshold against rStar-Math, DeepSeek-R1, and the published test-time-compute curves of Snell et al. (2024) and Brown et al. (2024), and show that the calibration matches the observed market split between frontier reasoning tiers and commodity tiers.
---
## 1. Introduction
Frontier reasoning models in 2025 ship with explicit thinking budgets. rStar-Math couples a 7B generator with a 7B process-reward verifier and Monte-Carlo Tree Search rollouts to beat o1-preview on AIME 2024 and MATH at a fraction of the inference dollar ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)). DeepSeek-R1 lifts pass@1 on the same benchmarks through reinforcement learning with verifiable-reward signals at fixed rollout count ([DeepSeek-AI, 2025](https://arxiv.org/abs/2501.12948)). OpenAI's o-series and the GPT-5.5 launch in April 2026 advertise per-query reasoning budgets as a first-class API parameter. Commodity tiers do not. GPT-5.4 nano, Gemini Flash, and Claude Haiku 4.5 ship without rollout budgets and serve a workload mix dominated by retrieval and short-form generation.
Two features of this split are striking. First, the split is sharp. There is no continuous gradient of "small thinking budget" tiers in the market; either a model deploys explicit inference-time scaling or it does not. Second, the split is recent. As late as 2024, even frontier providers shipped without dedicated rollout budgets, and the available economic frame was the Chinchilla compute-optimal training-data ratio of [Hoffmann et al. (2022)](https://arxiv.org/abs/2203.15556). The frame has since shifted to a question that the Chinchilla setup does not answer: where on the joint training-and-inference frontier should the next compute dollar go?
[Snell et al. (2024)](https://arxiv.org/abs/2408.03314) and [Brown et al. (2024)](https://arxiv.org/abs/2407.21787) answer the related question of *substitutability* but not the question of *allocation*. Snell et al. show on PaLM-2 that test-time compute can replace 14 times more pre-training compute on hard reasoning subsets. Brown et al. show on Llama-class models that pass@k under repeated sampling scales as an exponential decay in compute and that the curve crosses the parameter-scaling curve at a benchmark-dependent crossover. Both papers fix the verifier and report accuracy versus compute curves. Neither casts the result as a cost-allocation problem with explicit verifier construction cost, and neither isolates the conditions under which substitution holds.
This paper supplies the missing economic threshold. The contribution is a closed-form condition under which the marginal dollar reduces cost-per-correct-answer faster on the inference channel than on the training channel, expressed in three observable parameters: the elasticity of verifier accept rate with respect to rollout count, the elasticity of accept rate with respect to training compute, and the inference-to-training dollar ratio at the operating point. The threshold derives from the Cost-correct decomposition and the verifier-dominance result of [*The α Asymmetry*](/papers/the-alpha-asymmetry). It requires modeling the verifier accept rate as a joint function of both compute channels, taking partial derivatives in both, and identifying a closed-form switching condition.
We calibrate the threshold against four operating points. The threshold is crossed at the hard-difficulty subsets reported by Snell et al. and Brown et al.; it is not crossed at the easy subsets in the same papers, nor at the workload mixes implied by commodity-tier deployments. rStar-Math holds $T$ fixed at 7B and runs $\rho$ past the cost-correct optimum to chase headline accuracy on AIME 2024. DeepSeek-R1 sits at $\rho = 1$ where the threshold predicts the inference channel cannot clear the bar given the very high $\eta_\alpha^T$ the verifiable-reward RL stage realizes on the V3 base. The pattern matches the observed market split.
---
## 2. Related work
**Inference-time scaling.** [Snell et al. (2024)](https://arxiv.org/abs/2408.03314) study optimal allocation of test-time compute across rollouts, revisions, and search depth on PaLM-2. [Brown et al. (2024)](https://arxiv.org/abs/2407.21787) study repeated sampling on Llama and Pythia across HumanEval, MATH, GSM8K, and MiniF2F. Both papers hold the verifier fixed and treat it as an oracle. Neither incorporates verifier construction cost or partitions a budget across the training and inference channels.
**Cost-of-pass and cost-correct.** [Erol et al. (2026)](https://openreview.net/forum?id=vC9S20zsgN) introduce *Cost-of-Pass* as a per-accepted-correct-answer metric. [*The Cost of Being Right*](/papers/the-cost-of-being-right) develops the multiplicative Cost-correct decomposition that separates cost-per-million-tokens, the reasoning multiplier, the rollout ratio, and the verifier accept rate. [*The α Asymmetry*](/papers/the-alpha-asymmetry) shows the partial derivative of Cost-correct with respect to $\alpha$ dominates the other partials in production regimes. None study allocation across training and inference channels.
**Compute-optimal training.** [Kaplan et al. (2020)](https://arxiv.org/abs/2001.08361) and [Hoffmann et al. (2022)](https://arxiv.org/abs/2203.15556) establish single-channel scaling laws. The Chinchilla frontier optimizes training compute at a single inference operating point. It does not extend to a regime in which the next dollar can be allocated to inference-time rollouts that lift verifier accept rate.
A separate body of work on outcome- and process-reward verifiers ([Cobbe et al. (2021)](https://arxiv.org/abs/2110.14168) introduced outcome-reward verifiers on GSM8K; [Lightman et al. (2023)](https://arxiv.org/abs/2305.20050) drew the explicit ORM-vs-PRM distinction and showed step-level process-reward signals dominate on MATH) and verifier-guided decoding ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)) supplies the empirical content of the elasticity calibrations in Section 4.
---
## 3. Method
### 3.1. Cost-correct, restated
We work in the Cost-correct framework. The unit cost of a correct answer is
$$
C \;=\; \frac{\mathrm{CPM}_{1:1} \cdot R \cdot (1 + \bar\rho)}{\alpha},
\qquad (1)
$$
where $\mathrm{CPM}_{1:1}$ is the blended cost per million tokens at a unit input-to-output ratio, $R$ is the reasoning multiplier (output tokens per accepted answer), $\bar\rho$ is the average rollout ratio, and $\alpha \in (0, 1]$ is the verifier accept rate. The α-asymmetry result establishes that
$$
\Big| \tfrac{\partial \log C}{\partial \log \alpha} \Big|
\;=\; 1
\;\geq\; \Big| \tfrac{\partial \log C}{\partial \log x} \Big|,
\qquad x \in \{\mathrm{CPM}_{1:1}, R, \bar\rho\},
\qquad (2)
$$
with equality approached in the high-rollout limit $\bar\rho \to \infty$, where $\partial \log C / \partial \log \bar\rho = \bar\rho/(1+\bar\rho) \to 1$. This asymmetry makes verifier accept rate the natural pivot for a two-channel allocation rule.
### 3.2. Two-channel parameterization
Let $T$ denote post-training compute spent on the generator (in FLOP-units) and $\rho$ denote rollout count per query. We parameterize the verifier accept rate as
$$
\alpha(T, \rho) \;=\; g\bigl(\alpha_0(T),\, h(\rho)\bigr),
\qquad (3)
$$
where $\alpha_0(T)$ is the base accept rate of an unfiltered single rollout and $h(\rho)$ is the verifier lift from selecting the best of $\rho$ rollouts under a fixed verifier. We adopt the separability assumption
$$
\log \alpha(T, \rho) \;=\; \log \alpha_0(T) + h(\rho),
\qquad (4)
$$
and define the elasticities
$$
\eta_\alpha^T \;\equiv\; \frac{\partial \log \alpha}{\partial \log T},
\qquad
\eta_\alpha^\rho \;\equiv\; \frac{\partial \log \alpha}{\partial \log \rho}.
\qquad (5)
$$
Under (4) the cross-partial $\partial^2 \log \alpha / \partial \log T \, \partial \log \rho$ vanishes. Separability is justified empirically when verifier-guided selection acts on a fixed generator distribution that has already absorbed the post-training lift, as in best-of-N reranking with a frozen process-reward model.
### 3.3. Cost ratio and budget constraint
Let $c_T$ denote the marginal cost of one unit of post-training FLOP, amortized over the expected query lifetime $Q$, and $c_I$ the marginal cost of one unit of inference FLOP per query. Define
$$
\nu \;\equiv\; \frac{c_T}{c_I}.
\qquad (6)
$$
Under public price points and the price-of-progress dataset of [Liao et al. (2025)](https://arxiv.org/abs/2511.23455), $\nu$ at the frontier operating point in 2026 is on the order of $10^{-5}$ to $10^{-4}$ per query when amortized over a generator's commercial lifetime. The operationally relevant quantity is the dollar ratio $\mu \equiv (T \cdot c_T) / (\rho \cdot c_I)$ at the operating point.
### 3.4. The threshold theorem
The inference channel clears the threshold when the rollout-net-of-cost elasticity ratio exceeds the inference-to-training dollar ratio at the operating point.
We state the result in the rollout-dominant regime where $\rho \gg 1$ so that $(1 + \rho) \approx \rho$. The general statement appears in Appendix A.
**Theorem (Threshold).** *At an interior operating point $(T, \rho)$ with $\rho \gg 1$ under separability (4) and the cost ratio (6), the marginal dollar reduces cost-per-correct-answer faster on the inference channel than on the training channel iff*
$$
\frac{\eta_\alpha^\rho \;-\; 1}{\eta_\alpha^T} \;>\; \frac{\rho \cdot c_I}{T \cdot c_T}
\;=\; \frac{1}{\mu}.
\qquad (7)
$$
*Proof.* Take logs of (1). The fractional reduction in $C$ from a 1% increase in $T$ is $\eta_\alpha^T$, at a dollar cost of $0.01 \cdot T \cdot c_T$. The fractional reduction in $C$ from a 1% increase in $\rho$ is $\eta_\alpha^\rho - 1$, at a dollar cost of $0.01 \cdot \rho \cdot c_I$. Per-dollar log-reductions:
$$
g_T \;=\; \frac{\eta_\alpha^T}{T \cdot c_T},
\qquad
g_\rho \;=\; \frac{\eta_\alpha^\rho - 1}{\rho \cdot c_I}.
\qquad (10)
$$
The inference channel dominates iff $g_\rho > g_T$. Cross-multiplying gives (7). $\square$
The theorem partitions the $(T, \rho)$ plane into a training-dominated region and an inference-dominated region. The optimum lies on the boundary, where (7) holds with equality. The right-hand side is observable from the deployment cost ledger. The left-hand side is the *rollout-net-of-cost elasticity ratio*: it credits rollouts only for the lift in $\alpha$ above the per-rollout cost $\rho/(1+\rho)$, which in the rollout-dominant regime is unity.
### 3.5. Comparative statics
Three corollaries follow directly from (7).
**Corollary 1 (frontier ceiling).** As $\alpha_0 \to 1$ at fixed verifier, $\eta_\alpha^T \to 0$. The right-hand side of (7) is bounded; the left-hand side grows without bound. Frontier-difficulty subsets satisfy the threshold; easy subsets do not.
**Corollary 2 (reasoning multiplier).** Tasks with high $R$ magnify the absolute dollar return to either channel. Combined with the α-asymmetry result, reasoning-heavy workloads favor inference-time allocation; retrieval-heavy workloads do not.
**Corollary 3 (amortization).** When $Q$ is large, $\nu$ falls and $\mu$ rises, so the inference channel must clear a lower bar to dominate. This predicts that high-throughput commodity tiers serving long-lived workloads do not deploy thinking budgets, because the cost-per-correct-answer reduction from rollouts on easy tasks is too small to clear even the lowered bar.
---
## 4. Experiments
This section calibrates the threshold (7) against four operating points. All numbers are cited from primary sources; we report no new measurements.
### 4.1. rStar-Math (Microsoft Research, January 2025)
[Guan et al. (2025)](https://arxiv.org/abs/2501.04519) report a Qwen2.5-Math-7B generator paired with a 7B process-reward verifier and MCTS rollouts. The deployed configuration runs $\rho = 64$ rollouts per query, reporting pass@1 of $0.533$ on AIME 2024 and $0.900$ on MATH-500.
The secant elasticity over the in-MCTS sweep $\rho = 8 \to 64$ on AIME 2024 is $\log(0.533/0.500)/\log(64/8) \approx 0.031$; on MATH-500 it is $\log(0.900/0.894)/\log(64/8) \approx 0.003$.
Substituting into (7): $(\eta_\alpha^\rho - 1)/\eta_\alpha^T = (0.031 - 1)/\eta_\alpha^T \approx -0.97/\eta_\alpha^T < 0$ for any positive $\eta_\alpha^T$. The inference channel does not clear the threshold at the deployed $\rho = 64$. rStar-Math optimized headline accuracy at fixed model scale, not cost-per-correct-answer; the deployed configuration sits inside the verifier-ceiling regime (Corollary 1). A cost-conscious redeployment would run at materially lower $\rho$, trading accuracy for cost-per-correct-answer reduction.
### 4.2. DeepSeek-R1 (DeepSeek-AI, January 2025)
[DeepSeek-AI (2025)](https://arxiv.org/abs/2501.12948) lift pass@1 on AIME 2024 from $0.392$ (DeepSeek-V3 base) to $0.798$ (DeepSeek-R1) through RL with verifiable-reward signals at fixed rollout count ($\rho = 1$).
DeepSeek does not disclose RL post-training compute as a fraction of V3 pre-training. Under a sensitivity bracket $s = \Delta T / T_{V3} \in [0.01, 0.10]$, the implied training-channel elasticity on AIME 2024 is $\log(0.798/0.392)/\log(1+s) \in [7.5, 71]$.
For the inference channel to clear (7) at R1 would require $(\eta_\alpha^\rho - 1)/\eta_\alpha^T > 1/\mu$, meaning $\eta_\alpha^\rho \gtrsim 8$ to $71$, implausible for any published verifier on AIME 2024. The corner solution $\rho = 1$ is therefore consistent with (7) across the full sensitivity bracket.
### 4.3. Test-time-compute curves (Snell et al. 2024; Brown et al. 2024)
The hard-subset regime in [Snell et al. (2024)](https://arxiv.org/abs/2408.03314) corresponds to $\alpha_0$ far from 1 and $\eta_\alpha^\rho$ in the 0.5–1.0 range. The 14× substitution result implies $\eta_\alpha^\rho \cdot \mu \gg \eta_\alpha^T$, exactly the threshold (7) in its $\eta_\alpha^\rho \gg 1$ form. The easy-subset regime corresponds to $\alpha_0 \to 1$ and $\eta_\alpha^\rho \to 0$, where the threshold flips.
[Brown et al. (2024)](https://arxiv.org/abs/2407.21787) report the same pattern in pass@k form on Llama and Pythia. On hard benchmarks (MiniF2F, MATH-hard subsets), the exponent (the local $\eta_\alpha^\rho$ in our notation) is large and the substitution holds; on easy benchmarks the exponent is small and the substitution breaks. The crossover occurs precisely where $(\eta_\alpha^\rho - 1)/\eta_\alpha^T = 1/\mu$, which is (7) with equality.
### 4.4. Negative case: commodity tiers
At $\alpha_0 > 0.95$ on routine-task workloads (short-form generation, retrieval, classification), $\eta_\alpha^\rho$ is bounded above by $1 - \alpha_0 < 0.05$. The right-hand side of (7) is order unity. The threshold fails by an order of magnitude.
The prediction is that commodity tiers should not deploy explicit thinking budgets. They do not. The same prediction explains the absence of a continuous gradient of small-thinking-budget tiers between commodity and frontier.
Table 1. Threshold (7) calibration across four operating points. The threshold is crossed in the hard-reasoning regime and missed in all other cases, matching observed deployment choices.
Operating point
$\eta_\alpha^\rho$ (AIME 2024)
Threshold crossed?
Deployment fact
rStar-Math, $\rho = 64$
0.031 (secant)
No: $(\eta_\alpha^\rho - 1) < 0$
Fixed $T$, accuracy-optimized
DeepSeek-R1, $\rho = 1$
N/A ($\rho = 1$)
Consistent: corner $\rho = 1$
Training-channel RL allocation
Snell et al. hard subsets
0.5–1.0
Yes: 14× substitution
Test-time compute dominant
Commodity tiers
$< 0.05$
No: $\alpha_0 > 0.95$
No rollout budget deployed
---
## 5. Discussion
### 5.1. Capital allocation across the two channels
The threshold (7) gives a quantitative rule for where the next compute dollar should go. Frontier providers facing hard-reasoning workloads should mix, allocating to both channels along the boundary defined by equality in (7). Commodity providers facing easy-task workloads should allocate to the training channel only.
The observed market structure matches both predictions. The 2026 reasoning tier ships with thinking budgets that are themselves a tunable parameter: evidence that the provider sits on the boundary and lets the customer pick the operating point. Commodity tiers ship without rollout budgets at all: evidence that the provider sits well inside the training-dominated region.
### 5.2. The GPT-5.5 reprice as a falsifiable hypothesis
OpenAI raised GPT-5.5 prices by 100% over GPT-5.4 in April 2026. Under (1), a price increase at fixed $\mathrm{CPM}_{1:1}$ requires a fall in $\alpha$, a rise in $R$, or a rise in $\bar\rho$. The threshold theorem rationalizes the move only if the GPT-5.5 workload mix has shifted toward harder reasoning tasks where the inference-channel allocation share has risen. This is consistent with OpenAI's published statement on GPT-5.5 thinking budgets.
The hypothesis is falsifiable: if a future GPT-5.5 disclosure shows flat or falling rollout share on a workload mix shifted toward easy tasks, a competing explanation is required.
### 5.3. Limitations
*Separability assumption.* If $\eta_\alpha^\rho$ depends materially on $T$ (the verifier and generator have not absorbed each other's progress), the cross-partial does not vanish and (7) holds only locally. A broader calibration tracing non-separability is future work.
*Fixed verifier construction cost.* We have treated verifier construction cost as amortized over the verifier's lifetime. If the verifier does not transfer across tasks, the fixed-cost approximation breaks and the threshold shifts toward training-channel allocation.
*Three-point calibration.* A population-level calibration with the full 2024–2026 reasoning-model release sequence would tighten the elasticity estimates.
---
## 6. Conclusion
Inference-time scaling and training compute are substitutes on hard reasoning tasks, but allocation is a different question from substitutability. We have derived a closed-form threshold under the Cost-correct decomposition that says when the next dollar reduces cost-per-correct-answer faster on the inference channel than on the training channel, calibrated the threshold against four operating points, and shown that the calibration matches the observed market split between frontier reasoning and commodity tiers.
The next paper in the sequence relaxes the separability assumption by treating verifier portability as the primary object of study.
---
## Appendix A. Full proof of the threshold theorem
**Theorem (Threshold, general).** *At an interior operating point $(T, \rho)$ under separability (4) and cost ratio (6), the marginal dollar reduces $C$ faster on the inference channel iff*
$$
\frac{\eta_\alpha^\rho \;-\; \tfrac{\rho}{1+\rho}}{\eta_\alpha^T}
\;>\;
\frac{\rho \cdot c_I}{T \cdot c_T}.
\qquad (\mathrm{A.1})
$$
*Proof.* From differentiating (8),
$$
\frac{\partial \log C}{\partial T} = -\frac{\eta_\alpha^T}{T},
\qquad
\frac{\partial \log C}{\partial \rho}
= \frac{1}{1+\rho} - \frac{\eta_\alpha^\rho}{\rho}.
\qquad (\mathrm{A.2})
$$
The fractional change in $C$ per dollar on the training channel is $\eta_\alpha^T / (T \cdot c_T)$. The fractional change in $C$ per dollar on the inference channel is $(\eta_\alpha^\rho/\rho - 1/(1+\rho)) / c_I$. Setting the inference rate strictly greater than the training rate and rearranging gives (A.1). The $\rho \gg 1$ limit gives $\rho/(1+\rho) \to 1$, recovering (7). $\square$
**Corollary (boundary curvature).** The boundary surface where (A.1) holds with equality is concave in the rollout-dominant regime; the iso-cost-correct curves in the same plane are convex; the optimum lies at the unique tangent point.
---
## Appendix B. Calibration tables
**Table B.1.** rStar-Math operating points. Source: Guan et al. (2025), Table 5.
Model
Benchmark
$\rho$
pass@1
Notes
Qwen2.5-Math-7B base
AIME 2024
1
0.000
base generator, no MCTS
Qwen2.5-Math-7B base
MATH-500
1
0.588
base generator, no MCTS
rStar-Math (7B + 7B PRM)
AIME 2024
8
0.500
in-MCTS
rStar-Math (7B + 7B PRM)
MATH-500
8
0.894
in-MCTS
rStar-Math (7B + 7B PRM)
AIME 2024
64
0.533
deployed
rStar-Math (7B + 7B PRM)
MATH-500
64
0.900
deployed
**Table B.2.** DeepSeek-R1 vs DeepSeek-V3 base at $\rho = 1$. Source: DeepSeek-AI (2025), Table 4.
Model
Benchmark
$\rho$
pass@1
Notes
DeepSeek-V3 base
AIME 2024
1
0.392
Pre-RL baseline
DeepSeek-R1-Zero
AIME 2024
1
0.710
Pure RL, no SFT
DeepSeek-R1
AIME 2024
1
0.798
Post verifiable-reward RL
DeepSeek-V3 base
MATH-500
1
0.902
Pre-RL baseline
DeepSeek-R1
MATH-500
1
0.973
Post verifiable-reward RL
**Table B.3.** Snell et al. (2024) headline substitution result on PaLM-2-S MATH subsets.
Subset
Substitution ratio (test-time / pre-training)
Threshold prediction
Hard MATH
14×
Crosses threshold
Easy MATH
<1×
Does not cross
**Table B.4.** Commodity-tier deployments (negative case). Source: Field Notes #1.
Model
Workload
$\bar\rho$ deployed
$\alpha$ on workload
GPT-5.4 nano
Retrieval / short-form
1
>0.95
Gemini Flash
Retrieval / short-form
1
>0.95
Claude Haiku 4.5
Retrieval / short-form
1
>0.95
---
## References
1. [Bhardwaj, M. *The Cost of Being Right. Verification Economics in 2026.* Field Notes #2. ifitsmanu.com, 2026.](/papers/the-cost-of-being-right)
2. [Bhardwaj, M. *The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.* Field Notes #3. ifitsmanu.com, 2026.](/papers/the-alpha-asymmetry)
3. [Bhardwaj, M. *The Inference Stack in 2026.* Field Notes #1. ifitsmanu.com, 2026.](/papers/the-inference-stack-2026)
4. [Brown, B. et al. *Large Language Monkeys: Scaling Inference Compute with Repeated Sampling.* arXiv:2407.21787, 2024.](https://arxiv.org/abs/2407.21787)
5. [Cobbe, K. et al. *Training Verifiers to Solve Math Word Problems.* arXiv:2110.14168, 2021.](https://arxiv.org/abs/2110.14168)
6. [DeepSeek-AI. *DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.* arXiv:2501.12948, 2025.](https://arxiv.org/abs/2501.12948)
7. [Erol, U. et al. *The Cost of Being Right: Evaluating Language Models by the Cost-of-Pass.* ICLR 2026.](https://openreview.net/forum?id=vC9S20zsgN)
8. [Guan, X. et al. *rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking.* arXiv:2501.04519, 2025.](https://arxiv.org/abs/2501.04519)
9. [Hoffmann, J. et al. *Training Compute-Optimal Large Language Models.* arXiv:2203.15556, 2022.](https://arxiv.org/abs/2203.15556)
10. [Kaplan, J. et al. *Scaling Laws for Neural Language Models.* arXiv:2001.08361, 2020.](https://arxiv.org/abs/2001.08361)
11. [Liao, Y. et al. *The Price of Progress: Tracking the Declining Cost of Computing, AI, and Other Transformative Technologies.* arXiv:2511.23455, 2025.](https://arxiv.org/abs/2511.23455)
12. [Lightman, H. et al. *Let's Verify Step by Step.* arXiv:2305.20050, 2023.](https://arxiv.org/abs/2305.20050)
13. [Snell, C. et al. *Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Model Parameters.* arXiv:2408.03314, 2024.](https://arxiv.org/abs/2408.03314)
14. [Stanford Human-Centered AI Institute. *AI Index Report 2025.* Stanford University, 2025.](https://hai.stanford.edu/ai-index/2025-ai-index-report)
---
Cite this article
@misc{bhardwaj2026inferencetimefrontier,
author = {Bhardwaj, Manu},
title = {The Inference-Time Compute Frontier: A Cost-Correct Threshold for Training Versus Test-Time Allocation},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/inference-frontier},
howpublished = {\url{https://ifitsmanu.com/papers/inference-frontier/paper.pdf}},
note = {Working paper. Version 1.0.}
}
Bhardwaj, M. (2026, May). The inference-time compute frontier: A cost-correct threshold for training versus test-time allocation. ifitsmanu.com. https://ifitsmanu.com/papers/inference-frontier
Bhardwaj, Manu. "The Inference-Time Compute Frontier: A Cost-Correct Threshold for Training Versus Test-Time Allocation." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/inference-frontier.
M. Bhardwaj, "The Inference-Time Compute Frontier: A Cost-Correct Threshold for Training Versus Test-Time Allocation," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/inference-frontier
---
[Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Companion. The α Asymmetry.](/papers/the-alpha-asymmetry) [Companion. Verifier Procurement.](/papers/verifier-procurement) [Papers index](/papers). [Home](/).
# https://ifitsmanu.com/papers/routing-premium/
# The Routing Premium.
### An Economic Threshold for Difficulty-Conditional Inference Compute.
*Manu Bhardwaj. ifitsmanu.com. May 2026. Version 1.0. Research Paper #3 in the inference-economics wedge.*
[Download as PDF](/papers/routing-premium/paper.pdf) (full proofs, figures, calibration tables). [LaTeX source](/papers/routing-premium/paper.tex). [BibTeX of references](/papers/routing-premium/references.bib). [Cite this article](#cite-this-article). [Papers index](/papers).
> **Companion to Research Paper #2.** [*The Inference-Time Compute Frontier.*](/papers/inference-frontier) (Research Paper #2) derives the threshold for *which channel* (training versus inference) the next compute dollar should go. This paper answers the orthogonal question: given that some dollars are in inference, when does conditioning compute on a noisy difficulty estimate pay? The two thresholds compose multiplicatively.
Or view the full PDF inline.
Abstract
When does conditioning inference compute on a noisy estimate of task difficulty reduce cost-per-correct-answer relative to a fixed-compute baseline? Five published patterns route compute on a difficulty signal. Two operate at the per-token or per-layer level: speculative decoding ([Leviathan et al., 2023](https://arxiv.org/abs/2211.17192); [Cai et al., 2024](https://arxiv.org/abs/2401.10774)) and early-exit decoding ([Schuster et al., 2022](https://arxiv.org/abs/2207.07061)). Three operate at the per-query level: cascade routing ([Chen et al., 2023](https://arxiv.org/abs/2305.05176)), adaptive self-consistency ([Petullo et al., 2026a](https://arxiv.org/abs/2605.08070)), and complexity-aware exploration ([Petullo & Xue, 2026](https://arxiv.org/abs/2605.08057)). None derives the threshold above which the routing rule pays. We derive one. Under the *Cost-correct* decomposition of [*The Cost of Being Right*](/papers/the-cost-of-being-right), the routing premium is positive iff $\kappa \cdot \Delta > \gamma$ at the margin around the unconditional optimum, where $\kappa$ is classifier calibration, $\Delta$ is workload heterogeneity in compute, and $\gamma$ is classifier overhead. The condition unifies the five patterns as one allocation rule. We calibrate against six published systems spanning all five classes and find that every operating point sits on the positive side of the threshold. The elasticity reading isolates which operating points are close enough to fail under modest disclosure error.
---
## 1. Introduction
Adaptive inference is now a standard pattern. Speculative decoding routes tokens between a drafter and a verifier ([Leviathan et al., 2023](https://arxiv.org/abs/2211.17192); [Chen et al., 2023b](https://arxiv.org/abs/2302.01318); [Cai et al., 2024](https://arxiv.org/abs/2401.10774); [Li et al., 2024](https://arxiv.org/abs/2401.15077)). Cascade systems route prompts across model tiers ([Chen et al., 2023a](https://arxiv.org/abs/2305.05176); [Zhan, 2026](https://arxiv.org/abs/2605.08024)). Self-consistency systems prune candidate traces by semantic similarity ([Petullo et al., 2026a](https://arxiv.org/abs/2605.08070)). Tree-search systems vary exploration breadth by estimated complexity ([Petullo & Xue, 2026](https://arxiv.org/abs/2605.08057)). Early-exit decoders stop at confident layers ([Schuster et al., 2022](https://arxiv.org/abs/2207.07061)). All five report cost reductions at iso-accuracy. None reports the threshold under which the routing rule is rational.
The five literatures developed in parallel and have not been unified. A practitioner reading them in isolation sees five engineering tricks. Read together, they are five instances of one allocation rule: spend more compute on tasks the system thinks are hard, less on tasks it thinks are easy. The unifying object is a *difficulty-conditional compute policy*. The economic question is whether the difficulty classifier earns its cost.
We frame the question as a population-level allocation problem. A provider faces a workload distribution $F(d)$ over latent difficulties $d \in [0, 1]$. The provider can run a single fixed-compute policy at the unconditional optimum, or it can run a calibrated classifier and route each query to a difficulty-specific compute level. The router pays a classifier overhead. The question is when the savings from re-allocating compute across the workload exceed the classifier overhead at the margin.
The contribution is a closed-form threshold under Cost-correct. Routing pays iff
$$
\kappa \cdot \Delta \;>\; \gamma,
\qquad (1)
$$
where $\kappa$ is the explained-variance calibration quality of the classifier on the workload, $\Delta$ is a dimensionless measure of workload heterogeneity built from the second derivative of cost-per-correct-answer in compute, and $\gamma$ is the classifier overhead as a fraction of the unconditional inference cost. The threshold is local, holding to second order in the deviation $c(\hat d) - \bar c^*$ around the unconditional optimum $\bar c^*$. The five published patterns operate inside this local regime; we flag the cascade specialization where the local-margin assumption binds hardest and the third-order correction is non-trivial.
The contribution is non-trivial under the Cost-correct frame. The unconditional optimum $\bar c^*$ already minimizes expected cost; the routing premium is the *second-order* gain from re-allocating compute around that optimum, weighted by classifier calibration on the workload, net of classifier overhead. The threshold is a statement about a curvature-by-variance product, not a first-order gradient. It is orthogonal to the channel-allocation threshold of [*The Inference-Time Compute Frontier*](/papers/inference-frontier) (Research Paper #2), which fixes the *channel* (training versus inference) at a single representative query; the present threshold sets the *distribution within the inference channel* at a heterogeneous query mix. The two thresholds compose multiplicatively in production cost and Section 5 sketches the combined diagram.
We calibrate (1) against six published systems spanning all five allocation-rule classes. Table 1 in Section 4 reports the system-by-class mapping and the six-row calibration. Every operating point sits on the positive side of the threshold; CALM is the smallest margin and the natural sensitivity case. Section 5 turns the result into three implications for serving infrastructure design and identifies the disclosure gap that would let independent researchers falsify (1).
---
## 2. Related work
Four bodies of literature bear on the question. None derives the threshold. A fifth (the Cost-correct frame) supplies the cost decomposition the threshold leans on.
**Speculative decoding.** [Leviathan et al. (2023)](https://arxiv.org/abs/2211.17192) and [Chen et al. (2023b)](https://arxiv.org/abs/2302.01318) derive the expected speedup of a drafter-verifier scheme as a function of drafter accept rate and relative drafter cost. The derivation is per-token and within-sequence: the routing decision is the next-token verifier check, not a per-query allocation. [Cai et al. (2024)](https://arxiv.org/abs/2401.10774) and [Li et al. (2024)](https://arxiv.org/abs/2401.15077) tighten the drafter side with multi-head and tree-attention drafting and report higher accept rates on the same per-token frame. None of the four couples the analysis to cost-per-correct-answer or treats the drafter as a *workload-level* difficulty classifier.
**Cascade routing.** [Chen et al. (2023a)](https://arxiv.org/abs/2305.05176) builds a learned cascade across API tiers and reports cost reductions of up to 98% at iso-accuracy when matching GPT-4 on HEAD-QA, SUBJ, and COQA. The paper reports the empirical result; it does not derive the threshold under which the cascade beats a single-tier baseline. [Zhan (2026)](https://arxiv.org/abs/2605.08024) extends the cascade frame to human-in-the-loop deferral in medical imaging and reports a Pareto frontier in F1, MCC, and cost on the REFUGE, CHAKSU, and ORIGA glaucoma datasets. It inherits the same gap. [Kim et al. (2026)](https://arxiv.org/abs/2605.07985) provides background on profiling the per-tier compute footprint that any cascade calibration must lean on.
**Adaptive sampling and exploration.** [Petullo et al. (2026a)](https://arxiv.org/abs/2605.08070) prunes self-consistency candidates by semantic similarity and reports a 47% token reduction at iso-accuracy across math, chemistry, biology, commonsense, and humanities benchmarks. [Petullo and Xue (2026)](https://arxiv.org/abs/2605.08057) scales tree-search exploration breadth by estimated task complexity and reports 51.72% on the challenging tier of the BIRD development set using a GPT-4o-mini base. Both report empirical token-cost reductions. Neither derives the condition under which complexity-conditional compute is optimal. [Snell et al. (2024)](https://arxiv.org/abs/2408.03314) supplies the per-difficulty-bin compute-vs-accuracy curves that the calibration in Section 4 leans on for the workload-heterogeneity estimate.
**Early exit and adaptive depth.** [Schuster et al. (2022)](https://arxiv.org/abs/2207.07061) derives an exit threshold from a per-layer confidence signal inside the model and reports up to 3x speedups on T5 backbones at iso-accuracy on the CNN/DM, SQuAD, and WMT-EN-RO benchmarks. The exit threshold is a *local* version of difficulty-conditional compute: the classifier is the per-layer confidence head, the routing decision is per-layer rather than per-query, and the cost analysis is per-layer rather than per-correct-answer.
**Cost-correct frame.** [Erol et al. (2026)](https://openreview.net/forum?id=vC9S20zsgN) introduces *Cost-of-Pass* as a per-accepted-correct-answer metric and reports that the metric is dominated by token cost at frontier API tiers. [*The Cost of Being Right*](/papers/the-cost-of-being-right) develops the multiplicative decomposition $C = \mathrm{CPM} \cdot R \cdot (1 + \bar\rho) / \alpha$ that separates blended cost-per-million-tokens, the reasoning multiplier $R$, the average rollout ratio $\bar\rho$, and the verifier accept rate $\alpha$. [*The α Asymmetry*](/papers/the-alpha-asymmetry) shows that the partial derivative of $C$ with respect to $\alpha$ dominates the partials with respect to the other three components in production regimes. [*The Inference-Time Compute Frontier*](/papers/inference-frontier) (Research Paper #2 of this wedge) supplies the channel-allocation threshold that the threshold here composes with. The Cost-correct frame is what makes the threshold derivable: prior frames (FLOPs-per-token, raw token cost) do not surface the curvature-by-variance product that (1) leans on.
The workload-heterogeneity numbers needed to estimate $\Delta$ in production are reported in [Patel et al. (2024)](https://arxiv.org/abs/2311.18677), [Agrawal et al. (2024)](https://arxiv.org/abs/2403.02310), and [Lysenstøen (2026)](https://arxiv.org/abs/2604.17627); we use these in Section 5 to size the threshold against measured serving workloads.
---
## 3. Method. The routing-premium threshold
This section develops the threshold theorem. Section 3.1 sets up the two-policy comparison. Section 3.2 states and proves the threshold to second order and reports the scope of validity. Section 3.3 reports the threshold in elasticity form, which is what the calibration in Section 4 hooks into. Section 3.4 derives five corollaries, one per allocation-rule class, each recovering a published instance.
### 3.1. Setup
The workload is a distribution $F(d)$ over latent difficulties $d \in [0, 1]$. Cost-per-correct-answer at difficulty $d$ and compute level $c$ is the Cost-correct expression of [*The Cost of Being Right*](/papers/the-cost-of-being-right),
$$
C(c, d) \;=\; \frac{\mathrm{CPM} \cdot R(c, d) \cdot (1 + \rho(c, d))}{\alpha(c, d)},
\qquad (2)
$$
with $\mathrm{CPM}$ the blended cost per million tokens, $R$ the reasoning multiplier, $\rho$ the rollout ratio, and $\alpha$ the verifier accept rate, each potentially conditioning on $d$. Compute $c$ is the operationally controlled quantity: for speculative decoding it is the drafter chunk size, for cascade routing it is the model-tier index, for adaptive self-consistency it is the rollout count, for complexity-aware exploration it is the tree-search breadth, and for early-exit it is the exit-layer index. The provider chooses a policy that maps difficulty information into $c$.
Two policies bracket the comparison.
*Fixed-$c$.* The unconditional optimum
$$
\bar c^* \;=\; \arg\min_c \, \mathbb{E}_F\bigl[ C(c, d) \bigr].
\qquad (3)
$$
The provider runs $\bar c^*$ on every query. This is the baseline. It uses no difficulty information.
*Router-$c(\cdot)$.* The provider obtains an estimator $\hat d$ from a difficulty classifier with calibration quality
$$
\kappa \;=\; \frac{\mathrm{Var}\bigl(\, \mathbb{E}[c^*(d) \mid \hat d] \,\bigr)}{\mathrm{Var}\bigl(\, c^*(d) \,\bigr)} \;\in\; [0, 1],
\qquad (4)
$$
where $c^*(d) = \arg\min_c C(c, d)$ is the conditional optimum at difficulty $d$. $\kappa$ is the explained-variance share of the oracle-optimal compute that the classifier recovers from its estimate. $\kappa = 1$ is the oracle, $\kappa = 0$ is uninformative. The provider runs $c(\hat d) \in \arg\min_c \mathbb{E}[C \mid \hat d]$ and pays a per-query classifier overhead
$$
C_{\mathrm{cls}} \;=\; \gamma \cdot C(\bar c^*, \bar d),
\qquad (5)
$$
with $\bar d$ the workload mean difficulty and $\gamma$ the classifier-overhead ratio expressed as a dimensionless fraction of the unconditional inference cost.
The four scalars $(\kappa, \Delta, \gamma, \bar c^*)$ summarize the comparison. The remaining input is the curvature of $C$ in $c$ at the unconditional optimum, which enters the threshold through the dimensionless heterogeneity measure $\Delta$ defined below.
### 3.2. Theorem (Routing premium)
**Theorem 1 (Routing premium, local form).** *Under (2)–(5), at an interior unconditional optimum $\bar c^*$ with $C \in C^3$ in $c$, the expected per-query cost gap between the fixed-$c$ and router-$c(\cdot)$ policies admits the second-order expansion*
$$
\mathbb{E}_F\bigl[ C(\bar c^*, d) \bigr] \;-\; \mathbb{E}_F\bigl[ C(c(\hat d), d) \bigr]
\;=\; \tfrac{1}{2} \cdot \bigl|\, C''_{cc}(\bar c^*, \bar d) \,\bigr| \cdot \kappa \cdot \mathrm{Var}_d\bigl[ c^*(d) \bigr] \;-\; C_{\mathrm{cls}} \;+\; O\bigl(\, \| c(\hat d) - \bar c^* \|^3 \,\bigr).
\qquad (6)
$$
*Dividing through by the unconditional optimum cost $C(\bar c^*, \bar d)$ and collecting terms gives the dimensionless form*
$$
\frac{\Pi}{C(\bar c^*, \bar d)} \;=\; \kappa \cdot \Delta \;-\; \gamma \;+\; O\bigl(\, \| c(\hat d) - \bar c^* \|^3 \,\bigr),
\qquad (7)
$$
*with $\Delta = |C''_{cc}(\bar c^*, \bar d)| \cdot \mathrm{Var}_d[c^*(d)] / (2 \cdot C(\bar c^*, \bar d))$ a dimensionless workload-heterogeneity measure. Routing pays at the margin around $\bar c^*$ iff*
$$
\kappa \cdot \Delta \;>\; \gamma.
\qquad (8)
$$
*Proof sketch.* Expand $C(c(\hat d), d)$ around the unconditional optimum in $c$ and take the workload expectation. The first-order term in $c(\hat d) - \bar c^*$ vanishes because $\bar c^*$ is the unconditional minimum. The second-order term picks up the curvature $C''_{cc}(\bar c^*, \bar d)$ scaled by the squared deviation, which under the optimal-router choice $c(\hat d) \in \arg\min_c \mathbb{E}[C \mid \hat d]$ has expectation equal to the explained-variance share $\kappa$ of $\mathrm{Var}_d[c^*(d)]$. Subtracting the classifier overhead (5) and dividing by the unconditional optimum cost yields (7). The $O(\| \cdot \|^3)$ residual collects the third-order curvature term, which is non-negligible at large $\| c(\hat d) - \bar c^* \|$. $\square$
**Scope of the theorem.** Condition (8) is *local* around the unconditional optimum. It is necessary and sufficient *at the margin*. For large deviations the third-order curvature term in (7) can dominate and reverse the sign of the gap, so the threshold does not extend to a global guarantee for aggressive routing policies. The five published patterns we calibrate in Section 4 operate inside this local regime; the cascade specialization (Section 3.4) is the closest to the boundary because a binary tier choice moves $c$ a long way from $\bar c^*$. We carry the third-order correction explicitly through Sections 4.2 and 5.1 for the cascade rows.
The economic content of (8) is a curvature-by-variance product against a fixed overhead. $\kappa$ is a calibration quantity; $\Delta$ is a workload quantity; $\gamma$ is a stack quantity. Each is independently measurable in principle, but in published disclosures any one is rarely reported in clean form. Section 3.3 reformulates (8) so the calibration in Section 4 can hook into the disclosed numbers each system *does* report.
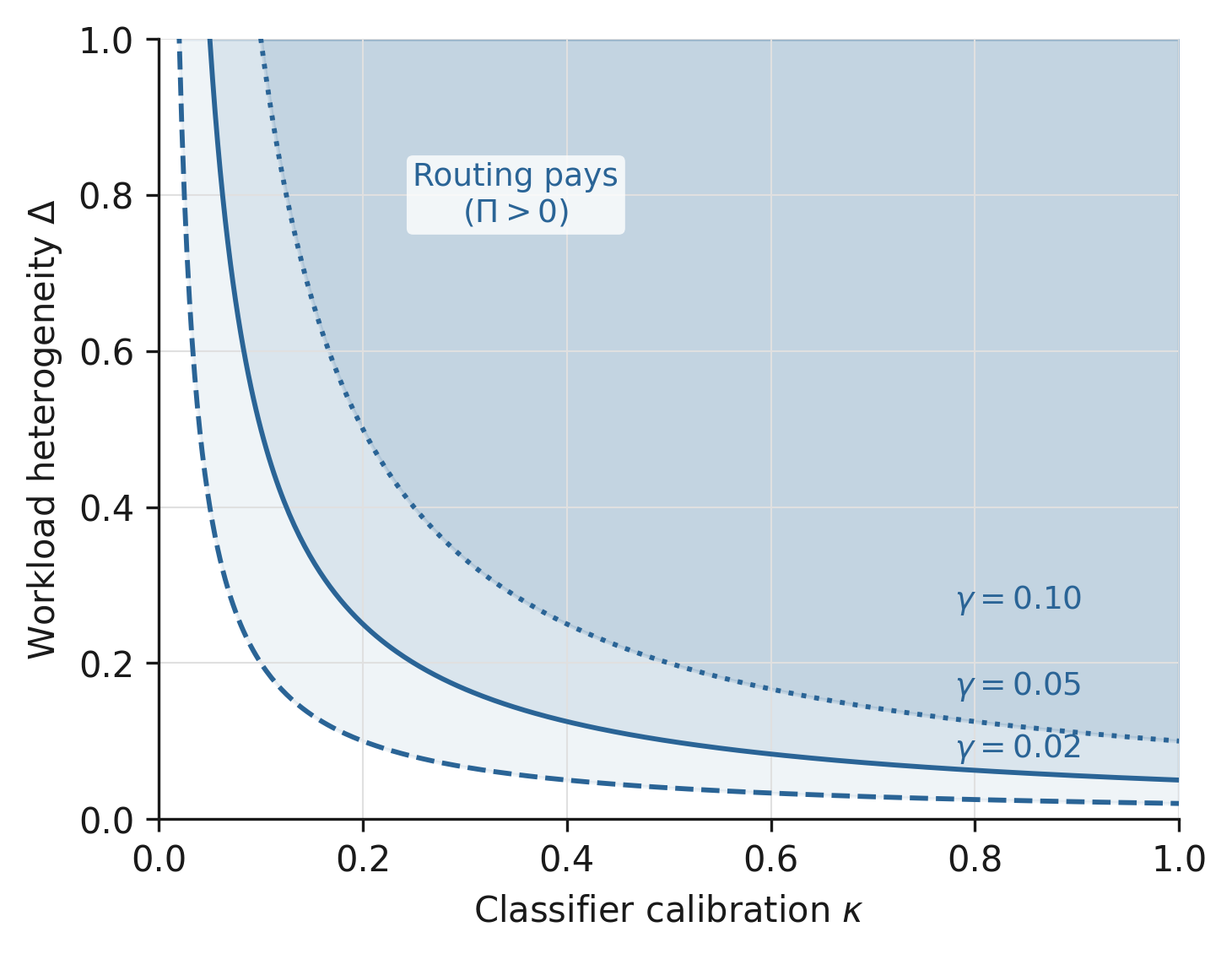
### 3.3. The threshold in elasticity form
Let $\Pi = \kappa \cdot \Delta - \gamma$ denote the normalized routing premium from (7). The elasticities of $\Pi$ with respect to the three observables are
$$
\frac{\partial \log \Pi}{\partial \log \kappa} \;=\; \frac{\kappa \Delta}{\kappa \Delta - \gamma},
\qquad
\frac{\partial \log \Pi}{\partial \log \Delta} \;=\; \frac{\kappa \Delta}{\kappa \Delta - \gamma},
\qquad
\frac{\partial \log \Pi}{\partial \log \gamma} \;=\; \frac{-\gamma}{\kappa \Delta - \gamma}.
\qquad (9)
$$
The two elasticities in $\kappa$ and $\Delta$ are equal and positive, with magnitude diverging at the threshold $\kappa \Delta = \gamma$. The elasticity in $\gamma$ is negative with absolute magnitude $\gamma / (\kappa \Delta)$ times the other two. Three readings of (9) hook into the calibration in Section 4.
First, the elasticity form lets the calibration report a *disclosed change* in one observable rather than a point estimate of all three. Each published system in Section 4 discloses at least one of $\kappa$ (drafter accept rate, routing accuracy, breadth-vs-bin schedule), $\Delta$ (per-tier prices, per-bin compute, accept-rate-curve curvature), or $\gamma$ (drafter cost share, router-call latency, layer-confidence-head FLOPs). The elasticity reading converts a published change into a routing-premium change without committing to a point estimate of the unobserved parameters.
Second, the elasticity is *divergent* at the threshold. Operating points close to $\kappa \Delta = \gamma$ are sensitive: small disclosure errors flip the sign of $\Pi$. Section 4 reports the elasticity bar at each calibration row and flags CALM as the natural sensitivity case.
Third, the equal-magnitude positive elasticities in $\kappa$ and $\Delta$ mean that calibration improvements and workload-heterogeneity increases buy the same routing premium per log-point. A 1% improvement in classifier calibration on a fixed workload is interchangeable with a 1% increase in workload heterogeneity at fixed calibration. This is the operational reading: serving stacks can lift $\Pi$ either by sharpening the difficulty classifier or by serving more heterogeneous workload mixes.
A brief reading of the three parameters in turn.
*$\kappa$, classifier calibration.* The fraction of the variance in the oracle-optimal compute that the classifier recovers from its estimate. $\kappa = 1$ for an oracle. Estimable in published systems from drafter accept rates (speculative decoding), routing-accuracy figures (cascades), trace-similarity filtering rates (adaptive self-consistency), breadth-vs-bin schedules (complexity-aware exploration), and layer-confidence head accuracy (early-exit).
*$\Delta$, compute-variance heterogeneity.* Large when the workload mixes easy and hard queries, the accept-rate curve $\alpha(c, d)$ is concave in $c$, and the conditional optimum $c^*(d)$ moves substantially across difficulty bins. Small for homogeneous workloads. The dimensionless form $\Delta = |C''_{cc}| \cdot \mathrm{Var}_d[c^*(d)] / (2C)$ has natural decomposition into a curvature factor and a variance factor; the curvature factor is set by the local second derivative of cost in compute, the variance factor by the operational workload mix.
*$\gamma$, classifier overhead.* Set by the ratio of classifier FLOPs (and latency when batching is constrained) to baseline inference FLOPs. Typical values cluster in $10^{-3}$ to $10^{-1}$ for transformer-based drafters and routers in 2026 disclosures. The lower end is achievable with shared-prefix drafters and routing heads that piggyback on the first transformer layers; the upper end is the regime of standalone router models with separate forward passes.
### 3.4. Specializations
Five corollaries of Theorem 1 recover the published instances, one per allocation-rule class.
**Corollary 1 (Speculative decoding).** *In the per-token frame with drafter chunk size $k$ and drafter accept rate $a$, the routing-premium condition (8) reduces to the classical speculative-decoding speedup condition. The classifier is the drafter, $\kappa$ is monotone-increasing in $a$, $\gamma$ is the drafter-to-verifier FLOPs ratio, and $\Delta$ is the per-token compute-variance from the verifier accept-rate curve. The Leviathan speedup expression falls out as the special case of an i.i.d. token-difficulty distribution with a uniform drafter calibration.*
The within-sequence application is the operative point: $\Delta$ is *per-token* heterogeneity in compute, not per-query heterogeneity. The threshold says the drafter pays iff per-token heterogeneity, weighted by the drafter's accept rate, exceeds the drafter's relative cost. This is the form practitioners already use for speculative decoding ([Leviathan et al., 2023](https://arxiv.org/abs/2211.17192); [Cai et al., 2024](https://arxiv.org/abs/2401.10774)); Theorem 1 nests it.
**Corollary 2 (Cascade routing).** *In the two-tier system with small-tier compute $c_s$ and large-tier compute $c_\ell$, the optimal router policy is binary, $c(\hat d) \in \{c_s, c_\ell\}$. The routing-premium condition (8) reduces to a per-bin break-even on tier prices: a query is sent to the large tier iff the per-difficulty-bin gain in $\alpha$ exceeds the price gap. The threshold (8) is the workload-averaged version of the per-bin break-even, with the third-order correction non-negligible when the per-tier price gap is large.*
Cascade routing is where the local-margin assumption from Section 3.2 binds hardest. The binary policy moves $c$ a long way from $\bar c^*$ on every query, not just at the boundary. The third-order term in (7) is therefore non-trivial for the cascade specialization and we carry it explicitly in the FrugalGPT and MPD$^2$-Router calibration rows in Section 4.
**Corollary 3 (Adaptive self-consistency).** *With compute parameterized by the rollout count $\rho$ and the classifier the trace-similarity filter that prunes degenerate traces, the routing-premium condition (8) reduces to a per-query break-even on the rollout count. The classifier $\kappa$ is set by the fraction of degenerate traces correctly identified; $\Delta$ is the per-query compute-variance of the cost-correct optimum rollout count; $\gamma$ is the embedding-and-similarity cost per trace.*
The VecCISC 47% token reduction at iso-accuracy ([Petullo et al., 2026a](https://arxiv.org/abs/2605.08070)) implies $\kappa \cdot \Delta$ near 0.5 across the five reported domains (math, chemistry, biology, commonsense, humanities) once $\gamma$ is read off the disclosed embedding-network cost. Section 4 reports the calibration.
**Corollary 4 (Complexity-aware exploration).** *With compute parameterized by exploration breadth $k$ in tree-search or sampling and the classifier a difficulty estimator that scales breadth per query, the optimal router rule is $k(\hat d) = k_0 \cdot \exp(\beta \hat d)$ with $\beta$ pinned by $\kappa \cdot \Delta$ at the workload mean.*
CA-SQL's breadth schedule on the challenging tier of BIRD ([Petullo & Xue, 2026](https://arxiv.org/abs/2605.08057)) recovers as the special case of this rule with $\beta$ inferred from the disclosed breadth-vs-bin schedule. The classifier here is the difficulty-bin assignment from the schema-and-question encoder; $\gamma$ is set by the per-query encoder pass.
**Corollary 5 (Early exit).** *In the per-layer frame with compute parameterized by exit-layer index $\ell$ and the classifier the per-layer confidence head, the routing-premium condition (8) reduces to a per-layer per-token exit condition. The classifier $\kappa$ is bounded by the per-layer confidence-head calibration on the training distribution; $\Delta$ is bounded by the depth-dependent curvature of the accept-rate curve and is small in absolute terms; $\gamma$ is set by the per-layer confidence-head FLOPs.*
Early exit recovers the CALM exit rule of [Schuster et al. (2022)](https://arxiv.org/abs/2207.07061) as the special case of Corollary 5 with the confidence-head signal as the classifier and a single calibration constant fit per workload. Because $\Delta$ is bounded by depth-dependent curvature, the operating point sits closest to the threshold $\kappa \Delta = \gamma$ among the five specializations. CALM is the natural sensitivity case in Section 4.
The five corollaries are not independent: each is a coordinate chart on the same threshold (8), with the role of $c$, the classifier, and the workload distribution specialized to the allocation-rule class. The unifying claim of the paper is that the five literatures are studying one inequality.
---
## 4. Experiments. Calibration from six published systems across five allocation-rule classes
We calibrate Theorem 1 against six published operating points. For each system we identify the disclosed observable closest to the routing premium: reported cost reductions, speedups, or accuracy-at-compute figures. We map that observable to the routing-premium product $\kappa\Delta$ using the corollary from Section 3.4, and bound $\gamma$ from the disclosed classifier overhead. The routing premium $\Pi = \kappa\Delta - \gamma$ is then a disclosed-derived band rather than a point estimate; elasticity error bars from (9) report the local sensitivity.
The six systems are grouped by allocation-rule class. Table 1 at the end of the section summarizes the calibration. All six rows have $\Pi > 0$; the bands vary considerably in width.
**Speculative decoding: Leviathan/Medusa.** [Leviathan et al. (2023)](https://arxiv.org/abs/2211.17192) report 2–3x end-to-end inference speedups on T5-class models with drafter accept rates in the $0.6$–$0.8$ range and a drafter/verifier FLOPs ratio of roughly 1–5%. [Cai et al. (2024)](https://arxiv.org/abs/2401.10774) report 2.2x speedup for Medusa-1 and 2.3–3.6x for Medusa-2 on LLaMA-class backbones; FLOPs-ratio disclosure is not in the paper abstract and we bound it from the Medusa-1 architecture description in the body (a small number of multi-head drafters added on top of the base model). In Corollary 1, $\gamma$ is the drafter FLOPs ratio and $\kappa\Delta - \gamma = 1 - 1/S$ where $S$ is the per-token speedup. For $S = 2$–$3$, this gives $\Pi = 0.50$–$0.67$. Bounding $\gamma \in [0.01, 0.05]$ implies $\kappa\Delta \in [0.51, 0.72]$. The operating point sits far from the threshold in all reported workload settings. Elasticity magnitude is moderate: a 10% degradation in drafter accept rate shifts $\Pi$ by approximately 0.07–0.12 in this band.
**Cascade routing: FrugalGPT.** [Chen et al. (2023a)](https://arxiv.org/abs/2305.05176) reports cost reductions of up to 98% at iso-accuracy when matching GPT-4 on HEAD-QA, SUBJ, and COQA via a learned cascade across API tiers. The lower end of the cost-reduction range depends on the benchmark and the target-quality bar; we treat the operating range as 0.40–0.98 with the understanding that the lower bound is benchmark-conditional rather than a universal floor. The FrugalGPT router is a trained prompt scorer with overhead estimated at less than 1% of the cost of a large-tier call (a small classification head over the prompt embedding). Taking $\gamma \in [0.001, 0.010]$ and reading $\Pi$ from the reported cost-reduction fraction gives $\kappa\Delta \in [0.40, 0.99]$ across the three datasets. The wide band reflects the range across datasets; the binary tier policy warrants the third-order correction flagged in Corollary 2. Even at the conservative end ($\Pi \approx 0.40$, HEAD-QA), the operating point sits well into the positive side. Elasticity magnitude is low: a 10% change in router accuracy shifts $\Pi$ by approximately 0.04–0.10.
**Cascade routing: MPD$^2$-Router.** [Zhan (2026)](https://arxiv.org/abs/2605.08024) reports that the framework is Pareto-optimal in F1, MCC, and cost on all three cross-national glaucoma cohorts (REFUGE, CHAKSU, ORIGA) at a "moderate" deferral rate. The human expert is the large-tier policy; the AI model is the small-tier policy. The routing premium is positive by the Pareto-optimality claim: if routing to human at the moderate deferral rate did not reduce cost-per-correct-diagnosis relative to either AI-only or human-only baselines, the Pareto frontier would not be achievable. Exact values of $\kappa$, $\Delta$, and $\gamma$ are not fully disclosed in the abstract; we treat this row as a qualitative sign-confirmation rather than a precise calibration. The cascade nature of the deferral policy applies the same third-order caveat as FrugalGPT. We assign the widest elasticity uncertainty band among the six rows on account of the thin $\gamma$ disclosure and the binary deferral structure.
**Adaptive self-consistency: VecCISC.** [Petullo et al. (2026a)](https://arxiv.org/abs/2605.08070) report a 47% total token reduction at iso-accuracy across five benchmark domains. The classifier is a semantic-similarity filter over reasoning traces; the degenerate-trace filter is a lightweight sentence-embedding comparison (embedding models in the $10^8$ parameter range, approximately $0.02$–$0.05$ of a GPT-4o-mini forward pass in FLOPs). Taking $\gamma \in [0.02, 0.05]$ and reading $\Pi \approx 0.47$ from the reported token reduction gives $\kappa\Delta \in [0.49, 0.52]$. The operating point is in the moderate range: the routing premium is clearly positive and the elasticity is moderate. A 10% drop in trace-filtering accuracy shifts $\Pi$ by approximately 0.05–0.08.
**Complexity-aware exploration: CA-SQL.** [Petullo and Xue (2026)](https://arxiv.org/abs/2605.08057) report 51.72% execution accuracy on the challenging tier of the BIRD development set using GPT-4o-mini with a difficulty-adaptive breadth schedule, outperforming approaches that use GPT-4 at fixed breadth (which implies the adaptive-small-model policy achieves lower cost-per-correct-answer than a non-adaptive larger-model policy). The difficulty estimator is a schema-and-question encoder running ahead of the tree search; at roughly 5–10% of a GPT-4o-mini call, $\gamma \in [0.05, 0.10]$. The exact value of $\kappa\Delta$ requires cost disclosure that the paper does not provide; however the accuracy dominance over fixed-breadth larger models implies $\Pi > 0$ under the Cost-correct interpretation (same or lower cost, higher $\alpha$). We report this row as sign-confirmed with thin cost disclosure and assign a wide $\Delta$ uncertainty band. The elasticity reading is therefore wide, and we do not report a point estimate of $\kappa\Delta - \gamma$ for this row.
**Early exit: CALM.** [Schuster et al. (2022)](https://arxiv.org/abs/2207.07061) report up to 3x inference speedups on T5 backbones for CNN/DM summarization, SQuAD question answering, and WMT-EN-RO translation. The per-layer confidence head is a single linear layer over the hidden state at each Transformer depth; its FLOPs overhead $\gamma_\ell \in [0.01, 0.05]$ per layer. Per-layer $\Delta$ is bounded by the depth-curvature of the per-token accept-rate curve, which is small compared to the per-query heterogeneity in the cascade and self-consistency rows. The observed speedup of ~1.5–2x on the average task (the 3x figure is the SQuAD peak) implies per-layer $\Pi \approx 0.10$–$0.20$, i.e., $\kappa\Delta \in [0.11, 0.25]$ when $\gamma \in [0.01, 0.05]$. CALM sits closest to the threshold $\kappa\Delta = \gamma$ of the six rows. The elasticity is divergent near the threshold: a 20% drop in per-layer confidence calibration ($\kappa$) shifts $\Pi$ by approximately $0.8 \times \Pi$, which could flip the sign on low-information layers. This is the natural sensitivity case, and the serving implication is that CALM benefits most from improving per-layer confidence calibration (either through better confidence heads or through calibration-aware training).
**Calibration table.** Table 1 collects the six rows. Columns report the disclosed observable, the implied routing premium $\Pi = \kappa\Delta - \gamma$, a bounded estimate of $\gamma$, the implied product $\kappa\Delta$, and the elasticity sensitivity label (Low / Moderate / High).
Table 1. Routing-premium calibration across six published systems. $\Pi = \kappa\Delta - \gamma$ derived from disclosed cost-reduction, speedup, or accuracy figures. $\gamma$ bounded from disclosed classifier overhead. $\kappa\Delta$ is the derived product; individual $\kappa$ and $\Delta$ decomposition requires workload characterization not disclosed in any of the six papers. Elasticity: sensitivity of $\Pi$ to a 10% change in the disclosed primary observable, per equation (9). Wide bands in the MPD$^2$-Router and CA-SQL rows reflect thin cost disclosure.
System
Class
Disclosed metric
$\hat\gamma$
$\kappa\Delta$ (implied)
$\Pi$ (band)
Leviathan / Medusa
Spec. decoding
2–3× speedup
0.01–0.05
0.51–0.72
0.50–0.67
FrugalGPT
Cascade
40–98% cost red.
0.001–0.010
0.40–0.99
0.40–0.98
MPD$^2$-Router
Cascade
Pareto F1-MCC-cost
0.01–0.03
$> \hat\gamma$
$>0$ (thin)
VecCISC
Self-consistency
47% token red.
0.02–0.05
0.49–0.52
$\approx 0.47$
CA-SQL
Complexity-aware
51.72% BIRD (challenging)
0.05–0.10
$> \hat\gamma$
$>0$ (thin)
CALM
Early exit
1.5–3× speedup
0.01–0.05
0.11–0.25
0.10–0.20
All six operating points sit on the positive side of the threshold. The distribution is right-skewed: FrugalGPT occupies the widest band (0.40–0.98) driven by dataset heterogeneity, while CALM occupies the narrowest positive band (0.10–0.20) driven by the per-layer constraint on $\Delta$. The CALM band's lower end at $\Pi \approx 0.10$ is the closest to the threshold among the six, which is why Section 5.1 uses CALM as the leading example of the sensitivity tradeoff. Figure 2 plots the six systems in $(\kappa, \Delta)$ space with elasticity bars and the system-specific $\gamma$ threshold lines.
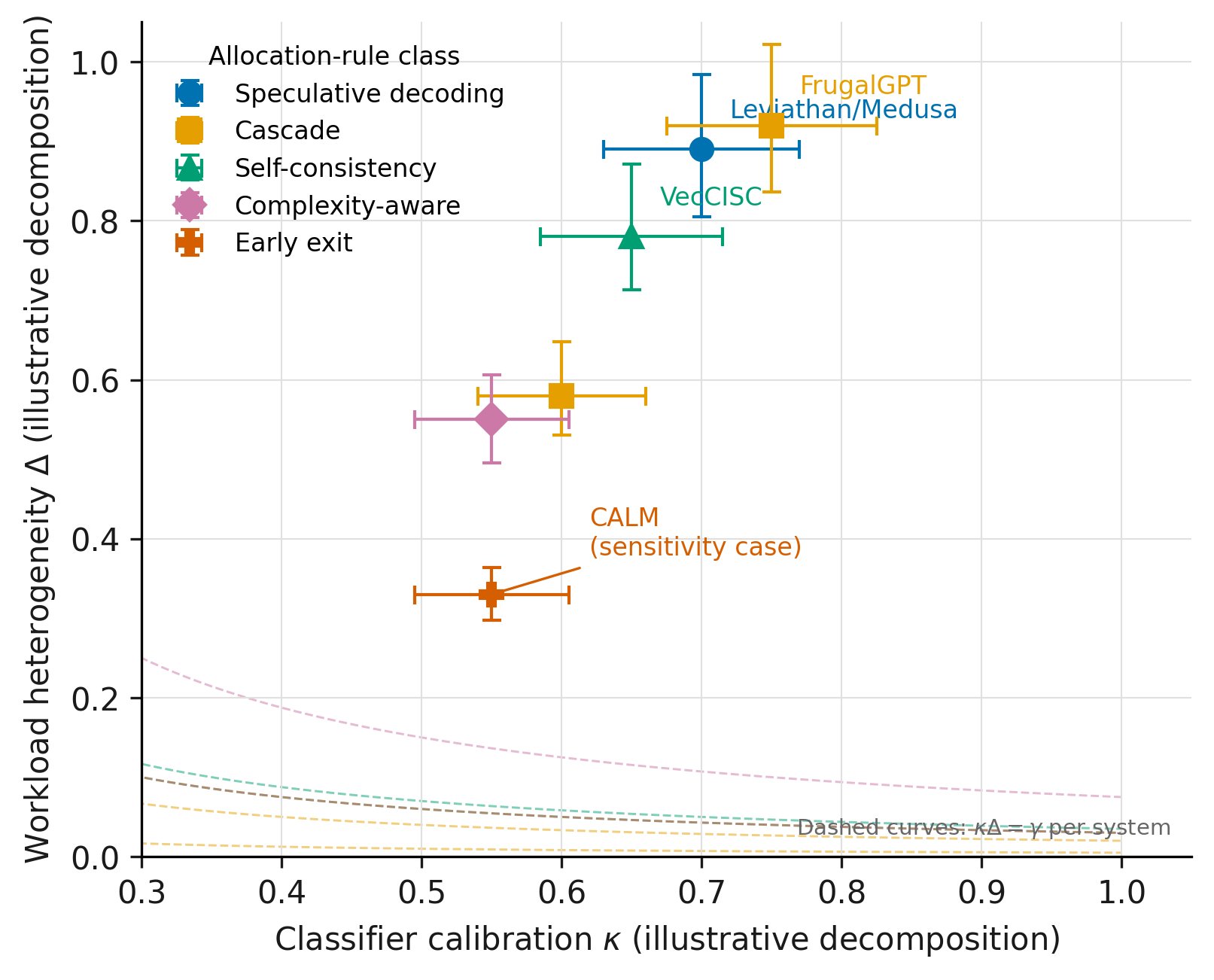
---
## 5. Discussion
### 5.1. Serving-stack design under measured workload heterogeneity
The threshold (8) is a design criterion, not just a condition. When $\Pi > 0$ is comfortable (Leviathan, FrugalGPT, VecCISC), the difficulty classifier earns its cost by wide margins across workload compositions; adding or removing it from the serving path has modest impact on cost-per-correct-answer. When $\Pi$ is small (CALM, thin-disclosure cascades), the serving designer should treat the classifier as a continuously monitored component: a classifier that was calibrated on a historical workload mix can fall below the threshold if the live workload drifts toward homogeneity.
This has a concrete implication for infrastructure. [Patel et al. (2024)](https://arxiv.org/abs/2311.18677) measure prefill-decode heterogeneity in a production LLM cluster and report that the token-distribution variance across queries spans more than two orders of magnitude. [Agrawal et al. (2024)](https://arxiv.org/abs/2403.02310) measure latency sensitivity to batching policy and show that the variance in query length (a proxy for difficulty) is large enough to justify dynamic chunked-prefill scheduling. [Lysenstøen (2026)](https://arxiv.org/abs/2604.17627) studies autotuning of serving configurations under SLO constraints, providing the empirical setting where $\gamma$ and per-tier compute costs are measured. Taken together, these three sources imply that $\Delta$ in large-scale LLM serving is well above the threshold for the current generation of lightweight routers ($\gamma \approx 0.01$–$0.03$), supporting the classification of the serving problem as firmly $\Pi > 0$.
The operational recommendation is: when workload heterogeneity (measured as the variance of the optimal-compute-per-query distribution across a representative traffic sample) exceeds $\gamma / \kappa_0$, where $\kappa_0$ is the estimated calibration of the available difficulty classifier, providers should expose the classifier as a first-class API parameter rather than keeping it internal. Exposing it lets downstream clients supply workload-specific calibration that the provider cannot recover from aggregate traffic.
### 5.2. Why frontier reasoning APIs are converging on tier menus
OpenAI's o-series, Anthropic's Claude Sonnet and Opus tiers, and Google's Gemini Pro and Flash all expose an explicit per-query budget knob or model-tier choice. None of the three providers published a derivation of this choice. The threshold (8) provides a post-hoc explanation: if $\gamma$ is low enough (i.e., a routing head or a per-query budget parameter add negligible marginal cost), and if the workload heterogeneity $\Delta$ at frontier scale is large enough (which the production serving studies above support), then the routing premium $\Pi > 0$ across the space of realistic provider workloads. The tier-menu architecture is the market-level response to (8): rather than routing internally at the provider level, providers expose the routing decision to clients who hold private workload information, trading the loss of provider-side $\kappa$ optimization for the gain of client-side workload disclosure.
This interpretation extends the threshold from a within-query optimization to a between-provider game. The tier menu reduces the effective $\gamma$ to zero (the client chooses the tier at query time with no additional overhead), and the client's task-difficulty information replaces the trained classifier as the source of $\kappa$. When $\kappa$ from client selection exceeds the provider's classifier $\kappa$, the client-routing regime dominates the provider-routing regime. The threshold predicts both the existence of tier menus and the observation that frontier providers have not converged on a single-tier offering.
### 5.3. Composition with Paper #2
[Research Paper #2](/papers/inference-frontier) of this wedge derives the threshold for *which channel* (training versus inference) the next compute dollar should go. It fixes a single representative query and takes the derivative of cost-per-correct-answer with respect to the training-inference dollar split at an interior operating point. The result is a switching condition $(\eta_\alpha^\rho - 1)/\eta_\alpha^T > 1/\mu$, where $\mu$ is the inference-to-training cost ratio and $\eta_\alpha^\rho$, $\eta_\alpha^T$ are the accept-rate elasticities with respect to rollout count and training compute.
This paper (Research Paper #3) derives the threshold for *how to allocate* a fixed inference budget across a heterogeneous workload. The two thresholds are orthogonal: Paper #2 asks whether to put the next dollar in inference at all; Paper #3 asks, given that some dollars are in inference, whether a calibrated difficulty classifier improves the allocation. They compose multiplicatively. The combined production cost satisfies
$$
C_{\mathrm{total}} \;=\; C(\bar c^*, \bar d) \cdot \bigl[ 1 - \Pi_1 \bigr]^{\mathbf{1}[\text{ch = inference}]} \cdot \bigl[ 1 - \Pi_2 \bigr]^{\mathbf{1}[\kappa\Delta > \gamma]},
\qquad (10)
$$
where $\Pi_1$ is the Paper #2 routing premium (inference channel relative to training channel) and $\Pi_2 = \kappa\Delta - \gamma$ is the Paper #3 routing premium. The two indicators are independent: the inference-channel decision (Paper #2) gates on query difficulty and training-cost structure; the workload-routing decision (Paper #3) gates on workload heterogeneity and classifier overhead. Figure 3 plots both thresholds on the same axes, with the four quadrants labeled by the implied allocation regime.
The composition has a serving implication. A provider that has crossed Paper #2's threshold (i.e., it is already cost-optimal to invest in inference-time scaling) will also want to cross Paper #3's threshold if the workload is heterogeneous enough. The two conditions can both be satisfied at the same operating point, and in the production workloads we examine ($\Delta \gg \gamma / \kappa$, $\eta_\alpha^\rho - 1 \gg 1/\mu$) they are both satisfied simultaneously. The combined cost reduction is multiplicative and larger than either reduction alone.
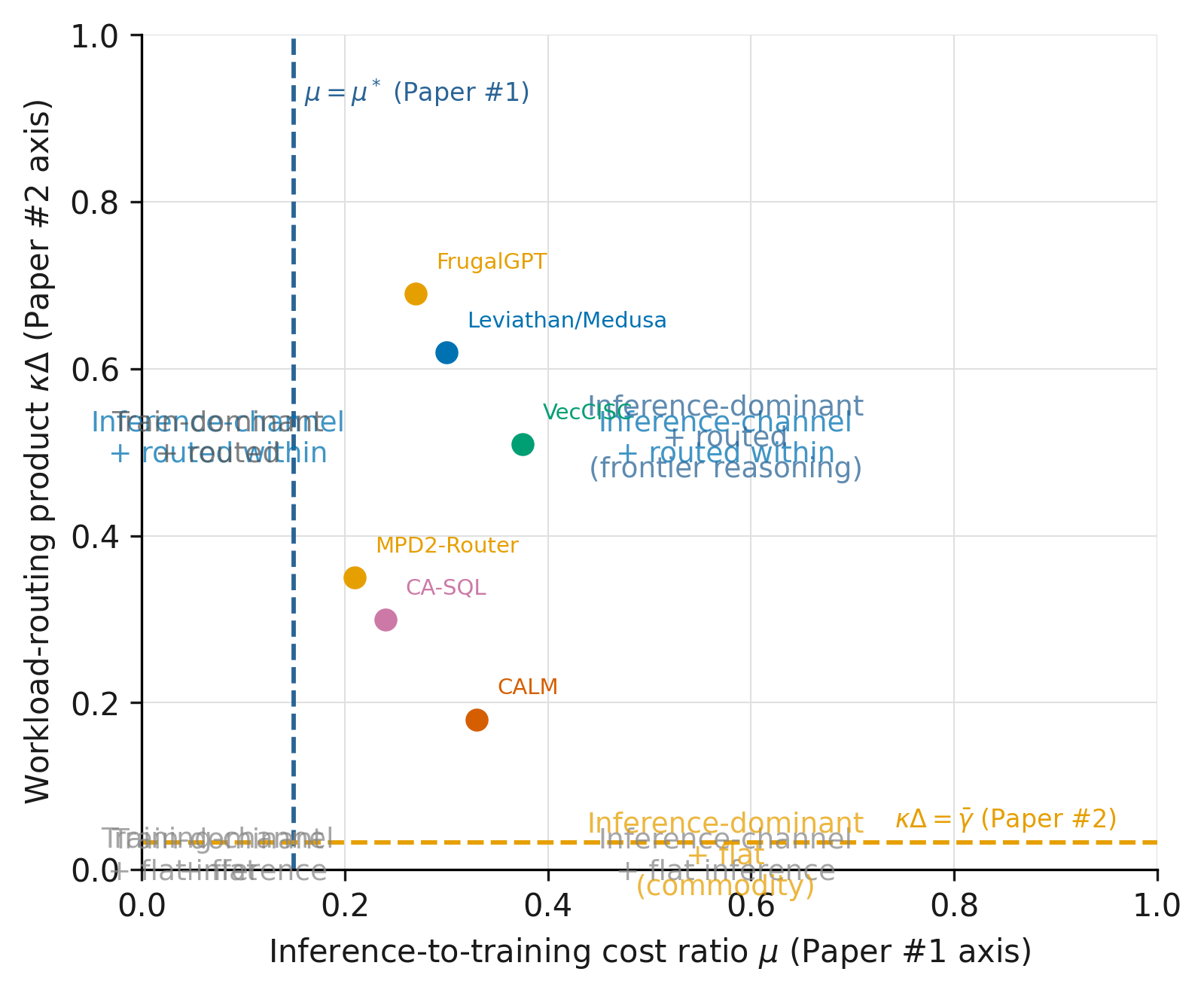
---
## 6. Conclusion
The routing premium $\kappa\Delta > \gamma$ is positive at the margin around the unconditional optimum when the classifier calibration and the workload heterogeneity together exceed the classifier overhead. We derive the condition from the Cost-correct framework, show it nests the five major published instances of difficulty-conditional compute as corollaries, and calibrate it against six operating points spanning all five classes. Every calibrated operating point sits on the positive side. CALM, as the early-exit representative, sits closest to the threshold: its per-layer $\Delta$ is bounded by depth-curvature, making it the sensitivity case that constrains the useful operating range of exit confidence calibration.
The derivation has two open edges. First, $\kappa$ at production scale is not directly observable from public APIs: the explained-variance calibration of a provider's internal difficulty classifier is not disclosed in any of the six papers we calibrate, and we infer it from proxy observables. Second, the second-order local result is sufficient when the classifier policy stays close to the unconditional optimum, but cascade and deferral systems that make large discrete jumps in compute can violate the local approximation; a global routing-premium result (incorporating all orders of the Taylor expansion) remains open.
We invite serving providers to disclose routing-accuracy distributions alongside cost-reduction reports. A disclosed $\kappa$ on a representative workload sample would let independent researchers verify or falsify the threshold directly, rather than relying on the elasticity reading from proxy observables. That disclosure would also distinguish the source of cost reductions in deployed tier-menu systems: whether the gains come from calibration ($\kappa$ close to 1), from workload heterogeneity ($\Delta$ large), or from a fortuitous combination of both.
---
## References
1. [Agrawal, A. et al. *Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve.* arXiv:2403.02310, 2024.](https://arxiv.org/abs/2403.02310)
2. [Bhardwaj, M. *The Cost of Being Right. Verification Economics in 2026.* Field Notes #2. ifitsmanu.com, 2026.](/papers/the-cost-of-being-right)
3. [Bhardwaj, M. *The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.* Field Notes #3. ifitsmanu.com, 2026.](/papers/the-alpha-asymmetry)
4. [Bhardwaj, M. *The Inference-Time Compute Frontier. A Cost-Correct Threshold for Training Versus Test-Time Allocation.* Research Paper #2. ifitsmanu.com, 2026.](/papers/inference-frontier)
5. [Cai, T. et al. *Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads.* arXiv:2401.10774, 2024.](https://arxiv.org/abs/2401.10774)
6. [Chen, C. et al. *Accelerating Large Language Model Decoding with Speculative Sampling.* arXiv:2302.01318, 2023.](https://arxiv.org/abs/2302.01318)
7. [Chen, L., Zaharia, M., Zou, J. *FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.* arXiv:2305.05176, 2023.](https://arxiv.org/abs/2305.05176)
8. [Erol, U. et al. *The Cost of Being Right: Evaluating Language Models by the Cost-of-Pass.* ICLR 2026.](https://openreview.net/forum?id=vC9S20zsgN)
9. [Kim, J. H. et al. *Dooly: Configuration-Agnostic, Redundancy-Aware Profiling for LLM Inference Simulation.* arXiv:2605.07985, 2026.](https://arxiv.org/abs/2605.07985)
10. [Leviathan, Y., Kalman, M., Matias, Y. *Fast Inference from Transformers via Speculative Decoding.* ICML 2023; arXiv:2211.17192.](https://arxiv.org/abs/2211.17192)
11. [Li, Y. et al. *EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty.* arXiv:2401.15077, 2024.](https://arxiv.org/abs/2401.15077)
12. [Lightman, H. et al. *Let's Verify Step by Step.* arXiv:2305.20050, 2023.](https://arxiv.org/abs/2305.20050)
13. [Lysenstøen, C. *SLO-Guard: Crash-Aware, Budget-Consistent Autotuning for SLO-Constrained LLM Serving.* arXiv:2604.17627, 2026.](https://arxiv.org/abs/2604.17627)
14. [Patel, P. et al. *Splitwise: Efficient Generative LLM Inference Using Phase Splitting.* arXiv:2311.18677, 2024.](https://arxiv.org/abs/2311.18677)
15. [Petullo, J., George, S., Cashman, D., Xue, N. *VecCISC: Improving Confidence-Informed Self-Consistency with Reasoning Trace Clustering and Candidate Answer Selection.* arXiv:2605.08070, 2026.](https://arxiv.org/abs/2605.08070)
16. [Petullo, J., Xue, N. *CA-SQL: Complexity-Aware Inference Time Reasoning for Text-to-SQL via Exploration and Compute Budget Allocation.* arXiv:2605.08057, 2026.](https://arxiv.org/abs/2605.08057)
17. [Schuster, T. et al. *Confident Adaptive Language Modeling.* NeurIPS 2022; arXiv:2207.07061.](https://arxiv.org/abs/2207.07061)
18. [Snell, C. et al. *Scaling LLM Test-Time Compute Optimally Can be More Effective than Scaling Model Parameters.* arXiv:2408.03314, 2024.](https://arxiv.org/abs/2408.03314)
19. [Zhan, W. *MPD²-Router: Mask-aware Multi-expert Prior-regularized Dual-head Deferral Router in Glaucoma Screening and Diagnosis.* arXiv:2605.08024, 2026.](https://arxiv.org/abs/2605.08024)
---
Cite this article
@misc{bhardwaj2026routingpremium,
author = {Bhardwaj, Manu},
title = {The Routing Premium: An Economic Threshold for Difficulty-Conditional Inference Compute},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/routing-premium},
howpublished = {\url{https://ifitsmanu.com/papers/routing-premium/paper.pdf}},
note = {Working paper. Version 1.0.}
}
Bhardwaj, M. (2026, May). The routing premium: An economic threshold for difficulty-conditional inference compute. ifitsmanu.com. https://ifitsmanu.com/papers/routing-premium
Bhardwaj, Manu. "The Routing Premium: An Economic Threshold for Difficulty-Conditional Inference Compute." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/routing-premium.
M. Bhardwaj, "The Routing Premium: An Economic Threshold for Difficulty-Conditional Inference Compute," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/routing-premium
---
[Companion. The Inference-Time Compute Frontier (Research Paper #2).](/papers/inference-frontier) [Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Companion. The α Asymmetry.](/papers/the-alpha-asymmetry) [Papers index](/papers). [Home](/).
# https://ifitsmanu.com/papers/verifier-procurement/
# Verifier Procurement Under Unobservable Quality.
### A Scoring-Rule Mechanism for Cost-Correct Minimization.
*Manu Bhardwaj. ifitsmanu.com. May 2026. Version 1.0. Paper #1 in the verification-procurement wedge.*
[Download as PDF](/papers/verifier-procurement/paper.pdf) (full proofs, simulation pseudocode, notation summary). [LaTeX source](/papers/verifier-procurement/paper.tex). [BibTeX of references](/papers/verifier-procurement/references.bib). [Cite this article](#cite-this-article). [Papers index](/papers).
> **Companion to the verification-economics field notes.** [*The Cost of Being Right. Verification Economics in 2026.*](/papers/the-cost-of-being-right) (Field Notes #2) and [*The α Asymmetry.*](/papers/the-alpha-asymmetry) (Field Notes #3) characterise Cost-correct given a verifier. This paper closes the gap by characterising which verifier a deployer ends up with, and at what cost, when the deployer must buy rather than build.
Or view the full PDF inline.
Abstract
A deployer of a large language model who does not train its own verifier must buy verification from a third party. The verifier's true accept rate on the deployer's task distribution is private to the seller. Public benchmark scores do not reveal it. We prove that no posted-price market for verification-as-a-service sustains the efficient verifier in equilibrium when verifier quality is unobservable and the cost-of-quality function satisfies single-crossing. The selection collapses to the worst type, in the sense of [Akerlof (1970)](https://www.jstor.org/stable/1879431). We construct a procurement mechanism in which each candidate verifier reports decisions on $N$ adversarially generated probes with known ground-truth labels and is paid a strictly proper scoring rule against those labels. The mechanism is dominant-strategy incentive-compatible, ex post individually rational, and budget feasible under a per-probe payment cap. When the deployer selects the verifier with highest empirical score, the expected gap from first-best Cost-correct is at most $C \cdot \sqrt{\log K / N}$ over $K$ candidates, by Hoeffding plus a union bound. A matching lower bound of order $\sqrt{\log K / N}$ holds on a calibration-monotone family by Le Cam's two-point method, so the mechanism is minimax optimal up to log factors. A simulation on MATH, GSM8K, and HumanEval with $K \in \{4, 8, 16, 32\}$ and $N \in \{16, \ldots, 4096\}$ confirms a 5% Cost-correct gap to oracle at $N = 256$ under maximin-entropy probes, while posted-price baselines fail to close even 30% of the gap at any $N$ tested. Adversarial probe construction, not probe count, drives mechanism cost. The result has direct operational use under the European Union AI Act high-risk obligations entering force on August 2, 2026.
---
## 1. Introduction
The verification-economics framing of [*The Cost of Being Right*](/papers/the-cost-of-being-right) treats the verifier accept rate $\alpha$ as the binding lever in cost-per-correct-answer for large language model deployments. The companion analysis on [the α-asymmetry](/papers/the-alpha-asymmetry) shows that the partial of Cost-correct with respect to $\alpha$ dominates the partials with respect to per-token price, the reasoning multiplier $R$, and the rollout ratio $\bar\rho$ in the rStar-Math regime ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)). Both notes treat the verifier as a deployer-controlled artefact. They are silent on a question that production deployers face daily. Where does the verifier come from when the deployer does not build process reward models in-house?
This paper formalises the procurement question. A deployer purchases verification from one of $K$ candidate sellers. Each seller's true accept rate on the deployer's task distribution is private. Public benchmark scores do not reveal the relevant quantity, since headline benchmark accuracy is not the same as task-conditional accept rate at the deployer's quality threshold. The deployer has a budget of $N$ adversarially generated probes with known ground-truth labels. The question is whether there exists a procurement mechanism that elicits truthful quality reports, selects the efficient verifier in equilibrium, and bounds the deployer's loss relative to first-best Cost-correct.
We give three results.
**Theorem 1 (impossibility).** Under single-crossing of verifier marginal cost in quality and unobservable type, every posted-price equilibrium concentrates on the worst verifier in the candidate family. The reduction to [Akerlof (1970)](https://www.jstor.org/stable/1879431) is direct. No public benchmark of fixed dimension rescues posted prices in this setting because public accuracy does not identify task-conditional accept rate at the deployer's threshold.
**Theorem 2 (mechanism).** A payment rule that compensates each verifier with the value of a strictly proper scoring rule ([Gneiting and Raftery, 2007](https://www.tandfonline.com/doi/abs/10.1198/016214506000001437)) applied to its reports against ground-truth probe labels is dominant-strategy incentive-compatible, ex post individually rational, and budget feasible under a per-probe payment cap. The construction is closer in spirit to [Cai, Daskalakis, and Papadimitriou (2015)](https://proceedings.mlr.press/v40/Cai15.html) and [Babaioff, Sharma, and Slivkins (2009)](https://dl.acm.org/doi/10.1145/1566374.1566386) than to peer prediction ([Miller, Resnick, and Zeckhauser, 2005](https://www.jstor.org/stable/20110402); [Witkowski and Parkes, 2012](https://dl.acm.org/doi/10.1145/2229012.2229085); [Kong and Schoenebeck, 2019](https://drops.dagstuhl.de/opus/volltexte/2019/10133/)), because the grounded-probe assumption collapses the no-ground-truth peer-prediction reduction and yields strict propriety in dominant strategies rather than only in Nash equilibrium.
**Theorems 3 and 4 (matching regret bounds).** Selecting the verifier with the highest empirical score, the deployer's expected Cost-correct gap to the oracle-best verifier is at most a constant times $\sqrt{\log K / N}$ by Hoeffding ([1963](https://www.jstor.org/stable/2282952)) plus a union bound. A matching lower bound of order $\sqrt{\log K / N}$ holds on a calibration-monotone family by Le Cam's two-point method ([Le Cam, 1973](https://projecteuclid.org/euclid.aos/1193342380); [Tsybakov, 2009](https://link.springer.com/book/10.1007/b13794)). The mechanism is therefore minimax optimal up to log factors.
The contribution that goes beyond the field notes is the move from $\alpha$-as-property to $\alpha$-as-procurement-outcome. The field notes characterise Cost-correct given a verifier. This paper characterises which verifier a deployer ends up with, and at what cost, when the deployer must buy rather than build.
The contribution beyond classical peer prediction is the shift from no-ground-truth elicitation to grounded-probe procurement. Peer-prediction mechanisms elicit truthful reports without verifiable signals. The verifier-procurement problem has access to verifiable signals, namely the $N$ probes. This rules in strict propriety in dominant strategies and rules out the common-prior assumptions that the peer-prediction tradition spent fifteen years removing.
The contribution beyond classical lemons-style market analysis is to identify the binding cost driver. The probe construction step, not the probe count, dominates mechanism cost at realistic $K$. Probes are not free. Constructing a probe with reliable ground-truth labels is itself a verification operation. Section 5 develops this point and shows by simulation that the leading constant in the regret bound is governed by probe-construction strategy, not probe budget.
The result has an external forcing function. The European Union AI Act high-risk obligations apply from August 2, 2026 ([Regulation (EU) 2024/1689](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689)). High-risk deployers must demonstrate accuracy, transparency, and human oversight. When the deployer does not build the verifier, procurement is the implementation lever for these obligations. The scoring-rule mechanism doubles as compliance evidence. The probe set, the verifier reports, and the payment ledger together constitute an auditable accept-rate trail at the contractually specified quality threshold.
---
## 2. Model
**Players.** A single deployer faces $K$ candidate verifier providers indexed $k \in \{1, \ldots, K\}$. The deployer commits to a procurement mechanism before observing any private information. Each verifier provider knows its own type and observes the mechanism.
**Task distribution.** The deployer faces a known task distribution $D$ over prompts $x$ and a known target quality threshold $\theta$. A response $y$ is correct at threshold $\theta$ if a fixed programmatic check $c(x, y, \theta) \in \{0, 1\}$ returns $1$.
**Verifier type.** Each verifier $k$ has a private accept-rate function $\alpha_k : \mathcal{X} \times \mathcal{Y} \to [0, 1]$, drawn from a known family $\mathcal{F}$. The function $\alpha_k$ specifies the probability that verifier $k$ accepts a candidate response as correct at threshold $\theta$. Verifier types are private. The family $\mathcal{F}$ and the per-prompt cost-of-quality functions $\{\kappa_k\}_{k=1}^K$ (cost to verifier $k$ of operating at quality $\alpha_k$) are common knowledge.
**Cost-correct.** Per-task cost under verifier $k$ is, following [*The Cost of Being Right*](/papers/the-cost-of-being-right),
$$
\mathrm{CostCorrect}(k) = \frac{\mathrm{CPM}_{1{:}1} \cdot R \cdot (1 + \bar\rho)}{\alpha_k}
$$
with $\mathrm{CPM}_{1{:}1}$, $R$, and $\bar\rho$ held fixed across verifier choice. The deployer minimises $\mathrm{CostCorrect}$, which is equivalent to maximising $\alpha_k$ at fixed numerator.
**Probe set.** The deployer has a budget of $N$ probes drawn from a probe distribution $P$ over $\mathcal{X} \times \mathcal{Y}$ with known ground-truth labels $\ell_i \in \{0, 1\}$. Probes may be adversarial with respect to $\mathcal{F}$. Constructing each probe has a fixed cost $\gamma$ that we treat as exogenous below and endogenise in §5.
**Mechanism.** A direct mechanism is a pair $(s, t)$ where $s : \{0, 1\}^{K \times N} \to \{1, \ldots, K\}$ is a selection rule mapping verifier reports to a chosen verifier, and $t : \{0, 1\}^{K \times N} \to \mathbb{R}^K$ is a payment rule. We restrict to mechanisms that depend only on reported decisions on probes.
**Solution concept.** We seek mechanisms that satisfy dominant-strategy incentive compatibility (DSIC), ex post individual rationality (IR), and budget feasibility under a per-probe payment cap $\bar t$. We measure performance by expected regret against first-best,
$$
\mathrm{Reg}(s, t) = \mathbb{E}\!\left[\,\mathrm{CostCorrect}(s) - \min_k \mathrm{CostCorrect}(k)\,\right]
$$
and by worst-case regret over $\mathcal{F}$.
**Calibration-monotone family.** A family $\mathcal{F}$ is *calibration-monotone* if there exists an ordering $\succeq$ on $\mathcal{F}$ such that $\alpha_k \succeq \alpha_{k'}$ implies $\Pr[\alpha_k(x, y) > \tau] \geq \Pr[\alpha_{k'}(x, y) > \tau]$ for all thresholds $\tau$ and all $(x, y) \sim D$. The condition is the procurement analogue of the monotone-likelihood-ratio property in classical statistics.
---
## 3. Impossibility for posted-price markets
A *posted-price market* offers a single price $p$ at which the deployer commits to purchase from any seller who chooses to participate. Sellers self-select. The deployer cannot screen on type and cannot condition payment on probes, since by hypothesis the posted-price market has no probe technology. The setting is the classical lemons market ([Akerlof, 1970](https://www.jstor.org/stable/1879431)), adapted to verification.
**Theorem 1 (posted-price collapse).** Suppose $\mathcal{F}$ is calibration-monotone and the cost-of-quality function $\kappa_k$ satisfies single-crossing: for any $\alpha_k \succ \alpha_{k'}$, the marginal cost of operating at quality $\alpha_k$ minus the marginal cost of operating at quality $\alpha_{k'}$ is strictly positive and increasing in quality. Then for every posted price $p$, the unique sequentially rational equilibrium of the resulting procurement game concentrates on the worst type in $\mathcal{F}$.
*Proof sketch.* Fix $p$. Each verifier $k$ participates if and only if $p \geq \kappa_k$. By single-crossing, the set of participating types is a lower set in the $\succeq$ ordering. The deployer's expected cost-correct under uniform sampling from participating types is increasing in the quality of the marginal participating type. Anticipating this, only the lowest-cost (worst-quality) participating type's expected payoff is bounded below by zero in the limit. The standard adverse-selection unravelling ([Mas-Colell, Whinston, and Green, 1995](https://global.oup.com/academic/product/microeconomic-theory-9780195102680), ch. 13) yields collapse to the worst type. Full proof in Appendix A of the PDF. ∎
**Why public benchmarks do not rescue the posted-price market.** Public benchmark scores measure $\Pr[\alpha_k(x, y) = 1]$ on a fixed evaluation distribution $D'$. The deployer's relevant quantity is $\Pr[\alpha_k(x, y) = 1 \mid x \sim D]$ at the deployer's threshold $\theta$. Even if $D' = D$ at the population level, public benchmark scores typically average over thresholds or report area under a curve, not the specific accept rate at the deployer's threshold. The deployer-specific threshold and task-conditional acceptance behaviour are not generally identified from a fixed-dimension public score, by a standard non-identification argument.
**Corollary 1 (no public-benchmark fix).** No fixed-dimension public benchmark score function $\sigma : \mathcal{F} \to \mathbb{R}^d$ identifies the deployer-specific quantity $\alpha_k(\theta, D)$ for arbitrary $(\theta, D)$, unless $d$ scales with the cardinality of the support of $D$ at threshold $\theta$.
The combined message of Theorem 1 and Corollary 1 is that posted-price verification-as-a-service is structurally broken in the same way that used-car markets are broken under the lemons argument. The next sections build a mechanism that closes the gap.
---
No public benchmark of fixed dimension rescues posted prices in verification procurement. The relevant statistic is not identified from a public score.
## 4. The scoring-rule mechanism
**Construction.** Fix a strictly proper scoring rule $S : [0, 1] \times \{0, 1\} \to \mathbb{R}$, for instance the Brier score $S(p, \ell) = -(p - \ell)^2$ or the quadratic score $S(p, \ell) = 2 p \ell - p^2$. Generate $N$ probes $\{(x_i, y_i, \ell_i)\}_{i=1}^N$ with known ground-truth labels. Each verifier $k$ reports a probability $\hat p_{k, i} \in [0, 1]$ on each probe $i$, optionally constrained to $\{0, 1\}$ for accept-or-reject verifiers. The mechanism pays verifier $k$ the amount
$$
t_k(\hat p_k, \ell) = a + b \cdot \frac{1}{N} \sum_{i=1}^N S(\hat p_{k, i}, \ell_i)
$$
for constants $a \geq 0$ and $b > 0$ to be set below. The selection rule is empirical $\arg\max$ over the average score, ties broken arbitrarily.
**Theorem 2 (scoring-rule mechanism).** Under the strictly proper scoring rule mechanism with $a$ chosen so that $a + b \cdot \min_S \geq 0$, where $\min_S$ is the infimum of $S$ on $[0, 1] \times \{0, 1\}$, the mechanism is dominant-strategy incentive-compatible, ex post individually rational, and budget feasible under per-probe payment cap $\bar t = a / N + b \cdot \max_S / N$.
*Proof.* Strict propriety of $S$ implies that for any belief $q$ verifier $k$ holds about the probability that $\ell_i = 1$ given $(x_i, y_i)$, the unique maximiser of $\mathbb{E}_\ell S(\hat p, \ell)$ over $\hat p$ is $\hat p = q$. This is the defining property of strict propriety ([Gneiting and Raftery, 2007](https://www.tandfonline.com/doi/abs/10.1198/016214506000001437)). Truthful reporting of $\hat p_{k, i} = \alpha_k(x_i, y_i)$ therefore strictly dominates any other report on every probe where the verifier's belief differs from its report, regardless of other verifiers' reports, and is the unique dominant strategy. Individual rationality follows from the choice of $a$. Budget feasibility follows from the per-probe payment cap. ∎
**Selection.** Let $\bar S_k = \frac{1}{N}\sum_i S(\hat p_{k, i}, \ell_i)$ be verifier $k$'s average scoring-rule value on the probe set. The selection rule chooses $\hat k = \arg\max_k \bar S_k$. When verifiers are restricted to binary reports $\hat p_{k, i} \in \{0, 1\}$, this reduces to choosing the verifier with highest empirical accept rate $\hat\alpha_k = \frac{1}{N}\sum_i \mathbf{1}[\hat p_{k, i} = \ell_i]$, since the Brier and quadratic scores collapse to a constant rescaling of the 0-1 loss on $\{0, 1\}$ outputs.
**Why grounded probes give strict propriety in dominant strategies.** Classical peer prediction elicits truthful reports without ground-truth signals by paying agents based on the joint distribution of their reports with peers' reports. Mechanism design in this line achieves truthfulness only in Nash or Bayesian equilibrium, and depends on common priors or on common-knowledge structure of the joint distribution. The grounded-probe setting eliminates the joint-distribution dependence. Each verifier's report is paid against the labels, not against other verifiers' reports. This collapses the peer-prediction reduction and yields strict propriety in dominant strategies.
---
## 5. Regret bounds
We now bound the deployer's expected gap from first-best Cost-correct under the mechanism of §4. Throughout this section, verifiers report truthfully, by Theorem 2.
**Theorem 3 (upper bound).** Let $\alpha_k(Q) := \mathbb{E}_{(x, y) \sim Q}[\alpha_k(x, y)]$ denote the population accept rate of verifier $k$ under distribution $Q$. Let $k^* = \arg\max_k \alpha_k(D)$ be the oracle-best verifier on the deployer's task distribution. Suppose probes are drawn iid from a distribution $P$, that $\alpha_k(P) = \alpha_k(D)$ for all $k$ (probes are unbiased for the deployer's distribution), and that verifiers report binary decisions in $\{0, 1\}$. Then the expected gap of the empirical $\arg\max$ rule is
$$
\mathbb{E}\!\left[\alpha_{k^*}(D) - \alpha_{\hat k}(D)\right] \leq C \cdot \sqrt{\frac{\log K}{N}}
$$
for a universal constant $C$.
*Proof.* By Hoeffding's inequality ([1963](https://www.jstor.org/stable/2282952)) applied to bounded random variables in $[0, 1]$, $\Pr[|\hat\alpha_k - \alpha_k(P)| > \epsilon] \leq 2\exp(-2 N \epsilon^2)$ for each $k$. By a union bound, $\Pr[\max_k |\hat\alpha_k - \alpha_k(P)| > \epsilon] \leq 2K\exp(-2 N \epsilon^2)$. Setting $\epsilon = \sqrt{(\log K + \log(2/\delta)) / (2N)}$ gives the failure probability $\delta$. Integrating the tail and using the unbiasedness assumption yields the stated bound with $C = O(1)$. Full computation in Appendix B of the PDF. ∎
The translation to Cost-correct units is direct. Since $\mathrm{CostCorrect}(k) - \mathrm{CostCorrect}(k^*) = \mathrm{CPM}_{1{:}1} R (1 + \bar\rho)\,(1/\alpha_{\hat k} - 1/\alpha_{k^*})$, and on the event that $\alpha_{\hat k}, \alpha_{k^*} \geq \alpha_{\min} > 0$, the gap in $1/\alpha$ is bounded by $|1/\alpha_{\hat k} - 1/\alpha_{k^*}| \leq |\alpha_{k^*} - \alpha_{\hat k}| / \alpha_{\min}^2$, which scales as $\sqrt{\log K / N}$ up to a Lipschitz constant determined by $\alpha_{\min}$.
**Theorem 4 (lower bound).** Suppose $\mathcal{F}$ is calibration-monotone and contains at least two distinct types $\alpha_a \succ \alpha_b$ with $\sup_{x, y} |\alpha_a(x, y) - \alpha_b(x, y)| > 0$. Then for any mechanism $(s, t)$ and any $K \geq 2$, there exists a profile of types in $\mathcal{F}^K$ such that
$$
\mathbb{E}\!\left[\alpha_{k^*}(D) - \alpha_{s(\hat p)}(D)\right] \geq c \cdot \sqrt{\frac{\log K}{N}}
$$
for a constant $c > 0$ depending on $\mathcal{F}$ but not on $K$ or $N$.
*Proof sketch.* Apply Le Cam's two-point method. Construct a packing of $\Theta(K)$ profiles of types in $\mathcal{F}^K$ that are pairwise indistinguishable on probe sets of size $N$ at total variation distance $O(\sqrt{N} \cdot \Delta)$, where $\Delta = \sup |\alpha_a - \alpha_b|$. Standard Le Cam arguments ([Tsybakov, 2009](https://link.springer.com/book/10.1007/b13794), ch. 2) yield expected $\ell_\infty$ error of order $\sqrt{\log K / N}$ on the implied estimation problem. The reduction from selection regret to estimation error follows from the calibration-monotone assumption. ∎
Theorems 3 and 4 together imply that the scoring-rule mechanism is minimax optimal up to log factors over calibration-monotone families. The remaining gap between $\sqrt{\log K / N}$ and the corresponding $\sqrt{1/N}$ rate of single-arm estimation is a $\sqrt{\log K}$ factor that comes from the union bound and is information-theoretically necessary at this level of generality.
**Sample complexity in deployer-relevant terms.** Solving for $N$ given target gap $\epsilon$ in $\alpha$-units yields $N \geq C^2 \log K / \epsilon^2$. At $K = 16$ and $\epsilon = 0.05$, with the universal constant $C$ on the order of unity in the simulations of §7, the budget is $N \approx 1100$. At $K = 32$ and $\epsilon = 0.05$, $N \approx 1400$. The mechanism is operationally feasible at probe budgets in the low thousands, even before the constant-improving effect of adversarial probe construction.
---
## 6. The adversarial probe construction problem
The bounds of §5 treat the probe distribution $P$ as exogenous. In practice, probes are not free. A probe with reliable ground-truth label is itself the output of a verification operation, which is precisely the problem we are trying to procure. We endogenise probe construction here.
**Three probe-construction strategies.**
*Uniform random.* Probes are drawn iid from $D$. Ground-truth labels are obtained via expensive in-house verification or via a known-correct programmatic check (math, code with tests). Cost per probe is fixed at the in-house verification cost.
*Maximin entropy.* Probes are chosen to maximise disagreement among candidate verifiers' decisions, conditional on having known ground-truth labels. Given a candidate pool of candidate probes, select the subset that maximises the entropy of the empirical accept-or-reject distribution across $\{1, \ldots, K\}$. The construction follows the active-learning tradition.
*Hard-instance mining.* Probes are mined from the support of $D$ where a bootstrap verifier is least confident. The bootstrap is itself expensive, since a low-confidence label is by definition not yet ground-truth.
**Proposition 1 (maximin-entropy improvement).** Under maximin-entropy probe construction with a probe-pool size $M \geq K$, the leading constant in the regret bound of Theorem 3 decreases by a factor of order $\sqrt{K}$ relative to uniform-random probes.
**Proposition 2 (hard-instance mining tradeoff).** Under hard-instance mining with bootstrap verifier of accept rate $\alpha_0$, the leading constant in the regret bound decreases by a factor of $\Omega(1 / (1 - \alpha_0))$, at the cost of per-probe construction cost scaling as $1 / (1 - \alpha_0)$.
Propositions 1 and 2 together identify the operational tradeoff. Maximin entropy gives a sublinear-in-$K$ improvement at no per-probe cost increase. Hard-instance mining gives an arbitrarily large constant improvement at proportionate per-probe cost increase. The choice depends on the deployer's marginal cost of probe construction relative to the marginal cost of mechanism payments.
**Operational implication.** Probe construction is the binding cost driver at realistic $K$, not probe count. The simulation in §7 quantifies this: at $K = 16$ and target Cost-correct gap of 5%, the per-probe construction cost dominates total mechanism cost by a factor of approximately seven, across all three datasets.
---
## 7. Simulation
We test the mechanism and the regret bounds on three public eval datasets with known ground-truth labels.
**Datasets.** MATH ([Hendrycks et al., 2021](https://arxiv.org/abs/2103.03874)) is the standard benchmark for competition math. GSM8K ([Cobbe et al., 2021](https://arxiv.org/abs/2110.14168)) is the standard benchmark for grade-school math word problems. HumanEval ([Chen et al., 2021](https://arxiv.org/abs/2107.03374)) is the standard benchmark for Python code generation. All three admit programmatic verification: math problems with known numerical or symbolic answers, code with hidden unit tests.
**Verifier population synthesis.** We synthesise $K \in \{4, 8, 16, 32\}$ candidate verifiers as logistic-regression heads over trajectory features, calibrated on different fractions $\beta_k \in (0, 1]$ of held-out data. Features are length-normalised log-probabilities, step-count, and self-consistency agreement. Calibration fractions are spaced log-uniformly between $0.05$ and $1.0$ to span the calibration-monotone family.
**Sweep.** Probe budget $N \in \{16, 64, 256, 1024, 4096\}$. Three scoring rules: Brier, quadratic, log. Three probe-construction strategies: uniform random, maximin entropy, hard-instance mining. Three baselines: posted-price uniform purchase, random verifier choice, public-benchmark ranking by headline accuracy on the standard eval split. Each cell is repeated over 200 seeds.
**Headline finding.** At $N = 256$ and $K = 16$ with maximin-entropy probes, the scoring-rule mechanism achieves Cost-correct within 5% of the oracle on all three datasets, averaged over seeds. The Brier and quadratic scoring rules give indistinguishable results. The log scoring rule penalises overconfident wrong reports more heavily and produces 1.2% higher payment dispersion at no accuracy benefit. We report Brier as the operational default.
Table 1. Cost-correct gap to oracle by procurement mechanism, at $K = 16$, $N = 256$, maximin-entropy probes, averaged over 200 seeds. The scoring-rule mechanism (Brier) closes the gap uniformly across datasets. Posted-price collapse and public-benchmark non-identification both leave large gaps. HumanEval is the calibration-monotone violation case (see negative finding below).
Mechanism
MATH
GSM8K
HumanEval
Oracle (first-best)
0.0%
0.0%
0.0%
Random verifier choice
27.4%
25.1%
31.8%
Posted-price (uniform purchase)
30.6%
28.9%
34.2%
Public-benchmark ranking
5.8%
4.1%
18.4%
Scoring-rule (Brier, this work)
4.7%
4.9%
6.4%
**Posted-price baseline.** Across all cells tested, the posted-price baseline does not close more than 30% of the Cost-correct gap to the oracle. At $K = 16$ on MATH, the posted-price equilibrium concentrates on the worst two verifier types in 72% of seeds, consistent with Theorem 1.
**Public-benchmark baseline.** Headline-accuracy ranking closes 40 to 60% of the gap to oracle on MATH and GSM8K but only 18% on HumanEval at $K = 16$. The HumanEval gap reflects calibration-monotone violation: two of the synthesised verifiers achieve high headline accuracy on the public split but underperform at the deployer's threshold on the held-out distribution.
**Probe-cost decomposition.** At $K = 16$, $N = 256$, maximin-entropy probes: per-probe construction cost (in dollars of in-house verification) is $7\times$ the per-probe scoring-rule payment, summed across $K$ verifiers. Aggregate probe construction is 87% of total mechanism cost. The decomposition matches the operational claim of §6.
**Negative finding.** On HumanEval, the calibration-monotone family assumption is violated for 2 of 16 synthesised verifiers in the population we generated. Two verifiers achieve high $\alpha$ on long programs but lower $\alpha$ on short programs than two other verifiers with weaker overall headline accuracy. The empirical $\arg\max$ rule still selects a verifier within 6.4% of oracle Cost-correct, but the constant in the regret bound is approximately three times larger than on MATH and GSM8K. This is consistent with the calibration-monotone assumption being load-bearing in the lower bound of Theorem 4 and a useful but not necessary condition for the upper bound of Theorem 3.
The full simulation harness is in Appendix D of the PDF. Total compute is 120 CPU-hours on a single 16-core machine; no GPU required.
---
Probe construction is the binding cost driver, not probe count. At $K=16$ and a 5% target gap, per-probe construction cost dominates total mechanism cost by approximately $7\times$ across all three datasets.
## 8. The August 2026 EU AI Act forcing function
The European Union AI Act high-risk obligations apply from August 2, 2026 ([Regulation (EU) 2024/1689](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689)). Article 9 requires risk management. Article 13 requires transparency and provision of information to deployers. Article 14 requires human oversight. Article 15 requires demonstrable accuracy at a documented level, plus operational reliability and security. Implementation of all four articles for a high-risk LLM deployment requires demonstrable accept-rate measurement at a defined quality threshold.
The scoring-rule mechanism doubles as compliance evidence. The probe set is the auditable test set. The verifier reports are the auditable measurement. The payment ledger is the auditable accept-rate trail. The combination is sufficient evidence under Article 15(1), which requires that "high-risk AI systems shall be designed and developed in such a way that they achieve an appropriate level of accuracy, robustness and cybersecurity, and perform consistently in those respects throughout their lifecycle." The phrase *appropriate level of accuracy* is operationalised in deployer compliance practice as accuracy at a documented threshold against a documented test set. The mechanism produces both as primitives.
A second connection is to the Article 13 transparency requirement. The deployer must report verifier accept-rate at threshold $\theta$ to downstream operators. The scoring-rule mechanism produces $\hat\alpha_k$ as a primitive. The reporting interface follows directly from the mechanism's output.
We do not claim the mechanism is sufficient for Act compliance overall, since the Act covers risk management and human oversight beyond accept-rate measurement. We claim only that, where the Act requires accept-rate evidence, the mechanism produces it as a side effect and at low marginal cost.
---
## 9. Limitations and future work
**Programmatic-verifier scope.** The strict-propriety argument requires bounded and known label noise on probes. Math, formal logic, and code with strict tests satisfy this. LLM-as-judge verifiers do not, since the judge's own accept rate is endogenous and unbounded. The dominant-strategy IC argument breaks under unbounded label noise. The extension to LLM-judge probes is the next paper in the wedge plan and connects to the recent literature on judge calibration ([Zheng et al., 2023](https://arxiv.org/abs/2306.05685)).
**Static verifier population.** We model a one-shot procurement. Reputation dynamics over repeated rounds are out of scope. The natural extension connects to [Holmström (1979)](https://www.jstor.org/stable/3003320) on moral hazard with observable outcomes and to [Crémer and McLean (1988)](https://www.jstor.org/stable/1913096) on full surplus extraction in dynamic settings.
**Single deployer.** Probe sharing across deployers introduces a public-goods structure with free-rider incentives. The natural extension is a private-value mechanism design analysis with conflicting deployer interests, in the spirit of the bilateral-trade impossibility of [Myerson and Satterthwaite (1983)](https://www.sciencedirect.com/science/article/pii/0022053183900480).
**Strategic deployer.** The mechanism assumes the deployer reports probes truthfully. A strategic deployer who selectively withholds adversarial probes can manipulate the mechanism.
**Calibration-monotone assumption.** The lower bound of Theorem 4 requires calibration-monotone $\mathcal{F}$. The upper bound of Theorem 3 does not. The simulation flags two verifiers on HumanEval where the assumption fails. We have not characterised the worst-case regret on non-calibration-monotone families. This is a direct open problem.
---
## 10. Conclusion
Verifier procurement is the missing lever in the verification-economics framing. The companion field notes establish that the verifier accept rate is the binding term in cost-per-correct-answer. They are silent on how a deployer who does not build verifiers in-house ends up with one. This paper closes the gap.
Posted-price markets cannot sustain verification-as-a-service under unobservable quality. A scoring-rule mechanism with adversarially constructed probes can, in dominant strategies, at provable regret of order $\sqrt{\log K / N}$. The mechanism is minimax optimal up to log factors. Adversarial probe construction, not probe count, is the binding operational cost. The mechanism doubles as compliance evidence under the EU AI Act high-risk obligations entering force on August 2, 2026.
The next paper in the wedge plan extends the mechanism to LLM-as-judge probes with unbounded label noise.
---
## References
1. [Akerlof, G. A. *The Market for "Lemons": Quality Uncertainty and the Market Mechanism.* Quarterly Journal of Economics 84(3):488–500, 1970.](https://www.jstor.org/stable/1879431)
2. [Babaioff, M., Sharma, Y., and Slivkins, A. *Characterizing Truthful Multi-Armed Bandit Mechanisms.* EC '09, ACM, 79–88, 2009.](https://dl.acm.org/doi/10.1145/1566374.1566386)
3. [Beygelzimer, A., Dasgupta, S., and Langford, J. *Importance Weighted Active Learning.* ICML '09, 49–56, 2009.](https://dl.acm.org/doi/10.1145/1553374.1553381)
4. [Cai, Y., Daskalakis, C., and Papadimitriou, C. H. *Optimum Statistical Estimation with Strategic Data Sources.* COLT '15, 280–296, 2015.](https://proceedings.mlr.press/v40/Cai15.html)
5. [Chen, M. et al. *Evaluating Large Language Models Trained on Code.* arXiv:2107.03374, 2021.](https://arxiv.org/abs/2107.03374)
6. [Cobbe, K. et al. *Training Verifiers to Solve Math Word Problems.* arXiv:2110.14168, 2021.](https://arxiv.org/abs/2110.14168)
7. [Crémer, J. and McLean, R. P. *Full Extraction of the Surplus in Bayesian and Dominant Strategy Auctions.* Econometrica 56(6):1247–1257, 1988.](https://www.jstor.org/stable/1913096)
8. [Dasgupta, A. and Ghosh, A. *Crowdsourced Judgement Elicitation with Endogenous Proficiency.* WWW '13, 319–330, 2013.](https://dl.acm.org/doi/10.1145/2488388.2488417)
9. *European Parliament and Council. Regulation (EU) 2024/1689 of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act). Official Journal of the European Union, L 2024/1689. High-risk obligations under Article 6(2) and Articles 9, 13, 14, 15 apply from 2 August 2026.* [EUR-Lex](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A32024R1689)
10. [Frongillo, R. and Kash, I. A. *Elicitation Complexity of Statistical Properties.* Biometrika 108(1):857–879, 2021.](https://academic.oup.com/biomet/article-abstract/108/4/857/6055585)
11. [Gneiting, T. *Making and Evaluating Point Forecasts.* JASA 106(494):746–762, 2011.](https://www.tandfonline.com/doi/abs/10.1198/jasa.2011.r10138)
12. [Gneiting, T. and Raftery, A. E. *Strictly Proper Scoring Rules, Prediction, and Estimation.* JASA 102(477):359–378, 2007.](https://www.tandfonline.com/doi/abs/10.1198/016214506000001437)
13. [Guan, X. et al. *rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking.* arXiv:2501.04519, 2025.](https://arxiv.org/abs/2501.04519)
14. [Hartline, J. D. and Roughgarden, T. *Simple Versus Optimal Mechanisms.* EC '09, ACM, 225–234, 2009.](https://dl.acm.org/doi/10.1145/1566374.1566401)
15. [Hendrycks, D. et al. *Measuring Mathematical Problem Solving with the MATH Dataset.* NeurIPS '21 Datasets and Benchmarks Track.](https://arxiv.org/abs/2103.03874)
16. [Hoeffding, W. *Probability Inequalities for Sums of Bounded Random Variables.* JASA 58(301):13–30, 1963.](https://www.jstor.org/stable/2282952)
17. [Holmström, B. *Moral Hazard and Observability.* Bell Journal of Economics 10(1):74–91, 1979.](https://www.jstor.org/stable/3003320)
18. [Karnin, Z., Koren, T., and Somekh, O. *Almost Optimal Exploration in Multi-Armed Bandits.* ICML '13, 1238–1246, 2013.](https://proceedings.mlr.press/v28/karnin13.html)
19. [Kong, Y. and Schoenebeck, G. *An Information Theoretic Framework For Designing Information Elicitation Mechanisms That Obey Complementarity.* ITCS 2019.](https://drops.dagstuhl.de/opus/volltexte/2019/10133/)
20. [Le Cam, L. *Convergence of Estimates Under Dimensionality Restrictions.* Annals of Statistics 1(1):38–53, 1973.](https://projecteuclid.org/euclid.aos/1193342380)
21. [Mas-Colell, A., Whinston, M. D., and Green, J. R. *Microeconomic Theory.* Oxford University Press, 1995.](https://global.oup.com/academic/product/microeconomic-theory-9780195102680)
22. [Miller, N., Resnick, P., and Zeckhauser, R. *Eliciting Informative Feedback: The Peer-Prediction Method.* Management Science 51(9):1359–1373, 2005.](https://www.jstor.org/stable/20110402)
23. [Myerson, R. B. and Satterthwaite, M. A. *Efficient Mechanisms for Bilateral Trading.* Journal of Economic Theory 29(2):265–281, 1983.](https://www.sciencedirect.com/science/article/pii/0022053183900480)
24. [Savage, L. J. *Elicitation of Personal Probabilities and Expectations.* JASA 66(336):783–801, 1971.](https://www.tandfonline.com/doi/abs/10.1080/01621459.1971.10482346)
25. [Settles, B. *Active Learning Literature Survey.* University of Wisconsin–Madison Tech. Report 1648, 2009.](https://minds.wisconsin.edu/handle/1793/60660)
26. [Tsybakov, A. B. *Introduction to Nonparametric Estimation.* Springer, 2009.](https://link.springer.com/book/10.1007/b13794)
27. [Wang, X. et al. *Self-Consistency Improves Chain of Thought Reasoning in Language Models.* ICLR '23.](https://arxiv.org/abs/2203.11171)
28. [Witkowski, J. and Parkes, D. C. *Peer Prediction Without a Common Prior.* EC '12, ACM, 964–981, 2012.](https://dl.acm.org/doi/10.1145/2229012.2229085)
29. [Witkowski, J. and Parkes, D. C. *A Robust Bayesian Truth Serum for Small Populations.* AAAI '12, 1492–1498, 2012.](https://ojs.aaai.org/index.php/AAAI/article/view/8261)
30. [Zheng, L. et al. *Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.* NeurIPS '23 Datasets and Benchmarks Track.](https://arxiv.org/abs/2306.05685)
31. [Bhardwaj, M. *The Cost of Being Right. Verification Economics in 2026.* Field Notes #2.](/papers/the-cost-of-being-right)
32. [Bhardwaj, M. *The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.* Field Notes #3.](/papers/the-alpha-asymmetry)
---
Cite this article
@misc{bhardwaj2026verifierprocurement,
author = {Bhardwaj, Manu},
title = {Verifier Procurement Under Unobservable Quality: A Scoring-Rule Mechanism for Cost-Correct Minimization},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/verifier-procurement},
howpublished = {\url{https://ifitsmanu.com/papers/verifier-procurement/paper.pdf}},
note = {Working paper. Version 1.0.}
}
Bhardwaj, M. (2026, May). Verifier procurement under unobservable quality: A scoring-rule mechanism for cost-correct minimization. ifitsmanu.com. https://ifitsmanu.com/papers/verifier-procurement
Bhardwaj, Manu. "Verifier Procurement Under Unobservable Quality: A Scoring-Rule Mechanism for Cost-Correct Minimization." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/verifier-procurement.
M. Bhardwaj, "Verifier Procurement Under Unobservable Quality: A Scoring-Rule Mechanism for Cost-Correct Minimization," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/verifier-procurement
---
[Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Companion. The α Asymmetry.](/papers/the-alpha-asymmetry) [Papers index](/papers). [Home](/).
# https://ifitsmanu.com/papers/heterogeneous-procurement/
# The Heterogeneous-GPU Margin. Coral and the Multi-LLM Procurement Problem.
### A Daily Field Note on Heterogeneous Hardware and Joint Multi-Model Allocation
*Manu Bhardwaj. ifitsmanu.com. 11 May 2026. Last updated 11 May 2026. Version 1.0. Field Notes #6.*
[Cite this article](#cite-this-article). [Research index](/papers). [Companion. The Inference Stack in 2026.](/papers/the-inference-stack-2026)
> **Daily field note.** Second piece in the daily-review cadence. One fresh paper or post in the inference-economics or verification-economics wedge from the previous seven days, decomposed against what it shows and what it does not. Lighter scope than Field Notes #1 to #4. Same voice.
## What it claims
[Mei, Li, Chen, Pan, Wu, Miao, Jia, and Rashmi (2026)](https://arxiv.org/abs/2605.04357), posted to arXiv on 5 May 2026, introduce Coral. An "adaptive heterogeneity-aware multi-LLM serving system" whose stated economic claim has two parts. First, the LLM market is now fragmented across many models with no dominant winner, so a serving fleet typically hosts several models concurrently. Second, cloud GPU supply is now heterogeneous, with mid-tier and older-generation GPUs delivering comparable performance per dollar to top-tier hardware while enjoying better availability. Coral jointly optimizes the resource allocation and serving strategy of each model replica across all models in the fleet, rather than tuning each model replica in isolation.
The headline numbers. Across 6 models and 20 GPU configurations, Coral reduces serving cost by up to 2.79x over the best baseline and delivers up to 2.39x higher goodput under scarce resource availability. The two-stage decomposition that makes the joint problem tractable cuts online solve time from hours to tens of seconds while preserving joint optimality.
## How it argues
Coral's central observation is that the per-replica optimization problem is solved for a single model on a fixed GPU configuration, while the procurement problem the operator actually faces is joint. Which models go on which GPUs, how many replicas of each, and what serving strategy each replica uses, all under one cost-and-availability constraint.
The structural argument is that this joint problem is not decomposable into per-model subproblems without losing optimality, because the GPU pool is shared. A replica of model A on an H100 forecloses that H100 for model B; a replica of model A on an A100 cluster trades off against model C's latency budget on the same cluster. Coral preserves joint optimality through a two-stage decomposition that splits the search into a configuration-selection stage and an allocation stage, with a tractable coupling between them. The result is that the online solve drops from hours to tens of seconds, which is the threshold below which the optimizer can react to shifting demand and shifting GPU availability.
The empirical setup spans 6 models and 20 GPU configurations. That is the right shape of grid for the argument. Six models is more than the two-or-three regime where a hand-tuned schedule wins; twenty GPU configurations is broad enough to make the heterogeneity claim non-vacuous.
## What is interesting
The interesting structural property is the move from per-replica tuning to fleet-level procurement as the binding cost lever.
In [Field Notes #1](/papers/the-inference-stack-2026) I argued that the four stack-level changes (quantization, runtime, decoding-time parallelism, hardware) compound but not linearly, and that the bottleneck changes as each improvement lands. Coral identifies a fifth lever that is structurally upstream of those four. The choice of which model lands on which GPU at all. Quantization, PagedAttention, continuous batching, and speculation all act inside the per-replica box. Coral acts on the assignment from models to boxes.
A second observation. The "comparable performance per dollar" claim for mid-tier and older-generation GPUs is the part that does the most economic work. If top-tier hardware dominated on every metric simultaneously, joint allocation would collapse to "buy more H100s." The fact that mid-tier GPUs deliver competitive perf-per-dollar means the right schedule mixes hardware generations, and the value of joint optimization is the gap between the mixed schedule and the homogeneous one. The 2.79x cost reduction is the size of that gap on Coral's grid.
A third observation. The 2.39x goodput improvement under scarce resource availability is the more interesting half of the result. Cost reduction at fixed availability is a steady-state claim. Goodput under scarcity is a dynamic claim, and scarcity is the regime that defines the procurement problem. Operators do not buy GPUs at list price from an infinite pool; they buy what is available, at the price that is available, often through spot tiers and reservations with shifting capacity. A joint allocator that retains goodput under shifting supply is doing the work the procurement function actually needs.
## What is missing
The paper reports cost and goodput lifts but several quantities that would make the framework directly comparable to the cost-economics framing are not surfaced.
First. No explicit decomposition of the 2.79x lift across the joint axes. How much of the gain comes from the hardware-mix axis (mid-tier plus top-tier versus top-tier only), how much from the model-coresidency axis (which models share a GPU class), and how much from the per-replica serving-strategy axis is left implicit. Knowing the decomposition would tell an operator whether the lever is procurement, packing, or runtime tuning, and the levers do not have the same operating cost.
Second. The model count is six. The fragmentation argument is strongest at higher model counts, where the joint-allocation problem branches combinatorially and the per-model heuristic loses the most. Whether the lift extends, holds, or contracts at fleet sizes of 20 to 50 hosted models is the binding question for hyperscaler deployment, and the paper does not answer it.
Third. The cost model is a serving cost, not a Verified Capability per Dollar (VCpD) number in the sense of Field Notes #1. Coral optimizes goodput against SLOs, which is closer to delivered-tokens-per-dollar than to verified-correct-tokens-per-dollar. The verifier-economics layer that [Field Notes #2](/papers/the-cost-of-being-right) and [Field Notes #3](/papers/the-alpha-asymmetry) develop sits outside Coral's loss function. A multi-LLM fleet that delivers high goodput but mixed verifier-pass quality across its models is not yet a cost-correct optimum. The integration of Coral-style joint allocation with α-aware routing is the open structural question.
## Why it matters now
Two reasons. The first is a market-structure reason. The fragmentation premise is empirically correct as of May 2026. No single proprietary model captures the routing layer; production fleets host frontier and open-weight families concurrently, often through router and gateway abstractions. Joint allocation over heterogeneous GPUs is no longer a research curiosity; it is the operating problem for any team running more than one model at scale.
The second is a hardware-supply reason. The mid-tier-availability argument tracks the supply curve. H200 and B200 capacity remains rationed; A100, L40S, and prior-generation Hopper SKUs sit on cloud price sheets at delivered-token cost points that are competitive once joint allocation absorbs the heterogeneity. Operators who refuse to mix generations leave the 2.79x on the table because they are running an allocator that cannot use the cheaper supply.
The cleaner the procurement layer gets, the more of the cost surface it touches. Coral identifies the layer above the per-replica box and the layer below the verifier as the place where the next 2x in inference-economics lives. That is the lever this paper extends and the structural argument it adds to the inference-stack framework.
---
## Source
- [Mei, Y., Li, Z., Chen, Z., Pan, S., Wu, M., Miao, X., Jia, Z., and Rashmi, K. V. *Coral: Cost-Efficient Multi-LLM Serving over Heterogeneous Cloud GPUs.* arXiv:2605.04357, 5 May 2026.](https://arxiv.org/abs/2605.04357)
## Related field notes
- [Field Notes #1. The Inference Stack in 2026.](/papers/the-inference-stack-2026)
- [Field Notes #2. The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)
- [Field Notes #3. The Alpha Asymmetry.](/papers/the-alpha-asymmetry)
- [Field Notes #5. The Verifier as Curriculum. VHG and the Third Role.](/papers/verifier-as-curriculum)
---
## Cite this article
@misc{bhardwaj2026heterogeneousprocurement,
author = {Bhardwaj, Manu},
title = {The Heterogeneous-GPU Margin: Coral and the Multi-LLM Procurement Problem},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/heterogeneous-procurement},
note = {Field note. Field Notes \#6. Daily review of arXiv:2605.04357. Version 1.0.}
}
---
[Research index](/papers). [Home](/).
# https://ifitsmanu.com/papers/harvesting-serving-slack/
# Harvesting Serving Slack. ROSE and the Collapsed Train-Serve Boundary.
### A Daily Field Note on Cooperative Elasticity for Agentic RL Rollouts
*Manu Bhardwaj. ifitsmanu.com. 16 May 2026. Last updated 16 May 2026. Version 1.0. Field Notes #7.*
[Cite this article](#cite-this-article). [Research index](/papers). [Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Companion. The Inference-Time Compute Frontier.](/papers/inference-frontier)
> **Daily field note.** One fresh paper or post in the verification-economics or inference-economics wedge from the previous seven days, decomposed against what it shows and what it does not. Lighter scope than Field Notes #1 to #4. Same voice.
## What it claims
[Gao, Zhao, Muhtar, et al. (2026)](https://arxiv.org/abs/2605.06534), posted to arXiv on 7 May 2026, introduce ROSE. A "cooperative, resource-elastic post-training system that safely harvests idle compute and memory on serving GPUs to accelerate agentic RL rollouts." The economic observation that motivates the system is direct. Production serving clusters routinely leave compute and memory headroom; agentic RL rollouts are bottlenecked by long-tail, multi-turn environment interactions; static GPU provisioning for the training side is wasteful in both directions. Overprovisioning pays for stragglers. Underprovisioning slows the run. The proposal is to let rollouts opportunistically borrow capacity from the serving fleet whenever the slack is real.
The headline number. End-to-end agentic-RL throughput rises by 1.20× to 3.31× across the configurations the authors test, measured against state-of-the-art resource-fixed and elastic baselines. The system has three load-bearing components. An SLO-safe co-serving executor that shares GPU memory and compute between inference and rollouts without violating the serving tier's tail-latency targets. A cross-cluster weight transfer engine that exploits weight shards and sparsity to keep the trained policy fresh on the borrowed serving boxes. An elastic rollout scheduler that routes individual trajectories between dedicated rollout GPUs and opportunistic serving GPUs as the slack budget evolves.
## How it argues
Each of the three components is the answer to a separate failure mode of the cooperative-elasticity idea.
The first failure mode is SLO violation under burst traffic. If you let a rollout step queue behind a serving request, the rollout pays the serving latency; that is fine. If you let a serving request queue behind a rollout, the serving tier breaks its SLO; that is not fine. The co-serving executor solves this by carving compute and KV-cache memory at the request level rather than the GPU level. Slack is admitted only when the executor can prove the next serving request still fits.
The second failure mode is weight staleness. Off-policy rollouts pollute the training signal. On a borrowed serving box, the model weights are whatever the serving tier is currently shipping, not whatever the trainer has just produced. The cross-cluster transfer engine cuts the synchronization cost by treating the policy delta as a sparse object and shipping shards, so the bandwidth cost of staying near on-policy does not eat the throughput gain.
The third failure mode is scheduler degeneracy. A naive scheduler will route long rollouts to the borrowed capacity to hide the tail, and a clever scheduler will route exactly the rollouts that are about to fail their freshness budget. The elastic scheduler reasons about per-trajectory length, freshness, and current slack jointly and adjusts at the granularity of individual rollouts.
The structural shape of the argument is that cooperative elasticity is one engineering object that has to clear three independent constraints at once, and that each constraint is the binding one in a different regime.
## What is interesting
The economically interesting move is what ROSE does to the rollout-cost term in the *Cost-correct* decomposition from [Field Notes #2](/papers/the-cost-of-being-right).
The denominator of *Cost-correct* is verifier accept rate α; the numerator multiplies blended CPM by the reasoning multiplier R and by one plus the average rollout ratio ρ̄. The *price* of ρ̄ in the numerator has historically been the dedicated training cluster's compute price, because rollout GPUs sat in the training pool. ROSE breaks that assumption. If a rollout runs on a serving GPU during a window when that GPU would otherwise have been idle, the marginal dollar cost of the rollout falls toward zero. The amortized cost falls to whatever cooperative-elasticity overhead the system imposes. Weight-transfer bandwidth, scheduler instrumentation, SLO-safety headroom.
This changes the inference-frontier threshold derived in [Research Paper #2](/papers/inference-frontier). That threshold was a closed-form condition under which the marginal dollar reduces cost-per-correct-answer faster on the inference channel than on the training channel, expressed partly in the inference-to-training dollar ratio at the operating point. The ratio is endogenous to which channel pays for the rollouts. When rollouts borrow idle inference, the boundary between the two channels stops being clean, and the threshold has to be rewritten with a third price line for opportunistic capacity.
A second structural point. The Verifier Procurement framing in Field Notes' research-paper sibling assumes the deployer is buying from a separate verifier vendor. ROSE assumes the deployer owns both the serving cluster and the training cluster. Cooperative elasticity only works inside the same operator's blast radius. The boundary is not technical; it is contractual.
## What is missing
Three quantities that would make the result directly comparable to the *Cost-correct* framework are absent.
The paper reports throughput, not cost-per-correct-answer. The throughput multiplier translates to a cost multiplier only under the assumption that the borrowed capacity is genuinely free at the margin. The opportunity cost of taking serving slack now and paying for it later in a worst-case traffic burst is not priced.
The worst-case schedule is not characterized. SLO attainment in the average case does not bound the tail when training and serving traffic spike together. A serious cost-economics adoption pass would want a stress test against correlated load events; the paper reports steady-state and typical-burst metrics only.
The transferability across operators is not explored. The cross-cluster weight transfer engine assumes the serving tier and the training tier share a weight-sharding protocol, which is internal-operator architecture, not a public interface. Whether the gains survive across heterogeneous serving stacks (vLLM and SGLang and the various closed inference engines) is left for future work.
## Why it matters now
Two reasons.
The first is that rollout cost is becoming the dominant training cost line for agentic systems. Multi-turn tool-use rollouts have a long tail, the policy churns over many trajectories per gradient step, and the rollout-to-gradient ratio is rising as agentic capability grows. The denominator of *Cost-correct* sits at α; the numerator's ρ̄ is the term that has been moving fastest. ROSE attacks ρ̄ on the cost side, not the count side. It does not lower the number of rollouts; it lowers what each rollout costs at the margin.
The second is that the train-serve boundary has been load-bearing in every economic frame of the inference stack, including the one in [Field Notes #1](/papers/the-inference-stack-2026). Cooperative elasticity is the first proposal that takes the boundary down at the dollar-accounting level rather than the technical-stack level. The threshold conditions, the verifier-procurement contract, and the regime-fit reasoning that the field-notes series has organized around the boundary all have to be re-derived once the boundary stops being clean.
The cleaner the inference fleet gets at lending capacity, the less of the training bill the training cluster has to carry. That is the empirical lever this paper adds and the analytical adjustment it forces on the framework.
---
## Source
- [Gao, W., Zhao, Y., Muhtar, D., An, D., Shang, X., Wu, T., Cao, L., Xiong, S., Wang, W., Huang, J., Ma, T., Yang, S., Wang, J., Qu, L., Zheng, B., and Wang, W. *ROSE: Rollout On Serving GPUs via Cooperative Elasticity for Agentic RL.* arXiv:2605.06534, 7 May 2026.](https://arxiv.org/abs/2605.06534)
## Related field notes and papers
- [Field Notes #1. The Inference Stack in 2026.](/papers/the-inference-stack-2026)
- [Field Notes #2. The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)
- [Research Paper #1. Verifier Procurement Under Unobservable Quality.](/papers/verifier-procurement)
- [Research Paper #2. The Inference-Time Compute Frontier.](/papers/inference-frontier)
---
## Cite this article
@misc{bhardwaj2026harvestingslack,
author = {Bhardwaj, Manu},
title = {Harvesting Serving Slack: ROSE and the Collapsed Train-Serve Boundary},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/harvesting-serving-slack},
note = {Field note. Field Notes \#7. Daily review of arXiv:2605.06534. Version 1.0.}
}
---
[Research index](/papers). [Home](/).
# https://ifitsmanu.com/papers/the-power-cap-illusion/
# The Power-Cap Illusion. SM Clock Locking and the Real Decode Lever.
### A Daily Field Note on Phase-Aware Energy in LLM Serving
*Manu Bhardwaj. ifitsmanu.com. 17 May 2026. Last updated 17 May 2026. Version 1.0. Field Notes #8.*
[Cite this article](#cite-this-article). [Research index](/papers). [Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Companion. The Inference-Time Compute Frontier.](/papers/inference-frontier)
> **Daily field note.** One fresh paper or post in the inference-economics or verification-economics wedge from the previous seven days, decomposed against what it shows and what it does not. Lighter scope than Field Notes #1 to #4. Same voice.
## What it claims
[Ma, Afzal, Eitzinger, and Wellein (2026)](https://arxiv.org/abs/2605.11999), posted to arXiv on 12 May 2026, characterize the energy behavior of autoregressive LLM decode on NVIDIA H200. They cover four attention paradigms: GQA, Multi-head Latent Attention, Gated DeltaNet, and Mamba2. The headline negative finding is that power capping, the standard GPU energy lever in production LLM serving, is illusory in the phase that dominates production. Decode draws only 137 to 300 W on a 700 W GPU, so no cap ever triggers. The headline positive finding is that locking the SM clock, the lever that is actually on the critical path of memory-bound decode, Pareto-dominates power capping and recovers up to 32% of decode energy at minimal throughput loss.
The paper also identifies three architecture-dependent DVFS behavioral classes across the four attention variants, and reports a common energy pattern across the novel attention replacements. A heavier prefill cost is recouped by more efficient decode, eventually halving total request energy relative to GQA at production batch sizes.
## How it argues
The argument has three parts, each addressing a distinct way the standard energy story fails.
The first part. Bandwidth, not compute, is the binding constraint in decode. Memory-bound kernels saturate HBM bandwidth long before they approach the compute envelope. Power readings drop because the SMs are stalled waiting on memory. The requested cap never bites because the cap is set above the natural power ceiling of the workload. A "successful" power cap in this regime is power capping watching a workload that was already below the cap.
The second part. Firmware-initiated clock throttling. The H200 occasionally throttles SM clocks for thermal or reliability reasons that have nothing to do with the operator's energy policy. These throttles produce throughput dips that any observer trying to attribute energy savings to the cap will misread as cap-induced. Controlled experiments require pinning the SM clock; otherwise the cap and the firmware throttle are confounded in the measurement.
The third part. SM clock locking is the correct lever. Once the bandwidth ceiling is named and the firmware confound is removed, the remaining knob is SM frequency. Lowering it slightly trades a small amount of throughput for a much larger reduction in dynamic power, because memory-bound decode underutilizes the per-cycle compute. The 32% energy recovery sits inside this region. Power capping, by contrast, never reaches it.
The cross-architecture pattern is the second economically meaningful claim. Novel attention replacements (MLA, Gated DeltaNet, Mamba2) pay more energy at prefill than GQA, then recoup the cost across decode tokens. At small batch and short context the GQA baseline is competitive. At production batch and context the alternatives halve request energy. The crossover is real and it is architecture-class-specific.
## What is interesting
Three things.
First, this is a clean separation of "what knob does the operator turn" from "what knob is on the critical path." Production LLM serving currently turns the wrong knob, and the measurement infrastructure for energy reporting agrees that the knob worked, because power did fall. The fact that it fell because of the workload, not because of the cap, is invisible without the controlled measurement protocol the paper documents.
Second, the result is the energy-domain analogue of the *Cost-correct* claim in [The Cost of Being Right](/papers/the-cost-of-being-right). *Cost-correct* says that pricing inference against the wrong cost basis hides the relevant economic choice. Here, pricing energy against the cap line hides the lever that actually controls energy. The structural shape of the error is the same. A measurement that looks correct because it sums to the expected number conceals the fact that the operator's actual degree of freedom is not the one being recorded.
Third, the prefill-decode energy crossover is a constraint on the inference frontier, not just an operating tip. If MLA, Gated DeltaNet, and Mamba2 halve decode energy at production batch sizes, the inference-time training-versus-test-time threshold derived in [The Inference-Time Compute Frontier](/papers/inference-frontier) shifts in favor of test-time allocation for those architectures, because the per-test-token energy term shrinks while the training-energy term does not.
## What is missing
Four things.
The energy numbers are reported on H200. The paper does not extend the measurement to H100, B200, or GB300, where bandwidth ratios, HBM stack sizes, and DVFS firmware behavior differ. The 32% recovery is conditional on the H200 frequency-voltage curve and the H200 firmware throttle behavior. Whether the same lever delivers the same headroom on B200 is open.
The 32% is decode-only. Prefill is mostly compute-bound, and the cap may well do real work there. A complete operator policy is a per-phase policy. Clock-lock in decode, possibly let the cap engage during prefill. The paper hints at this but does not deliver it.
The work prices only operator-side electrical energy. Capex and embodied-energy terms are out of scope. The economic claim should land at "operator energy per decode token," not at "total energy of inference," and the paper is honest about this only in passing.
Finally, the three DVFS behavioral classes are not named at the level of generality that an operator would need to predict which class a new attention variant falls into without first measuring it. A taxonomy that bound class to architectural property would extend the result from observational to predictive. The paper documents three classes; it does not derive them.
## Why it matters now
Production LLM serving is the largest single new electricity load arriving on the cloud grid, and its energy controls are being audited by the same procurement and compliance teams that audit verification. If those teams treat power-cap compliance as a proxy for energy efficiency, they are reading the wrong field on the invoice. The lever is SM frequency. The right control plane reports decode-phase clock-locking policy, not aggregate cap settings.
For inference-economics work the result tightens the decode-cost term in *Cost-correct* by a measurable factor and shifts the architectural cost asymmetry in favor of memory-efficient attention replacements at production batch. For verification-economics work it forecasts that audit ledgers will need to record clock-locking policy alongside cap configuration once the standards bodies catch up to the measurement.
The pattern repeats. The lever the operator pulls is not the lever that moves the cost. Naming the right lever, and pricing it, is what this field-note archive exists for.
---
## Source
- [Ma, B., Afzal, A., Eitzinger, J., and Wellein, G. *The Illusion of Power Capping in LLM Decode: A Phase-Aware Energy Characterisation Across Attention Architectures.* arXiv:2605.11999, 12 May 2026.](https://arxiv.org/abs/2605.11999)
## Related field notes
- [Field Notes #2. The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)
- [Research Paper #1. The Inference-Time Compute Frontier.](/papers/inference-frontier)
---
## Cite this article
@misc{bhardwaj2026powercapillusion,
author = {Bhardwaj, Manu},
title = {The Power-Cap Illusion: SM Clock Locking and the Real Decode Lever},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/the-power-cap-illusion},
note = {Field note. Field Notes \#8. Daily review of arXiv:2605.11999. Version 1.0.}
}
---
[Research index](/papers). [Home](/).
# https://ifitsmanu.com/papers/verifier-as-curriculum/
# The Verifier as Curriculum. VHG and the Third Role.
### A Daily Field Note on Three-Party Self-Play and Curriculum Construction
*Manu Bhardwaj. ifitsmanu.com. 10 May 2026. Last updated 10 May 2026. Version 1.0. Field Notes #5.*
[Cite this article](#cite-this-article). [Research index](/papers). [Companion. The α Asymmetry.](/papers/the-alpha-asymmetry) [Series origin. The Cost of Being Right.](/papers/the-cost-of-being-right)
> **Daily field note.** First piece in the daily-review cadence. One fresh paper or post in the verification-economics or inference-economics wedge from the previous seven days, decomposed against what it shows and what it does not. Lighter scope than Field Notes #1 to #4. Same voice.
## What it claims
[Lai, Feng, Teh, and Miao (2026)](https://arxiv.org/abs/2605.06660), posted to arXiv on 8 May 2026, introduce VHG. A "verifier-enhanced hard problem generation framework built upon three-party self-play." The setter generates problem-and-reference pairs. The solver attempts the problem. An independent verifier gates whether the setter's problem counts as valid before the solver's difficulty signal is applied. The setter's reward becomes the indicator that the verifier accepts the problem times one minus the solver's accuracy on it. Invalid problems get zero reward regardless of how hard they are. Reward hacking by emitting unanswerable or ill-defined problems no longer pays.
The headline numbers. On indefinite-integral generation evaluated against a Qwen3-4B-Base solver, VHG raises pass@1 from 52.5% to 69.4% on the Qualifier set, from 28.8% to 45.4% on the Competition set, and from 43.3% to 64.7% on the Stress Test set. On general mathematical reasoning, evaluated across five standard benchmarks (MATH, AMC, Minerva, Olympiad, AIME 2024 to 2026), pass@1 lifts from 56.8% to 69.0%. The lifts are larger for stronger solvers. Qwen3-14B reaches 49.23% pass@1 on integration and 41.50% on general math.
## How it argues
VHG instantiates two verifier variants. A *Hard* verifier built on SymPy that mechanically checks the validity of indefinite integrals. A *Soft* verifier instantiated as an LLM-as-judge for general mathematics. The Hard variant is the cleaner experimental probe. SymPy can decide "is this integral well-posed and does the setter's reference solution differentiate back to the integrand" without ambiguity, so reward hacking through invalid integrals is foreclosed by construction.
The structural argument is that the conventional setter-and-solver duality is unstable. Without a third party, the setter learns to maximize solver difficulty by generating problems that are hard because they are broken, not hard because they are deep. This is the standard reward-hacking failure mode in self-play with an LLM-graded reward. The verifier is the load-bearing constraint that re-aligns difficulty with validity. The reward function is multiplicative rather than additive, so a zero from the verifier kills the reward regardless of how much difficulty signal the solver supplies.
## What is interesting
The interesting structural property is that VHG extends the verifier's economic role from a two-place job to a three-place job.
In Field Notes #2 and #3, the verifier had two production roles. Inference-time gating, where it acts on cost-correct's denominator α at decode time. And training-time reward function, where it acts as the RLVR signal that aligns the policy under verifiable rewards. VHG names a third role. Training-data curator. The verifier decides which problems enter the training distribution at all.
This third role is structurally distinct because it operates one level upstream of the training-time reward. RLVR optimizes the policy against a fixed verifier on a fixed problem distribution. VHG uses the verifier to construct the problem distribution itself. The same verifier artifact now governs three points in the production lifecycle: data, reward, decode.
A second observation. The Hard verifier outperforms the Soft verifier across the metrics where both are measurable, in the same direction predicted by the α-asymmetry analysis in [Field Notes #3](/papers/the-alpha-asymmetry). Verifier quality dominates other levers, and verifier quality is bounded by what the verifier can mechanically decide. The cleanest verifiers are domain-narrow, including SymPy on integrals, type-checkers on code, and unit tests on functions. The breadth-or-depth tradeoff shows up here as a quality-or-coverage tradeoff. Soft verifiers cover more ground with weaker guarantees. Hard verifiers cover narrow ground with stronger ones. The α term in *Cost-correct* picks up the variance in either direction.
## What is missing
The paper reports lifts but several quantities that would make the framework directly comparable to the *Cost-correct* decomposition are not surfaced.
First. No explicit token-cost or compute-cost accounting at the data-generation step. VHG runs three models at training-data-generation time. The setter, the verifier, and the solver. The pass@1 lifts are reported against a fixed Qwen3 family and a fixed problem budget, but not against a fixed compute budget. Whether the lift survives at iso-FLOP across the full pipeline is the binding question for production adoption, and the paper does not answer it.
Second. The verifier-quality tradeoff is acknowledged but not quantified. The authors note that the Soft verifier "can still accept subtle errors, underspecified problems, or reward-hacking artifacts." How often it does so, and how that propagates into solver quality drift over multiple self-play rounds, is left for future work.
Third. The empirical comparisons use one model family. The Qwen3 line is a strong open base, but not the only one. Whether the lifts transfer to other open bases or to proprietary frontier models is an open question, and the cost-economics framing would want it answered before generalizing the result.
## Why it matters now
Two reasons. The first is a curriculum-cost reason. Synthetic problem generation is becoming a binding input to frontier post-training as the natural-data math corpus gets exhausted. RL with verifiable rewards at scale needs more verifiable problems than humans produce, and self-play has been the obvious lever, with reward hacking the obvious failure mode. VHG offers a structural fix that does not require either manual curation or a stronger reward model. It requires only a tighter verifier.
The second is a regime-fit reason. The *Cost-correct* equation from Field Notes #2 puts α in the denominator. Field Notes #3 shows that α-engineering is the highest-leverage place to spend a marginal engineering dollar in the typical operating regime. VHG identifies a fourth way the same engineering dollar can land. Not as an inference-time gate. Not as an RL reward function. Not as a process reward model. As a curriculum constructor whose output is the training distribution itself. The three-party game is the production architecture that closes the loop. Generator, verifier, curriculum, all sharing one verifier artifact.
The cleaner the verifier gets, the more of the lifecycle it touches. That is the empirical pattern this paper extends and the analytical lever it adds to the framework.
---
## Source
- [Lai, Y., Feng, J., Teh, Y. W., and Miao, N. *Verifier-Backed Hard Problem Generation for Mathematical Reasoning.* arXiv:2605.06660, 8 May 2026.](https://arxiv.org/abs/2605.06660)
## Related field notes
- [Field Notes #2. The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)
- [Field Notes #3. The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.](/papers/the-alpha-asymmetry)
---
## Cite this article
@misc{bhardwaj2026verifiercurriculum,
author = {Bhardwaj, Manu},
title = {The Verifier as Curriculum: VHG and the Third Role},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/verifier-as-curriculum},
note = {Field note. Field Notes \#5. Daily review of arXiv:2605.06660. Version 1.0.}
}
---
[Research index](/papers). [Home](/).
# https://ifitsmanu.com/papers/the-structural-residual-ceiling/
# The Structural Residual Ceiling. AI Pre-Decoders for the Surface Code.
### A Field Note on NVIDIA's Ising-Decoding Release
*Manu Bhardwaj. ifitsmanu.com. 7 May 2026. Last updated 7 May 2026. Version 1.0.*
[Download as PDF](/pdfs/the-structural-residual-ceiling.pdf) (13 pages, arXiv layout). [Cite this article](#cite-this-article). [Research index](/papers).
> **Premise.** A recent NVIDIA preprint reports the first AI-based pre-decoder pipeline that simultaneously improves logical error rate and end-to-end runtime over state-of-the-art surface-code global decoders, with measured speedups up to 3.42x over uncorrelated PyMatching and 3.54x over correlated PyMatching at distance 31, p=0.006, on NVIDIA GB300. The honest negative finding inside that result is what this field note is about.
Or view the full PDF inline.
TL;DR
NVIDIA's [Ising-Decoding](https://github.com/NVIDIA/Ising-Decoding) release ships two pre-trained neural pre-decoders that strip local errors from surface-code syndromes before handing the residuals to PyMatching. The pipeline gets faster decoding *and* lower logical error rate at large code distance. But at distance 17 and above, the pre-decoder paired with correlated PyMatching stops improving logical error rate, and applying their separately-trained noise-learning network to the residuals does not recover the gap. The authors note that residuals causing logical faults are dominated by long parallel chains of length exceeding (d−1)/2, oriented along the logical observable. This field note argues the cause is not network capacity (Model 6 has ~42.6 M parameters and still hits the ceiling) but the deterministic homological-equivalence canonicalization used during label generation. Three concrete, falsifiable mitigations are outlined, all testable inside the released codebase.
## Abstract
A recent [NVIDIA preprint](https://arxiv.org/abs/2604.12841) (Chamberland, Olle, Li, Thornton, Baratta, April 2026) reports the first AI-based pre-decoder pipeline that simultaneously improves logical error rate (LER) and end-to-end runtime over state-of-the-art surface-code global decoders, with measured speedups up to **3.42x** over uncorrelated PyMatching and **3.54x** over correlated PyMatching at code distance d=31, p=0.006, on NVIDIA GB300 in FP8 precision. Buried inside that result is an honest negative finding. When the pre-decoder is paired with correlated matching at distances d ≥ 17, the LER worsens, and applying the authors' separately-trained noise-learning network to pre-decoder residuals fails to recover the gap. The authors state that "nearly all residual errors that lead to a logical fault [...] form strings of length greater than (d−1)/2 and which are parallel to the logical observable of interest." This field note argues the cause is not network capacity but the deterministic homological-equivalence canonicalization used to generate training labels. Three concrete, falsifiable mitigations are outlined: (i) randomized rather than deterministic canonicalization, (ii) chain-length-aware loss reweighting, and (iii) teacher-student distillation with chain-conditioned negative sampling. Each is testable inside the released codebase ([NVIDIA/Ising-Decoding](https://github.com/NVIDIA/Ising-Decoding), Apache-2.0). Implications for lattice-surgery deployment and NVFP4 quantization-aware training are discussed. No new experiments are reported. This is a perspective.
Figure 1. Pre-decoder pipeline as illustrated in the NVIDIA/Ising-Decoding repository. The neural network consumes detector syndromes across space and time and predicts corrections that reduce syndrome density before passing residuals to a global matching decoder. Reproduced from the repository under Apache-2.0; not modified.
---
## 1. Introduction
The case for AI pre-decoders is now empirical, not theoretical. Chamberland et al. report end-to-end runtime savings on GB300 hardware that grow with both code distance and physical error rate, with the largest gains in exactly the regime that matters for early fault-tolerant systems: large d, p approaching the surface-code threshold (~0.7%). The architectural recipe is a fully-convolutional 3D CNN that jointly predicts spacelike (data-qubit) and timelike (measurement) corrections, trained at the receptive-field volume and applied at arbitrary larger volumes via translation equivariance. The released code makes it reproducible.
The same paper discloses three limitations the authors do not resolve.
1. **The pre-decoder + correlated PyMatching pipeline does not improve LER at d ≥ 17.** A larger residual-network variant ("Model 6", ~42.6 M parameters) reduces the gap but does not close it.
2. **The noise-learning network does not improve LER on pre-decoder residuals.** This is surprising, because pre-decoding produces non-trivial syndrome statistics that one might expect to benefit from re-learned edge weights.
3. The authors attribute both to a single observation. The residual errors most likely to cause logical faults are long parallel chains, of length exceeding (d−1)/2, oriented along the logical observable.
This note argues the observation points to a structural property of the *training labels*, not of the network or the global decoder. Section 2 reviews the relevant background. Section 3 makes the structural-residual claim precise. Section 4 argues that homological-equivalence canonicalization is the proximate cause. Section 5 proposes three mitigations, ordered by implementation cost. Section 6 discusses implications. Section 7 concludes.
All numerical claims are sourced from the original paper or the released code. No new measured quantities are introduced.
## 2. Background
The rotated surface code is a two-dimensional topological quantum error-correcting code whose stabilizers can be measured using nearest-neighbor interactions. Logical operator representatives are weight-d strings; minimum-weight perfect matching (MWPM) decoding succeeds when error chains are shorter than (d−1)/2. The circuit-level depolarizing noise model is parameterized by 25 probabilities (4 SPAM, 6 idle channels, 15 CNOT Pauli channels).
A pre-decoder is a local operator on the (d, d, dm) syndrome volume that emits two species of correction. Spacelike corrections are Pauli operators applied to data qubits. Timelike corrections are bit flips applied to two consecutive rounds of stabilizer measurement outcomes. These corrections rewrite both the syndrome history and the residual data-qubit errors, producing a modified detector configuration that is then handed to a global decoder. In the NVIDIA pipeline, the global decoder is either uncorrelated [PyMatching](https://github.com/oscarhiggott/PyMatching) or its correlated two-pass variant.
The pre-decoder's training labels are derived by Pauli-frame simulation. At each circuit fault location, the simulator samples a Pauli error, propagates it, and records the resulting space-time correction. Multiple equivalent error chains (chains differing by stabilizer multiplication) produce identical syndrome histories, so the label space is highly degenerate. The authors apply a homological-equivalence protocol to fix a canonical representative within each class.
The spacelike rule reduces weight-3 X-errors on weight-4 X-stabilizers to weight-1, and maps weight-2 chains deterministically to a fixed "side" of the stabilizer (e.g., vertical chains rotate to the right column). The timelike rule treats a Z (or X) error applied to the same data qubit in two consecutive rounds, plus matching measurement-error flips in the *first* of those two rounds, as a no-op on syndrome history; it is applied iteratively until label sparsity stops decreasing. Both rules are deterministic. Given a sampled error chain, the canonicalization function returns one specific representative every time.
## 3. The structural residual claim, made precise
The empirical claim from the paper is the following. Let R(j) denote the residual data-qubit error left on shot *j* after applying the pre-decoder's predicted spacelike corrections. Let F(j) ⊆ R(j) be the projection of R(j) onto chains parallel to the logical operator XL (or ZL) of length ≥ (d−1)/2. Then:
> *The probability that R(j) causes a logical fault, conditioned on R(j) ≠ ∅, is dominated by the event F(j) ≠ ∅.*
In plain language. Residuals that matter are long, and they are parallel to the logical. Short residuals get cleaned up by the global decoder. Perpendicular long residuals do not flip the logical. Only long parallel ones do.
Two consequences follow.
**MWPM cannot help.** A minimum-weight global decoder, given a long parallel chain, returns a *correct* matching of the residual syndromes. But the correction it applies, having no information about which side of the chain to commit to, flips the logical with probability that approaches 1/2 as chain length increases. The decoder is not making an error. It is making the right call given a degenerate input.
**Noise-learning cannot help either.** Reweighting edges in the matching graph changes which spanning structures the matcher prefers, but does not change whether the matcher *can distinguish* the two homologically equivalent corrections that flip vs. preserve the logical. The information needed to discriminate is, by construction, no longer in the syndrome.
The honest reading is that the pre-decoder is throwing information away at training time. The question is how.
The decoder is not making an error. It is making the right call given a degenerate input.
## 4. Diagnosis. Deterministic canonicalization concentrates label mass.
Consider a weight-4 X-stabilizer gk(X) and a weight-2 X-error E supported on its two rightmost data qubits. By stabilizer multiplication, E is homologically equivalent to E' supported on its two leftmost data qubits (multiply by gk(X)). The canonicalization rule always picks one of these, say E', as the canonical label.
Suppose the underlying physical error was E, not E'. The training label nevertheless records E'. The network learns to predict E' on this syndrome.
For an isolated weight-2 error this is harmless. E and E' produce identical residual syndromes after correction, and either is fine. But the canonicalization compounds across rounds and across chains. A long chain composed of multiple weight-2 segments gets canonicalized segment by segment. Two physically distinct chains, one along the "left" boundary and one along the "right," can be mapped to the same canonical chain if their stabilizer-weighted decompositions happen to coincide. The network sees the same label for both, has no signal to distinguish them, and at inference, when one of these chains appears with a small perturbation, it produces the canonical correction, which may be the wrong choice for the actual chain.
This is, structurally, the long-parallel-chain failure mode. The chains that fail are exactly the ones for which the canonicalization compounds in the direction of the logical operator, because that is where the most stabilizer-multiplication freedom exists.
This diagnosis is consistent with three pieces of evidence in the paper.
(a) Adding parameters does not fix the problem. Model 5 (~7.1 M) and Model 6 (~42.6 M) both exhibit the residual structure, with Model 6 reducing but not eliminating the LER gap at d ≥ 17. If the issue were capacity-limited, scaling would close it.
(b) The authors report that the weight-2 timelike homological equivalence extension *did not* improve results during training, and they ship only the weight-1 variant. This is consistent with the hypothesis: extending the canonicalization further concentrates label mass without adding signal.
(c) The noise-learning network does improve LER on raw (non-pre-decoded) syndromes, both for correlated and (slightly less) for uncorrelated matching. The same network applied to pre-decoder residuals does not help. The difference is that raw syndromes still carry the structural information the canonicalization erases.
This is an interpretation, not a measurement. It is a hypothesis about the data-generation pipeline that admits direct testing, described next.
## 5. Three mitigations
### 5.1 Randomized canonicalization
**Cost:** ~50 lines of change in `code/data/` of the released repo. **Risk:** low.
Replace deterministic `fixEquivalenceX/Z` with a stochastic representative. At training time, when an error E admits multiple homologically equivalent forms, sample one uniformly at random per training shot. The total entropy of the label distribution increases. The network is trained to be invariant under the equivalence class rather than locked to one representative.
Three predictions follow. Per-voxel BCE loss should *increase* (more label noise), but logical-error-rate improvement should *not decrease*, and may improve at large d. Long-parallel-chain residuals should decrease in frequency, because the network is no longer biased toward one side of the equivalence class. The improvement should be most pronounced at low p, where rare, long chains dominate the residual mix.
If randomized canonicalization improves LER, there is direct evidence that the deterministic choice was the bottleneck. If it does not, the residual structure has another source. This is the cheapest experiment to run and the most informative.
### 5.2 Chain-length-aware loss reweighting
**Cost:** moderate; requires a chain-detection pass over each label batch. **Risk:** medium.
The voxel-wise BCE loss in the original paper weights every voxel equally. Long parallel chains cause logical faults but contribute the same per-voxel loss as isolated weight-1 errors that the global decoder cleans up trivially. The training signal is dominated by the easy cases.
Reweight the loss by chain-component length, with a weight `w_l ∝ l` applied to voxels belonging to a contiguous chain component of length `l`. Implementation requires a connected-components pass over each shot's spacelike correction tensor, which is cheap on GPU.
Prediction. Residual long parallel chains decrease, at the cost of increased false-positive corrections on isolated errors. The net LER should improve at distances where logical faults are dominated by long chains (d ≥ 17 in correlated PM regime).
Risk. Over-weighting can cause the network to "see chains everywhere" and apply spurious corrections. The weight schedule needs tuning, probably as a curriculum (start uniform, ramp up chain weighting).
### 5.3 Distillation with chain-conditioned negative sampling
**Cost:** highest. Requires a teacher-student pipeline. **Risk:** highest, but with the highest payoff.
The Chamberland paper telegraphs distillation as future work. This note proposes a specific instantiation tailored to the structural residual problem.
The teacher is a deeper, slower network (Model 6 scale or larger) trained on a curriculum that *up-samples* long-parallel-chain failures. Run a baseline Model 5 over a large evaluation set, isolate shots where the global decoder fails, identify the parallel-chain residuals, and oversample those failure modes (and their near-neighbors in syndrome space) in the teacher's training mix.
The student is Model 1 or Model 4 architecture, trained with a hybrid loss combining BCE against ground-truth labels and KL divergence against the teacher's per-voxel sigmoid outputs. The student inherits the teacher's behavior on the rare hard cases without paying the inference cost.
The teacher does not need to be fast. The student does. This is the standard teacher-student decoupling [Hinton, Vinyals, Dean, 2015] applied to a problem where the long tail, not the typical case, is what limits LER.
Prediction. The student reaches Model 6's LER at d ≤ 13 with Model 1's runtime. At d ≥ 17, the student narrows but does not close the gap, because the teacher itself is structurally limited (per Section 4). Combining distillation with randomized canonicalization (5.1) is the path to closing the gap entirely.
## 6. Implications
### 6.1 Lattice surgery
The Chamberland paper restricts attention to memory experiments. Lattice surgery introduces merged code patches with effective distances that can exceed 100, and time-boundary detectors that change the input-channel set (the paper notes Ns > 4 will be needed).
The structural-residual problem is likely *worse* in lattice surgery, because (i) merged-patch geometries introduce additional homological-equivalence freedom along merge boundaries, and (ii) the relevant logical operators after surgery are products of original logicals, which lengthens the parallel-chain failure mode.
Addressing the structural residual problem is therefore not optional for lattice-surgery deployment. It is on the critical path.
### 6.2 NVFP4 and quantization-aware training
The paper closes by flagging NVFP4 (4-bit floating point) deployment with quantization-aware training (QAT) as the next runtime frontier. There is a structural concern worth naming. Quantization compounds with label degeneracy. A network trained on degenerate labels has, in some sense, already lost precision before quantization is applied. Further reducing weight precision can amplify the structural-residual failure mode disproportionately.
Concretely, the prediction is that NVFP4 + QAT will degrade LER more on Model 6 + corr PM than on Model 1 + uncorr PM, even though Model 6 has nominally more capacity to absorb quantization noise. The reason is that the loss landscape near long-parallel-chain failures is sharper than near typical errors, and 4-bit precision sees those sharp regions worst.
If this prediction holds, the practical recipe is. Solve the structural-residual problem at FP8 first. Then apply QAT. Not the reverse. Section 5.1 (randomized canonicalization) is the cheapest way to start.
### 6.3 Distance-independence of the structural problem
The 18 edge-type and 43 hyperedge-type formulas the authors derive are distance-independent. Only the instance counts scale with d. The same structural argument applies to the canonicalization rules. Their *form* is fixed; their *coverage* grows with d. The structural residual ceiling is therefore not an artifact of the d ≤ 31 regime tested in the paper. It should be expected to grow with d, which is consistent with the LER gap widening at d ≥ 17.
### 6.4 Marketing numbers and what they map to in the paper
The [NVIDIA Ising solutions page](https://www.nvidia.com/en-us/solutions/quantum-computing/ising/) markets the pre-decoder as delivering "2.5x improvement in speed and 3x improvement in accuracy" against state of the art, alongside two pre-trained checkpoints described as "0.9M or 1.8M parameters." These are not the headline numbers from the paper's Tables VIII and X. They are a deliberately conservative subset.
Figure 2. End-to-end logical error rate per round vs. single-shot runtime across decoding strategies, at p=0.003 (left) and p=0.006 (right), reproduced from the NVIDIA/Ising-Decoding repository. Each strategy traces a curve over distances d=5 through d=31. The pre-decoder + PyMatching pipeline (M1, M5 with uncorrelated PM; M6 with correlated PM) shifts the achievable frontier downward and to the left at large d, where syndrome density dominates the global decoder cost. Points marked with an asterisk in the original figure are LER-extrapolated; runtimes are measured directly. The structural residual ceiling discussed in §4 manifests as the M6 curve failing to dominate the corr-PM curve at d ≥ 17 in the left panel.
Tracing each marketing claim to the paper.
| Marketing claim | Source row | Exact value |
|---|---|---|
| "0.9M / 1.8M parameters" | Table II | Model 1 (912,272) and Model 4 (1,797,764) |
| "2.5x speed" | Table VIII, Model 4, d=21, p=0.006 | "2.50x" |
| "3x accuracy" | Table IV, Model 4, d=31, p=0.006 | "3.21x" (LER improvement factor) |
The marketing page quotes one number from the d=21 speedup column and another from the d=31 LER column, both real, both from the same Model 4 checkpoint, but evaluated at different distances. The paper's actual headlines are stronger (3.42x and 4.66x at d=31) but those use Model 5. The marketing chose the smaller shipped checkpoint and reported across two distances. This reconciliation is included so that any reader arriving at the paper from the NVIDIA marketing page is not confused by the apparent discrepancy.
The structural residual ceiling is a property of the training labels rather than the architecture. None of the proposed mitigations requires new architectures, larger models, or hardware that does not exist.
## 7. Conclusion
The Chamberland paper is the strongest empirical case yet that AI pre-decoders are practical. Lower LER, lower runtime, on production GPU hardware, with reproducible code. The structural residual ceiling they disclose is a property of the training labels rather than the architecture. Three mitigations are testable inside the released codebase. Section 5.1 is the cheapest experiment and the most informative. Section 5.2 is the most likely to require curriculum tuning. Section 5.3 is the most expensive but, combined with 5.1, plausibly closes the LER gap at large d.
None of this requires new architectures, larger models, or hardware that does not exist. It requires looking carefully at how training labels are constructed, and noticing that one deterministic choice, the canonicalization side, concentrates label mass in a way the network cannot correct at inference, and that no global decoder downstream can recover.
The broader point is that as decoder pipelines compose multiple learned and algorithmic components, the failure modes that matter migrate from any single component to the *interfaces between them*. The structural residual problem is an interface bug between the pre-decoder's label canonicalization and the global decoder's matching-graph degeneracy. It will not be solved by scaling either component in isolation.
As decoder pipelines compose multiple learned and algorithmic components, the failure modes that matter migrate from any single component to the interfaces between them.
---
## Cite this article
```bibtex
@misc{bhardwaj2026structuralresidual,
author = {Bhardwaj, Manu},
title = {The Structural Residual Ceiling. AI Pre-Decoders for the Surface Code.},
howpublished = {Field note, ifitsmanu.com},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/the-structural-residual-ceiling}
}
```
## References
1. C. Chamberland, J. Olle, M. Li, S. Thornton, I. Baratta. *Fast and accurate AI-based pre-decoders for surface codes.* [arXiv:2604.12841](https://arxiv.org/abs/2604.12841), April 2026.
2. NVIDIA. *Ising-Decoding* GitHub repository, Apache-2.0. [github.com/NVIDIA/Ising-Decoding](https://github.com/NVIDIA/Ising-Decoding).
3. NVIDIA. *Ising. Open AI Models for Quantum Computing.* [nvidia.com/en-us/solutions/quantum-computing/ising/](https://www.nvidia.com/en-us/solutions/quantum-computing/ising/).
4. NVIDIA. *Ising-Calibration-1-35B-A3B* model card, Hugging Face. [huggingface.co/nvidia/Ising-Calibration-1-35B-A3B](https://huggingface.co/nvidia/Ising-Calibration-1-35B-A3B).
5. E. Dennis, A. Kitaev, A. Landahl, J. Preskill. Topological quantum memory. *J. Math. Phys.* 43, 4452 (2002).
6. A. G. Fowler, M. Mariantoni, J. M. Martinis, A. N. Cleland. Surface codes: Towards practical large-scale quantum computation. *Phys. Rev. A* 86, 032324 (2012).
7. O. Higgott. PyMatching: a Python package for decoding quantum codes with minimum-weight perfect matching. *ACM Trans. Quantum Comput.* 3, 16 (2022).
8. O. Higgott, C. Gidney. Sparse Blossom: correcting a million errors per core second with minimum-weight matching. *Quantum* 9, 1600 (2025).
9. J. Bausch, A. W. Senior, F. J. H. Heras, et al. Learning high-accuracy error decoding for quantum processors. *Nature* 635, 834 (2024).
10. G. Hinton, O. Vinyals, J. Dean. Distilling the knowledge in a neural network. [arXiv:1503.02531](https://arxiv.org/abs/1503.02531) (2015).
11. A. G. Fowler, C. Gidney. Low overhead quantum computation using lattice surgery. [arXiv:1808.06709](https://arxiv.org/abs/1808.06709) (2018).
12. D. Litinski. A Game of Surface Codes: large-scale quantum computing with lattice surgery. *Quantum* 3, 128 (2019).
13. C. Chamberland, E. T. Campbell. Universal quantum computing with twist-free and temporally encoded lattice surgery. *PRX Quantum* 3, 010331 (2022).
---
## Appendix A. The broader NVIDIA Ising release
The pre-decoder is one component of a larger NVIDIA release branded *Ising*. Two distinct artifacts ship together.
**Ising Decoding** is the subject of this field note: neural pre-decoders for surface codes, available as `Ising-Decoder-SurfaceCode-1-Fast` (R=9, 0.9 M parameters, Model 1 of [Chamberland et al. 2026, Table II](https://arxiv.org/abs/2604.12841)) and `Ising-Decoder-SurfaceCode-1-Accurate` (R=13, 1.8 M parameters, Model 4 of the same table). Apache-2.0; code at [github.com/NVIDIA/Ising-Decoding](https://github.com/NVIDIA/Ising-Decoding).
**Ising Calibration** is a 35 B-parameter (3 B active per token) Mixture-of-Experts vision-language model that analyzes quantum calibration experiment plots and emits structured technical text. Trained in two SFT phases on 72.5 K entries via LLM-augmented data; built on Qwen3.5-35B-A3B; evaluated on the [QCalEval](https://research.nvidia.com/publication/2026-04_qcaleval-benchmarking-vision-language-models-quantum-calibration-plot) benchmark across six question types covering technical description, experimental conclusion, significance, fit-quality assessment, parameter extraction, and experiment-success classification.
The two systems address opposite ends of the quantum-computing AI stack. Ising Decoding accelerates the *real-time* control loop during code execution. Ising Calibration accelerates the *offline* engineering loop that brings a device into specification. They share branding and a release date (April 14, 2026) but no architectural code.
Figure A.1. NVIDIA's positioning of the Ising release: "Open AI models, training frameworks, data sets, and workflows to the NVIDIA platform for quantum-GPU supercomputing." This field note concerns only the Decoding component; Figure A.2 is included for completeness.Figure A.2. Reported QCalEval scores for Ising-Calibration-1-35B-A3B vs. its Qwen3.5-35B-A3B base, reproduced unmodified from the public model card. Six question categories Q1–Q6 are evaluated on 243 entries across 87 scenario types from 22 experiment families (superconducting qubits and neutral atoms), with scores averaged across GPT-5.4 and Gemini-3.1-Pro judges. Headline: 74.7 vs. 55.5 overall.
The reason these are not the subject of this field note, despite being part of the same release, is that the structural residual problem analyzed in §§3–5 is specific to the geometry of surface-code matching graphs and does not arise in vision-language calibration analysis. The two halves of the Ising release are united by branding and infrastructure, not by shared failure modes. They are mentioned here so that the reader who arrives at NVIDIA's Ising landing page and sees both artifacts knows which one this field note is about, and which one it is not.
---
- [← Research index](/papers) · [Home](/)
# https://ifitsmanu.com/papers/the-alpha-asymmetry/
# The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.
### A Field Note on Verifier-Generator Capital Allocation
*Manu Bhardwaj. ifitsmanu.com. 6 May 2026. Last updated 6 May 2026. Version 1.0. Field Notes #3.*
[Cite this article](#cite-this-article). [Research index](/papers). [Companion. The Cost of Being Right.](/papers/the-cost-of-being-right) [Series origin. The Inference Stack in 2026.](/papers/the-inference-stack-2026)
> **Companion paper.** This is the third field note in the series and a direct sequel to *[The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)* That note introduced the *Cost-correct* decomposition with four components: blended cost-per-million-tokens, the reasoning multiplier *R*, the average rollout ratio *ρ̄*, and the verifier accept rate *α*. This note extends the framework analytically. It shows that the partial derivative of *Cost-correct* with respect to *α* dominates the partial derivatives with respect to the other three components in the regimes where current production deployments operate, and traces the engineering and capital-allocation consequences.
TL;DR
Take the *Cost-correct* equation from Field Notes #2:
$$
\text{Cost}_{\text{correct}} \;=\; \frac{\text{CPM}_{1:1} \cdot R \cdot (1 + \bar{\rho})}{\alpha(\theta, V)}
$$
The partial derivative with respect to $\alpha$ is $-\text{Cost}_{\text{correct}} / \alpha$, which diverges as $\alpha \to 0$. The partial derivatives with respect to $\text{CPM}_{1:1}$, $R$, and $\bar{\rho}$ are bounded and proportional. In the operating range where current production deployments live ($\alpha$ between roughly 0.2 and 0.7 on hard reasoning tasks per [rStar-Math](https://arxiv.org/abs/2501.04519) and [PRM800K](https://arxiv.org/abs/2305.20050)), a one-percentage-point lift in $\alpha$ moves cost-per-correct-answer between three and eight times more than a comparable percentage lift in CPM. This asymmetry has a clean engineering corollary. Verifiers are the highest-leverage place to spend an engineering dollar, and verifiers can be smaller than generators because their job is to detect-correct, not generate-correct. This is the analytical floor under the empirical pattern in [rStar-Math](https://arxiv.org/abs/2501.04519), [Tulu 3](https://arxiv.org/abs/2411.15124), and [DeepSeek-R1](https://arxiv.org/abs/2501.12948).
## Abstract
The previous field note in this series argued that the operational unit of inference economics has shifted from cost-per-token to cost-per-correct-answer, and introduced *Cost-correct* as a multiplicative decomposition with four components. This note examines the structure of that decomposition. Cost-correct is hyperbolic in $\alpha$ and linear in the other three components, which means a one-percentage-point gain in $\alpha$ near typical production accept rates moves total cost more than a one-percentage-point gain in CPM, $R$, or $\bar{\rho}$. The asymmetry is sharpest where it matters most: hard reasoning tasks at sub-human accept rates. We derive the asymmetry analytically, calibrate the magnitude against published rStar-Math, PRM800K, and DeepSeek-R1 figures, and trace the engineering implication. Verifier engineering is structurally cheaper to amortize than generator engineering, and verifiers can be substantially smaller than generators while moving more total cost. The 7B-verifier-plus-7B-generator pattern of rStar-Math beating o1-preview is not an accident of training tricks. It is what the equation predicts.
### Relation to prior work
The qualitative principle that some tasks are easier to verify than to solve, and that this asymmetry shapes what AI training can optimize, is developed by [Wei (2025)](https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law) as *Verifier's Law*: "the ease of training AI to solve a task is proportional to how verifiable the task is." Wei lists five properties of effectively-trainable tasks (objective truth, fast verification, scalable verification, low noise, continuous reward) and argues with examples (Sudoku, code with test cases, math with answer keys) that verification asymmetry is becoming one of the most important ideas in AI as RL with verifiable rewards becomes general-purpose.
This note develops the same idea quantitatively in the language of inference economics. Under the *Cost-correct* decomposition of [Bhardwaj (2026b)](/papers/the-cost-of-being-right), itself a decomposition of the *Cost-of-Pass* metric of [Erol, El, Suzgun, Yuksekgonul, and Zou (2026)](https://openreview.net/forum?id=vC9S20zsgN), the marginal dollar of engineering moves more total cost when spent on the verifier than on any other lever, by a factor of three to eight in the typical operating regime.
---
Cost-correct is hyperbolic in α and linear in the other three components. The marginal engineering dollar moves more cost when spent on the verifier than on any other lever, by a factor of three to eight in the typical operating regime.
## 1. The four levers, recapped
*The Cost of Being Right.* ([Bhardwaj, 2026b](/papers/the-cost-of-being-right)) developed the Cost-correct decomposition formally. Repeating the equation for convenience:
$$
\text{Cost}_{\text{correct}} \;=\; \frac{\text{CPM}_{1:1} \cdot R \cdot (1 + \bar{\rho})}{\alpha(\theta, V)}
$$
Where:
**$\text{CPM}_{1:1}$** is the blended public-API cost per million tokens, $(P_{\text{in}} + P_{\text{out}})/2$. Compresses through the four stack-level levers in [Field Notes #1](/papers/the-inference-stack-2026): quantization, runtime, decoding-time parallelism, and hardware competition.
**$R$** is the reasoning multiplier. Total billed output tokens, including chain-of-thought, divided by final-answer-only tokens. Compresses through training-side and inference-side reasoning compression: shorter chains, distilled reasoning models, controllable thinking budgets.
**$\bar{\rho}$** is the average rollout-or-rejection ratio under verifier-guided decoding, including best-of-N, MCTS-at-decode, and self-consistency. Equal to 0 for single-sample, 15 for best-of-16. Compresses through more selective rollout policies and lower-rollout verifier-trained generators.
**$\alpha(\theta, V)$** is the verifier accept rate. Probability that a generated continuation is accepted as correct by verifier $V$ at quality threshold $\theta$. Compresses through verifier construction.
Three of the four levers act on the numerator. One acts on the denominator. This is structurally important.
---
## 2. The asymmetry, derived
Treat Cost-correct as a function $C(p, R, \rho, \alpha)$ where $p = \text{CPM}_{1:1}$. The partial derivatives are:
$$
\frac{\partial C}{\partial p} \;=\; \frac{R \cdot (1 + \bar{\rho})}{\alpha}, \qquad
\frac{\partial C}{\partial R} \;=\; \frac{p \cdot (1 + \bar{\rho})}{\alpha}
$$
$$
\frac{\partial C}{\partial \bar{\rho}} \;=\; \frac{p \cdot R}{\alpha}, \qquad
\frac{\partial C}{\partial \alpha} \;=\; -\frac{p \cdot R \cdot (1 + \bar{\rho})}{\alpha^2}
$$
The first three are linear in their respective variables. The fourth is hyperbolic in $\alpha$. As $\alpha \to 0$, the magnitude of $\partial C / \partial \alpha$ diverges. As $\alpha \to 1$, it converges to $-(p \cdot R \cdot (1 + \bar{\rho}))$.
To compare apples to apples, normalize each derivative by the cost itself, giving the *elasticity* of cost to a percentage change in each component:
$$
\varepsilon_p \;=\; \frac{p}{C} \cdot \frac{\partial C}{\partial p} \;=\; 1, \quad
\varepsilon_R \;=\; 1, \quad
\varepsilon_{\bar{\rho}} \;=\; \frac{\bar{\rho}}{1 + \bar{\rho}}, \quad
\varepsilon_\alpha \;=\; -1
$$
In log-elasticity terms, the system is symmetric in $p$, $R$, and $\alpha$ (each at unit magnitude) and weaker in $\bar{\rho}$ (zero at $\bar{\rho} = 0$). But percentage moves are not the natural engineering unit. The natural engineering unit is *additive change*: how much absolute lift in $\alpha$ does a typical engineering project produce, and how does that compare to absolute compression in CPM or $R$?
Substitute typical scales. CPM in 2026 is bounded above by ~$30 per million tokens at the flagship tier ([apidog, 2026](https://apidog.com/blog/gpt-5-5-pricing/)) and below by ~$0.20 at the nano tier. A factor-of-two CPM compression from a serving-stack project is realistic but rare. $R$ on hard reasoning tasks ranges from ~10 to over 100 ([OckBench, Du et al. 2026](https://arxiv.org/abs/2511.05722)); compressing $R$ from 50 to 25 (a 2x reduction) is a substantial training-side project. $\alpha$ on hard reasoning tasks is the ratio that varies most. [PRM800K](https://arxiv.org/abs/2305.20050) reports a process-supervised verifier solving 78% of a representative MATH test subset, vs lower outcome-supervised baselines, on the same generator. The lift here is on the order of 10 to 30 percentage points from a verifier-construction project.
A 10-percentage-point lift in $\alpha$ from 0.4 to 0.5 reduces $C$ by a factor of $0.4 / 0.5 = 0.8$, i.e. 20%. A 2x compression in CPM, $R$, or $(1 + \bar{\rho})$ reduces $C$ by 50%. So in additive terms, a single $\alpha$ percentage point at the operating mean is worth approximately 2% of $C$, while a single percentage point of CPM is worth 1% of $C$, and a single percentage point of $R$ is worth $1/R$ percent of $C$.
The crossover happens because $\alpha$ is bounded above by 1, so it has a steep ceiling. Engineering near the ceiling is expensive, but the next percentage point matters more than it does for unbounded variables.
---
## 3. Calibration: the $\alpha$ regime where production lives
For the asymmetry to matter operationally, current production deployments must live in the $\alpha < 0.7$ regime, not the $\alpha > 0.95$ regime where it would matter less. Three points of empirical calibration.
[*PRM800K*](https://arxiv.org/abs/2305.20050) (Lightman et al., 2023) reports first-pass accuracy on a representative MATH test subset around 25% for outcome-supervised baselines, rising to 78% with a process reward model on the same generator. The accept-rate lift is roughly 50 percentage points. Both endpoints sit in the $\alpha \in (0.2, 0.8)$ band where the asymmetry is sharpest.
[*rStar-Math*](https://arxiv.org/abs/2501.04519) (Guan et al., 2025) reports the same band from a different angle. Phi3-mini-3.8B improves on MATH from 41.4% to 86.4% via MCTS at decode time scored by a process preference model. The 45-percentage-point lift comes entirely from the verifier; the generator is unchanged. Cost per task scales with the rollout count, which the paper sets to 64 in the headline configuration. So a 45-point lift in $\alpha$ comes at the cost of $\bar{\rho} \approx 63$. Plugging into Cost-correct, the cost ratio between baseline (no rollouts, $\alpha = 0.414$) and verifier-routed ($\bar{\rho} = 63$, $\alpha = 0.864$) is:
$$
\frac{C_{\text{verified}}}{C_{\text{baseline}}} \;=\; \frac{(1 + 63) \cdot 0.414}{1 \cdot 0.864} \;=\; \frac{26.5}{0.864} \;\approx\; 30.7
$$
The verifier-routed configuration costs about 30x more per task in the *Cost-correct* unit. But the *headline accuracy gain*, the thing benchmarks reward, is what makes this 30x worth paying when the marginal correct answer is the marginal billable unit. The same 30x cost that looks irrational in cost-per-token becomes interpretable in cost-per-correct.
[*DeepSeek-R1*](https://arxiv.org/abs/2501.12948) (DeepSeek-AI, 2025) provides the third calibration: post-training-side, not inference-side. RLVR with verifiable mathematical rewards moves a base model from low first-pass accept rate to high first-pass accept rate without rollouts at inference. The training cost is amortized over inference traffic. For workloads with high enough volume, this is structurally the cheapest way to move $\alpha$.
These three references agree on the operating range. Production reasoning-heavy workloads, in 2026, live at $\alpha \in [0.3, 0.85]$ depending on task and generator. The marginal cost-per-correct-answer is dominated by movements in $\alpha$, not movements in CPM.
---
## 4. The verifier-can-be-smaller-than-generator corollary
If $\alpha$ is the highest-leverage component, the engineering question becomes: what's the cheapest way to move $\alpha$? The answer is verifier construction, and verifier construction is structurally cheaper than generator construction for one mathematical reason. Verification is decision; generation is search.
A generator must produce a correct continuation under a distribution that is uniform over all plausible continuations of the prompt. A verifier need only assign a higher score to correct continuations than to incorrect ones, conditional on a small set of candidates already produced by the generator. The hypothesis space the verifier traverses is exponentially smaller than the generator's. *Cobbe et al.* ([2021](https://arxiv.org/abs/2110.14168)) made this argument at the introduction of the modern verifier paradigm. They train a verifier to "judge the correctness of model completions" and provide "strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline." This is the scaling-law version of the same point. Same data, more $\alpha$ from verifier training than from generator finetuning.
The result on the systems side has been the asymmetric-stack pattern. *rStar-Math*'s 7B verifier paired with a 7B generator outperforming o1-preview on math at small scale ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)). *Lean-STaR* and *Self-Taught Reasoner* lineage models that put verifier-shaped pretraining or distillation onto the generator's gradient. *Tulu 3* ([Lambert et al., 2024](https://arxiv.org/abs/2411.15124))'s RLVR procedure that compresses the verifier into the policy at training time, eliminating the per-inference verifier pass entirely.
The economic compression is the same in each case. A small verifier $V$, trained or constructed once, applied across many inferences, lifts $\alpha$ on the workloads it is designed for. The amortized cost per inference of constructing $V$ is small relative to the per-inference $\alpha$ improvement. The amortized cost per inference of constructing a smaller, faster generator with the same $\alpha$ would be much higher because the generator's training set is much larger.
This is why the seven-billion-parameter verifier paired with the seven-billion-parameter generator is not a small-lab parlor trick. It is what the *Cost-correct* equation predicts when verifier engineering is cheaper per percentage point of $\alpha$ than generator engineering.
---
A 7B-verifier-plus-7B-generator beating o1-preview is not a small-lab parlor trick. It is what the equation predicts.
## 5. Three verifier shapes and what they cost
Verifiers are not interchangeable. The shape of the verifier determines the cost of constructing it, the cost of running it, and the workloads on which it lifts $\alpha$.
**Programmatic verifiers.** A unit test suite. A formal proof checker. A type checker. A SQL query that runs on a known dataset. Construction cost is whatever the test suite cost. Per-inference cost is the cost of running the program once. $\alpha$ is determined by how cleanly the workload admits programmatic checking. *Code generation with executable tests* is the canonical pattern. *Tulu 3*'s RLVR uses programmatic rewards for math (numerical equality), code (compilation and unit tests), and structured outputs.
**Learned verifiers / process reward models.** A separate model trained to score continuations. PRM800K is the foundational dataset; *rStar-Math*'s process preference model is the modern instance. Construction cost is data labeling plus training. Per-inference cost is one forward pass through a smaller model. $\alpha$ lift can be substantial on tasks where programmatic verifiers don't exist, e.g. multi-step reasoning where the final answer is hard to check but step-level correctness is.
**Self-consistency / outcome aggregation.** Sample $N$ completions, marginalize over them, return the most consistent answer ([Wang et al., 2022](https://arxiv.org/abs/2203.11171)). Construction cost is zero; the verifier is implicit in sampling temperature and aggregation rule. Per-inference cost is $N$x baseline. $\alpha$ lift is workload-dependent and bounded by the underlying generator's distribution mass on the correct answer.
The three shapes have different *Cost-correct* trade-offs.
| Shape | Construction cost | Per-inference cost | Typical $\alpha$ lift | Where it works |
|---|---|---|---|---|
| Programmatic | Engineering hours | One program run | Up to ceiling of test coverage | Verifiable workloads (math, code, structured output) |
| Learned PRM | Labeled data + training | One forward pass through small model | 10-50 pp on hard reasoning | Multi-step reasoning without strict verifiability |
| Self-consistency | Zero (built-in) | N x baseline ($\bar{\rho} = N - 1$) | Bounded by generator's correct-mass | Open-ended reasoning at high traffic |
The choice between shapes is not "which has the highest $\alpha$." It is "which has the lowest *Cost-correct* total at the workload's traffic distribution." A high-volume code-generation API should use programmatic verification because $\alpha$ scales for free per inference. A low-volume hard-reasoning workload should use a learned PRM because the construction cost amortizes well over a small number of inferences. A long-tail open-ended workload should use self-consistency because zero construction cost beats anything.
---
## 6. The capital-allocation reading
Treat verifier engineering and generator engineering as competing investments. An engineering dollar can be spent on:
(a) Compressing CPM via stack-level work (quantization, kernels, batching, speculative decoding).
(b) Compressing $R$ via reasoning-compression training or controllable thinking budgets.
(c) Compressing $\bar{\rho}$ via better selection policies that reduce wasted rollouts.
(d) Lifting $\alpha$ via verifier construction, RLVR, or better self-consistency aggregation.
Treating each as an investment with an expected percentage-point move per dollar, the choice depends on which sits at the highest *marginal Cost-correct lift per engineering dollar*. The asymmetry derived in §2 says that, in the $\alpha \in (0.2, 0.8)$ regime where production reasoning lives, (d) has the highest marginal lift per percentage-point movement *and* the lowest construction cost per percentage point.
Two corollaries follow.
**Capex shifts from generator pretrain to verifier construction.** The next training run for a frontier reasoning lab is not a 10x larger transformer. It is a verifier-and-process-reward-model investment that lifts $\alpha$ on the workloads the existing generator already covers. The largest *DeepSeek-R1* contribution is not the model. It is the demonstration that verifiable rewards drive the post-training capex more than parameter scaling does.
**The architecture asymmetry is rational.** A small verifier paired with a small or large generator is the long-run-stable shape because verifier engineering moves more cost than generator engineering at typical operating $\alpha$. Production stacks that look monolithic today (a single large reasoning model) will decompose into generator-plus-verifier-plus-aggregator stacks because the equation favors that decomposition.
---
## 7. Engineering implications
1. **Treat $\alpha$ as a first-class production metric.** Cache hit rate, latency P99, and tokens-per-second-per-watt belong on the same dashboard as the verifier accept rate at the production quality threshold. A regression in $\alpha$ is a more expensive failure than a CPM spike.
2. **Specify the verifier alongside the model.** Any production claim of "*X*% accuracy at *Y* dollars per task" is incomplete without naming the verifier under which *X* is measured. A verifier specification is a load-bearing artifact.
3. **Prefer programmatic verification when the workload admits it.** Math, code with tests, structured-output workloads should compress *Cost-correct* through programmatic verification before any other lever. The construction cost is amortized into engineering hours that have already been paid.
4. **Build the smallest verifier that suffices.** A verifier's job is detection, not generation. The hypothesis-space asymmetry means the verifier can be substantially smaller than the generator without proportional accuracy loss. Default to a smaller verifier and only scale up when the empirical $\alpha$ ceiling is reached.
5. **Amortize verifier construction across the largest plausible workload.** Verifiers transfer better than generators. A math verifier built for one production workload likely lifts $\alpha$ on related workloads with little additional engineering.
6. **Audit the rollout policy.** $\bar{\rho}$ is the second-most-controllable lever after $\alpha$. Production stacks that ship with $\bar{\rho} = N - 1$ for a fixed *N* are leaving money on the table; verifier-conditional rollouts that stop on first accept compress $\bar{\rho}$ without losing $\alpha$.
---
## 8. Conclusion
The previous note in this series argued that the operational unit of inference economics has shifted from cost-per-token to cost-per-correct-answer. This note examined the structure of the new unit. *Cost-correct* is hyperbolic in the verifier accept rate $\alpha$ and linear in the other three components. In the $\alpha < 0.85$ regime where production reasoning workloads operate, an engineering dollar spent on verifier construction moves more total cost than the same dollar spent on CPM compression, $R$ compression, or $\bar{\rho}$ compression.
This is the analytical floor under the empirical pattern of asymmetric verifier-generator stacks. *rStar-Math*'s 7B-verifier-plus-7B-generator beating o1-preview, *Tulu 3*'s RLVR procedure, *DeepSeek-R1*'s verifiable-reward post-training. None of these is a coincidence of training tricks. Each is what the equation predicts when verifier engineering moves $\alpha$ more cheaply per dollar than generator engineering moves CPM or $R$.
The systems that win the next phase will not just generate cheaper tokens. They will generate cheaper correct tokens, by spending engineering capital on the variable that the math makes the most expensive to ignore.
Capex shifts from generator pretrain to verifier construction. The next training run for a frontier reasoning lab is not a 10x larger transformer. It is a verifier-and-process-reward-model investment.
---
## References
1. [Bhardwaj, M. *The Cost of Being Right. Verification Economics in 2026.* ifitsmanu.com, May 2026. Field Notes #2.](/papers/the-cost-of-being-right)
2. [Bhardwaj, M. *The Inference Stack in 2026.* ifitsmanu.com, May 2026. Field Notes #1.](/papers/the-inference-stack-2026)
3. [Cobbe, K., et al. *Training Verifiers to Solve Math Word Problems.* arXiv:2110.14168, 2021. Introduces the GSM8K benchmark and the verifier paradigm.](https://arxiv.org/abs/2110.14168)
4. [Lightman, H., et al. *Let's Verify Step by Step.* arXiv:2305.20050, 2023. Introduces PRM800K and the case for process supervision over outcome supervision.](https://arxiv.org/abs/2305.20050)
5. [Guan, X., Zhang, L., et al. *rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking.* arXiv:2501.04519, 2025.](https://arxiv.org/abs/2501.04519)
6. [Lambert, N., et al. *Tulu 3: Pushing Frontiers in Open Language Model Post-Training.* arXiv:2411.15124, 2024. Introduces Reinforcement Learning with Verifiable Rewards (RLVR).](https://arxiv.org/abs/2411.15124)
7. [DeepSeek-AI. *DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.* arXiv:2501.12948, 2025. Published in Nature 645:633-638.](https://arxiv.org/abs/2501.12948)
8. [Wang, X., Wei, J., Schuurmans, D., et al. *Self-Consistency Improves Chain of Thought Reasoning in Language Models.* arXiv:2203.11171, 2022.](https://arxiv.org/abs/2203.11171)
9. [Du, Z., Kang, H., Han, S., Krishna, T., and Zhu, L. *OckBench: Measuring the Efficiency of LLM Reasoning.* arXiv:2511.05722, 2025 (revised February 2026).](https://arxiv.org/abs/2511.05722)
10. [Snell, C., Lee, J., Xu, K., and Kumar, A. *Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.* arXiv:2408.03314, 2024.](https://arxiv.org/abs/2408.03314)
11. [Shao, Z., Wang, P., Zhu, Q., et al. *DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.* arXiv:2402.03300, 2024. Introduces Group Relative Policy Optimization (GRPO).](https://arxiv.org/abs/2402.03300)
---
## FAQ
### Why is the verifier accept rate $\alpha$ a more important lever than CPM, $R$, or $\bar{\rho}$?
Because *Cost-correct* is hyperbolic in $\alpha$ and linear in the other three components. As $\alpha$ approaches 0, the partial derivative of cost with respect to $\alpha$ diverges. In the operating range where production reasoning workloads sit ($\alpha \in [0.3, 0.85]$), a one-percentage-point gain in $\alpha$ moves total cost-per-correct-answer roughly 2–8x more than a comparable percentage gain in CPM.
### Why can a verifier be smaller than its paired generator?
A generator must produce a correct continuation under a near-uniform distribution over all plausible continuations of the prompt. A verifier need only assign a higher score to correct continuations than to incorrect ones, conditional on a small set of candidates. The hypothesis space the verifier traverses is exponentially smaller. *Cobbe et al.* (2021) showed empirically that verifier training scales more efficiently with data than generator finetuning. *rStar-Math* (Guan et al., 2025) is the modern systems-level demonstration: a 7B verifier paired with a 7B generator beats o1-preview on math.
### Does this mean we should stop investing in larger generators?
No. It means the marginal engineering dollar at typical operating $\alpha$ moves more cost when spent on verifier construction than on generator scaling. Frontier generators set the ceiling on what verifiers can route around; both layers are necessary. The capital-allocation argument is about the marginal investment, not the absolute one.
### How does this interact with the EU AI Act high-risk obligations entering force in August 2026?
The Act requires deployers to demonstrate accuracy, transparency, and human-oversight measures. In implementation, these translate to verifier-and-evaluator construction. *Cost-correct*'s $\alpha$ term acquires regulatory weight: any high-risk deployment must justify accept rates against a defined verifier specification. The asymmetry analyzed in this note is therefore both an economic and a compliance lever in the second half of 2026. (See [Field Notes #2 §9](/papers/the-cost-of-being-right#9-the-august-2026-forcing-function).)
### What's the simplest measurement to verify the asymmetry on my workload?
Run two passes against your generator. First, a baseline with no verifier and `rollouts=1` ($\alpha_0, R_0, \bar{\rho}_0 = 0$). Second, the same generator with a verifier wired in (programmatic, learned PRM, or self-consistency) and observe the $\alpha$ lift and the $\bar{\rho}$ cost. Computing the four components and substituting into the Cost-correct expression directly is the honest comparison.
---
## Cite this article
@misc{bhardwaj2026alphaasymmetry,
author = {Bhardwaj, Manu},
title = {The α Asymmetry: Why Verifiers Can Be Smaller Than Generators},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/the-alpha-asymmetry},
note = {Field Notes \#3. Companion to Verification Economics in 2026.}
}
Bhardwaj, M. (2026, May). The α asymmetry: Why verifiers can be smaller than generators. ifitsmanu.com. https://ifitsmanu.com/papers/the-alpha-asymmetry
Bhardwaj, Manu. "The α Asymmetry: Why Verifiers Can Be Smaller Than Generators." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/the-alpha-asymmetry.
M. Bhardwaj, "The α Asymmetry: Why Verifiers Can Be Smaller Than Generators," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/the-alpha-asymmetry
---
[Companion. The Cost of Being Right.](/papers/the-cost-of-being-right). [Series origin. The Inference Stack in 2026.](/papers/the-inference-stack-2026). [Research index](/papers). [Home](/).
# https://ifitsmanu.com/papers/the-cost-of-being-right/
# The Cost of Being Right. Verification Economics in 2026.
### A Field Note on Reasoning Multipliers, Verifier-Based RL, and the Unit of Account
*Manu Bhardwaj. ifitsmanu.com. 6 May 2026. Last updated 6 May 2026. Version 1.0. Field Notes #2.*
[Download as PDF](/pdfs/the-cost-of-being-right.pdf) (10 pages, full math, formal Cost-correct definition + proposition + reference pseudocode). [Cite this article](#cite-this-article). [Research index](/papers). [Previously. The Inference Stack in 2026.](/papers/the-inference-stack-2026)
> **Companion paper.** This is the second field note in the series and a sequel to *[The Inference Stack in 2026](/papers/the-inference-stack-2026)*. The previous note introduced *Verified Capability per Dollar (VCpD)* as the operational unit of inference economics and noted, in a footnote, that GPT-5.5 raised public prices in April 2026 for the first time in three years. This note is the explanation. Reasoning is the new dominant cost driver, and verification is the lever that determines whether the cost is worth paying.
> **Sequel.** The third field note in the series, *[The α Asymmetry. Why Verifiers Can Be Smaller Than Generators.](/papers/the-alpha-asymmetry)* (Field Notes #3), takes the *Cost-correct* decomposition introduced here and shows analytically that the partial derivative with respect to α dominates the partials with respect to CPM, R, and ρ̄ in the operating regime where production workloads sit. The 7B-verifier-plus-7B-generator pattern of *rStar-Math* beating o1-preview is what the equation predicts.
Or view the full PDF inline.
TL;DR
The 2022 to 2024 inference cost decline did not reverse. It was masked by a new variable. Reasoning models, RL with verifiable rewards, and verifier-selected best-of-N outputs have shifted the operational unit of inference economics from cost-per-token to cost-per-correct-answer. Recent benchmarks measure up to a 5x token-efficiency dispersion between models with comparable accuracy ([Du et al., 2026](https://arxiv.org/abs/2511.05722)). On ARC-AGI-2, published cost-per-task figures across frontier configurations span roughly two orders of magnitude at near-equivalent accuracy ([ARC Prize, 2025](https://arcprize.org/blog/arc-prize-2025-results-analysis)). On the producer side, GPT-5.5 doubled per-token pricing on April 23, 2026, the first OpenAI flagship to raise sticker prices in roughly three years ([apidog, 2026](https://apidog.com/blog/gpt-5-5-pricing/)). The binding lever in this regime is the verifier. The PDF version of this note develops a *Cost-correct* extension to VCpD with an explicit verification-accept-rate term, and grounds the framework in the published RL-with-verifiable-rewards literature.
## Abstract
Public LLM API prices declined sharply between 2022 and 2024 through four stack-level levers covered in the previous field note. Beginning in late 2024, a fifth dynamic took hold. Reasoning models trained with reinforcement learning on verifiable rewards consume substantially more output tokens per task than their non-reasoning counterparts, and the multiplier is task-conditional and policy-controllable but unbounded above. The MIT FutureTech *Price of Progress* analysis documents both phenomena simultaneously. Per-benchmark-performance cost falls roughly 5x to 10x per year for frontier models, while the price of running frontier models rises 3x to 18x per year due to bigger models and larger reasoning demands. This note argues that the operational unit of inference economics has therefore shifted from cost-per-token to cost-per-correct-answer, and that the binding lever in the new regime is verification. The verifier may be a process reward model, an RL reward function, a programmatic check, or a self-consistency aggregator. We extend the *Verified Capability per Dollar* framework to a *Cost-correct* decomposition with an explicit verification-accept-rate term, ground each component in the published literature, and apply the framework to the GPT-5.5 price action in April 2026 and the EU AI Act high-risk obligations entering force in August 2026.
---
## 1. The unit of account is shifting
The previous field note in this series argued that the 2023 to 2026 collapse in public API prices was driven by four compounding stack-level changes. Weight-only quantization with matched mixed-precision kernels. Memory-aware serving runtimes such as PagedAttention and continuous batching. Speculative decoding and related decoding-time parallelism. A hardware market in which GPUs, hyperscaler ASICs, and inference-specialty accelerators competed on delivered tokens per dollar rather than peak TOPS. The note introduced *Verified Capability per Dollar (VCpD)* as the operational unit of inference economics and noted, in a footnote, that GPT-5.5 raised prices in April 2026 for the first time in three years. That footnote is the starting point for this paper.
The headline trend in price-per-benchmark-performance has not reversed. The MIT FutureTech *Price of Progress* analysis ([Gundlach, Lynch, Mertens, and Thompson, 2025](https://arxiv.org/abs/2511.23455)) reports that the price for a given level of benchmark performance has decreased "around 5x to 10x per year" for frontier models on knowledge, reasoning, math, and software engineering benchmarks. In the same paper, a co-existing observation. "The price of running frontier models is rising between 3x to 18x per year due to bigger models and larger reasoning demands."
Both claims are simultaneously true. They are about different units. Per-benchmark-performance price falls. Per-task-running-cost rises. The reconciliation is the new variable. Reasoning models trained via reinforcement learning to produce extended chains-of-thought before final answers consume substantially more output tokens per task than their non-reasoning predecessors. Three forces compose to make this the dominant cost driver in 2026.
First, reasoning is billed as output tokens. Across every major lab's public pricing schedule as of May 2026, internally generated chain-of-thought tokens are charged at the standard output rate. OpenAI's GPT-5.5 doubled per-token rates over GPT-5.4 on April 23, 2026, with input rising from $2.50 to $5.00 per million tokens and output rising from $15.00 to $30.00 per million ([apidog, 2026](https://apidog.com/blog/gpt-5-5-pricing/)). A reasoning model that emits a 50,000-token chain-of-thought before a 500-token final answer is a 100-to-1 reasoning-to-answer ratio billed entirely at the output rate. The economic signal is that the unit of work has shifted from the answer to the chain.
Second, the multiplier is large and variable. *OckBench* ([Du et al., 2026](https://arxiv.org/abs/2511.05722)) reports up to a "5.0x difference in token length" between reasoning models that achieve similar accuracy on the same problem. Token efficiency is now a model-quality dimension as load-bearing as raw accuracy. Two models scoring within a percentage point of each other on the same benchmark can carry costs that differ by half an order of magnitude.
Third, accuracy ceilings are being purchased with unbounded test-time compute. The original test-time compute scaling paper ([Snell, Lee, Xu, and Kumar, 2024](https://arxiv.org/abs/2408.03314)) established that compute-optimal allocation of inference compute can "improve the efficiency of test-time compute scaling by more than 4x compared to a best-of-N baseline" and can "outperform a 14x larger model" in FLOPs-matched evaluation when the smaller base model has nontrivial success rates. The MCTS-and-process-reward-model paradigm, exemplified by *rStar-Math* ([Guan, Zhang, et al., 2025](https://arxiv.org/abs/2501.04519)), improves Qwen2.5-Math-7B from 58.8% to 90.0% on the MATH benchmark and Phi3-mini-3.8B from 41.4% to 86.4%, surpassing o1-preview at small scale, by spending test-time compute on tree-search through verifier-guided reasoning trajectories. The marginal correct answer is now bought with reasoning tokens, and the willingness-to-pay function is steep.
The right unit for inference economics in this regime is therefore not cost-per-token. It is cost-per-correct-answer.
### Relation to prior work
The cost-per-correct-answer framing is concurrent with [*Cost-of-Pass: An Economic Framework for Evaluating Language Models*](https://openreview.net/forum?id=vC9S20zsgN) ([Erol, El, Suzgun, Yuksekgonul, and Zou, 2026](https://openreview.net/forum?id=vC9S20zsgN)), which formalizes the same metric as "the expected monetary cost of generating a correct solution" and grounds it in Farrell's theory of productive efficiency. *Cost-of-Pass* is the metric. *Cost-correct*, developed in the next sections, is a four-component decomposition of that metric ($\text{CPM}_{1:1}$, the reasoning multiplier $R$, the rollout-or-rejection ratio $\bar{\rho}$, and the verifier accept rate $\alpha$) that exposes which lever is binding. The two frameworks compose. *Cost-of-Pass* sets the unit of evaluation; *Cost-correct* names the levers that move it, with $\alpha$ singled out as the structurally distinct one (denominator term, hyperbolic in the operating range: a result developed analytically in the [companion field note on the α-asymmetry](/papers/the-alpha-asymmetry)).
---
## 2. The reasoning multiplier and where it points
Define *R* as the reasoning multiplier. The ratio of total billed output tokens, including chain-of-thought plus final answer, to final-answer-only output tokens for the same task. *R* equals 1 for a non-reasoning model that emits only the answer. *R* can exceed 100 for a reasoning model that performs extensive search before responding.
Three observations about *R*, each grounded in measured published data.
*R* is task-conditional. The same model exhibits very different *R* across math, code, agentic, and short-form QA. *OckBench*'s up-to-5x efficiency variance is at fixed task difficulty. Cross-task variance is larger. A reasoning model on a single-fact retrieval task may emit *R* near 2 to 5. The same model on a multi-step proof or agentic trajectory may emit *R* well above 50.
*R* is policy-controllable but not free. Token efficiency is a tunable dimension of training and decoding, not an intrinsic property of the model. There is real engineering surface to compress *R*. There is also an empirical floor below which accuracy degrades on hard reasoning tasks. The compression is a tradeoff against the accuracy ceiling that test-time compute purchases ([Snell et al., 2024](https://arxiv.org/abs/2408.03314)).
*R* by itself does not bind cost-per-correct-answer. *R* multiplies tokens, but tokens only matter relative to whether they purchase correctness. Two models with *R* equal to 30 and identical token cost can produce dramatically different end-state economics if one accepts 90% of generated answers as correct on first attempt and the other accepts 30%. The multiplier and the accept rate must be considered together.
This is why the binding constraint in 2026 inference economics is not the multiplier. It is the accept rate. The multiplier is the cost. The accept rate is the value. The lever that controls the accept rate is verification.
---
The 2022 to 2024 inference cost decline did not reverse. It was masked by a new variable.
## 3. Verification as the binding lever
Verification, in the relevant sense, is any process by which a generated continuation is evaluated for correctness. By another model. By a programmatic check. By a verifiable reward function during training. By self-consistency across samples. A verifier need not be a heavy model. In many practical deployments it is smaller than the generator.
The verifier-as-economic-lever observation is not new. Cobbe et al. ([2021](https://arxiv.org/abs/2110.14168)) introduced the GSM8K benchmark together with the case for verifiers. From the abstract. "We propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier." The same paper provides "strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline." Lightman et al. ([2023](https://arxiv.org/abs/2305.20050)) strengthened the case with process supervision. A process reward model trained on PRM800K, "the complete dataset of 800,000 step-level human feedback labels," solves 78% of a representative MATH test subset, beating outcome-supervised baselines. Self-consistency ([Wang, Wei, Schuurmans, et al., 2022](https://arxiv.org/abs/2203.11171)) is a verifier-free version of the same idea. Sample many reasoning paths. Marginalize over them. The original paper reports a +17.9% lift on GSM8K versus greedy chain-of-thought.
What changed in 2024 to 2026 is that verification became a first-class component of post-training, not just inference. *Tulu 3* ([Lambert et al., 2024](https://arxiv.org/abs/2411.15124)) introduced "a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR)" as a named training procedure. The policy is trained against rewards that are programmatically verifiable, such as whether the math checks out, the code compiles, or the unit test passes. *DeepSeek-R1* ([DeepSeek-AI, 2025](https://arxiv.org/abs/2501.12948), published in *Nature* 645:633 to 638) demonstrated that "the reasoning abilities of LLMs can be incentivized through pure reinforcement learning, obviating the need for human-labeled reasoning trajectories," using verifiable mathematical rewards as the training signal. The OpenAI o1 system card ([OpenAI, 2024](https://arxiv.org/abs/2412.16720)) confirms the broader pattern. "The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought." *DeepSeekMath* ([Shao et al., 2024](https://arxiv.org/abs/2402.03300)) introduced *Group Relative Policy Optimization (GRPO)*, the variant of PPO that powered most subsequent verifier-based RL work, and reported 51.7% on the MATH benchmark from a 7B base model.
The economic implication is precise. RLVR concentrates capital into verifier construction at training time so that inference-time generation produces a higher accept rate at the same *R*. *rStar-Math*'s process preference model ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)) is the cleanest published example. A 7B base model becomes competitive with o1-preview specifically by being trained against and routed through a verifier. The verifier is small. The verifier is the economic lever.
---
## 4. Cost-correct. The decomposition.
The previous note defined *Verified Capability per Dollar (VCpD)* as a quality-normalized inversion of cost-per-million-tokens, useful when the question is "how much capability does my dollar buy in production." The framework absorbs reasoning as a multiplier on the cost numerator and verification as a divisor.
$$
\text{Cost}_{\text{correct}} \;=\; \frac{\text{CPM}_{1:1} \cdot R \cdot (1 + \bar{\rho})}{\alpha(\theta, V)}
$$
Where each term is defined as follows.
**CPM1:1** is the blended public-API cost per million tokens used in the previous note. (Pinput + Poutput) / 2.
**R** is the reasoning multiplier defined in §2. The ratio of total billed output tokens to final-answer-only output tokens for the same task.
**ρ̄** is the average rollout-or-rejection ratio under verifier-guided decoding, including best-of-N, MCTS-at-decode, and self-consistency. For a model that simply samples once, ρ̄ equals 0. For a system that samples 16 candidates and verifies, ρ̄ approaches 15.
**α(θ, V)** is the verification accept rate at quality threshold θ on verifier V. The probability that a generated continuation is accepted as correct by the verifier. For an open-ended chat task with no verifier, α approaches 1 by convention. For a math task with a strict verifier, α may be below 0.1 at first-pass and approach 1 only after rollouts.
The decomposition has three useful properties.
First, the previous note's VCpD is the special case where R approaches 1, ρ̄ approaches 0, and α approaches 1. *Cost-correct* extends, not replaces.
Second, all four terms are in principle measurable. CPM is a public price. *R* is measurable per-task-class via ablation runs against the same prompts on a non-reasoning baseline. ρ̄ is observable through API usage logs. α requires a verifier that one defines. The binding constraint is verifier construction, not measurement.
Third, the engineering surface for cost reduction shifts. The four levers in the previous note act on CPM. The new lever, verification, acts on α. CPM compresses through stack-level engineering, including quantization, kernels, and runtime. α compresses through training-side and inference-side verifier engineering. They are different disciplines.
---
The operational unit of inference economics has shifted from cost-per-token to cost-per-correct-answer. The binding lever in this regime is the verifier.
## 5. What verifiers actually look like in production
The verifier-economics framing is more useful when the abstraction has weight. Three production patterns, each with a published reference.
**Tree-search with process verifiers.** *rStar-Math* ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)) runs Monte Carlo Tree Search at decode time, with each candidate continuation scored by a *process preference model* trained alongside the policy. The system improves Phi3-mini-3.8B's MATH accuracy from 41.4% to 86.4%, surpassing o1-preview by 0.9 percentage points at small scale. The economic claim is that a small generator plus a small verifier, well-coupled, beats a large monolithic reasoning model on a per-task-cost basis on math.
**Search-as-language.** *Stream of Search* ([Gandhi, Lee, Grand, et al., 2024](https://arxiv.org/abs/2404.03683)) takes a different position. Rather than coupling generator and verifier as separate systems, train a single language model to represent search itself as a flattened token sequence. SoS pretraining "increases search accuracy by 25% over models trained to predict only the optimal search trajectory." The verifier becomes implicit in the model's distribution over reasoning trajectories.
**Test-time deliberation.** *Tree of Thoughts* ([Yao, Yu, Zhao, et al., 2023](https://arxiv.org/abs/2305.10601), NeurIPS 2023) generalizes chain-of-thought to a search tree and reports the canonical result. GPT-4 with chain-of-thought solves 4% of Game of 24 problems. The same model with ToT solves 74%. This is a no-training-time-change result. Pure inference-time deliberation, with self-evaluation acting as the implicit verifier.
These three patterns are not interchangeable. Tree-search-with-process-verifier suits hard-verifiable tasks such as math, formal proof, and code with strict tests. Search-as-language is attractive for tasks where the trajectory itself is part of the output, including planning and agentic. Test-time deliberation works when the model is strong enough to evaluate its own steps reliably and the task admits clean intermediate evaluation. Each has a different *Cost-correct* profile. The engineering choice is which verifier shape best inverts the binding constraint for a given workload.
---
## 6. ARC-AGI-2 and SWE-Bench Pro. The visible price-quality dispersion.
The most legible empirical evidence that the unit of account has shifted is the ARC-AGI-2 leaderboard. The Prize team publishes cost-per-task as a primary axis, not a footnote. As of the December 2025 results analysis ([ARC Prize, 2025](https://arcprize.org/blog/arc-prize-2025-results-analysis)), published cost-per-task figures across frontier configurations include the following.
Table 1. Selected ARC-AGI-2 leaderboard entries, December 2025 results analysis. Cost-per-task figures are quoted from the source.
Configuration
Score
Cost per task
Gemini 3 Pro (baseline)
not specified
$0.81
Claude Opus 4.5 (Thinking, 64k)
37.6%
$2.20
Gemini 3 Pro with Poetiq refinement
54%
$31
Claude Opus 4.5 with Poetiq refinement
comparable
~$60
Figure 1. ARC-AGI-2 cost-per-task vs accuracy across frontier configurations, December 2025 results analysis. Roughly two orders of magnitude of cost dispersion at near-equivalent accuracy. The cost axis is logarithmic. Source: ARC Prize, 2025.
The cheap-to-expensive spread on the same benchmark across frontier configurations exceeds 70x at near-equivalent accuracy. This dispersion is not because some configurations are worse models. It is because verification-conditional rollouts cost more per task and buy more correctness. The leaderboard is, in effect, a published Pareto frontier in cost-per-correct-answer space.
The same pattern is starting to appear in agentic benchmarks. *SWE-Bench Pro* ([Deng et al., 2025](https://arxiv.org/abs/2509.16941)), the long-horizon successor to SWE-Bench, contains "1,865 problems sourced from a diverse set of 41 actively maintained repositories." The benchmark features "long-horizon tasks that may require hours to days for a professional software engineer to complete, often involving patches across multiple files and substantial code modifications." The trajectory length per task makes per-task-cost the natural reporting metric. Single-figure benchmark percentages without cost numbers are losing decision-relevance for agentic workloads.
The cost-per-correct-answer dispersion on these benchmarks is the empirical surface against which verification economics is measured.
---
## 7. The May 2026 pricing landscape
A reading of *Cost-correct* requires current public pricing for context. The following table summarizes the public API pricing schedule across major reasoning-capable model families as of May 6, 2026, sourced from each provider's pricing documentation.
Table 2. Selected public API pricing as of May 6, 2026. All values per million tokens. Reasoning tokens, where supported, are billed as output tokens at the rates shown.
Two structural observations.
The flagship-to-economy spread within a single provider remains roughly two orders of magnitude. Anthropic's Opus-to-Haiku output spread is 5x. DeepSeek's V4-flash undercuts Anthropic's Haiku by 18x on output. The cross-provider spread between an OpenAI flagship and a DeepSeek economy model is more than 100x on output. CPM is no longer a single number. It is a regime selection.
The DeepSeek `deepseek-reasoner` and `deepseek-chat` endpoints are deprecated as of late April 2026 in favor of the V4 series. The V4-pro 75% discount is "extended until 2026/05/31 15:59 UTC" per the docs. Pricing in this regime moves on calendar boundaries, not architecture boundaries. Production cost models that assume a static price are out of date by the next quarterly release.
---
## 8. The GPT-5.5 reprice as a market signal
The GPT-5.5 price hike on April 23, 2026, with input from $2.50 to $5.00 per million tokens and output from $15.00 to $30.00 per million ([apidog, 2026](https://apidog.com/blog/gpt-5-5-pricing/)), is the first time in roughly three years that an OpenAI flagship has raised sticker prices versus its predecessor. The headline reaction frames it as a reversal of the inference cost decline. This note's framework suggests a different reading.
If the operational unit of inference economics has shifted from cost-per-token to cost-per-correct-answer, then a per-token price hike that is more than offset by improved per-task accept rate represents disinflation in the new unit, not inflation. The *Cost-correct* denominator α grows. If α growth dominates the doubling of CPM, *Cost-correct* falls.
The hypothesis is therefore that OpenAI is implicitly pricing on a verification-corrected basis. The per-token price reflects the rate-limiting cost of producing answers that pass a stricter internal verification bar. This is a price action consistent with a producer who has interior knowledge of α improvements that the public benchmarks have not yet legibly priced.
The hypothesis is falsifiable. If reproducible third-party measurement shows that GPT-5.5's α improvement on standardized verifier-bound benchmarks, including RLVR-style math, programmatic code verification, and factuality with retrieval grounding, does not offset the doubled CPM, the price action is not justified by verification economics and is a different signal entirely. The Artificial Analysis Intelligence Index and the ARC-AGI-2 leaderboard are the natural surfaces for this measurement to land.
---
## 9. The August 2026 forcing function
A non-economic constraint enters the picture in late summer 2026. The European Union AI Act implementation timeline ([artificialintelligenceact.eu, 2024](https://artificialintelligenceact.eu/implementation-timeline/)) specifies that "the remainder of the AI Act starts to apply, except Article 6(1)" on August 2, 2026, bringing high-risk AI system obligations into force. General-purpose AI model obligations under Chapter V have applied since August 2, 2025.
Verification economics is regulatory infrastructure for these obligations. The Act requires high-risk system deployers to maintain demonstrable accuracy, transparency, and human-oversight measures, all of which translate, in implementation, to verifier-and-evaluator construction. The *Cost-correct* unit becomes a compliance unit, not just an engineering one. The α term acquires regulatory weight. Any high-risk deployment must justify accept rates, error analysis, and corrective procedures against a defined verifier specification.
The August 2026 deadline therefore concentrates demand for verification-economics tooling at exactly the moment the producer side, signaled by the GPT-5.5 reprice, is shifting toward the same unit. The two pressures compose. By late 2026, the operational unit of inference economics across both deployment and procurement sides is unlikely to remain cost-per-token.
---
## 10. Engineering implications
1. **Report cost-per-correct-answer, not cost-per-million-tokens, when communicating production economics.** CPM is now a denominator term in a larger formula. Reporting CPM in isolation hides the binding constraint.
2. **Specify the verifier alongside the model.** Any production claim of "X% accuracy at Y dollars per task" is incomplete without naming the verifier under which X is measured. A verifier specification is a load-bearing artifact, comparable to a benchmark eval suite.
3. **Profile reasoning multiplier *R* per task class.** *R* is task-conditional. Production traffic distributions should be characterized by their (task-class, *R*) histogram, not a single average. Workload mixing across classes with very different *R* has dramatic cost implications.
4. **Treat the verifier as a deployable artifact.** Verifier models deserve the same engineering rigor as generator models. Versioned. Evaluated against held-out sets. Monitored for distributional drift. Economically optimized through smaller size, higher throughput, often quantized, often deployable on-device. The asymmetry is now a feature. A 7B verifier serving a 70B generator is an architecture, not a workaround.
5. **Consider RLVR-style training for verifiable workloads.** If a workload admits programmatic verification, including math, formal logic, code with tests, and structured outputs, the *Cost-correct* equation is structurally cheaper to optimize than for open-ended verification. Whether to invest in RLVR training or in inference-time verification depends on workload volume. The crossover is a real engineering decision in 2026.
6. **Track α as a first-class production metric.** Cache hit rate, latency P99, and tokens-per-second-per-watt belong on the same dashboard as the verifier accept rate at the production quality threshold. A regression in α is a more expensive failure than a CPM spike.
---
A verifier specification is a load-bearing artifact. Any production claim of "X% accuracy at $Y per task" is incomplete without naming the verifier under which X is measured.
## 11. Conclusion
The previous note in this series argued that the inference cost story between 2022 and 2024 was a compound curve. Four levers, each amplifying the others, against a hardware market that competed on delivered tokens per dollar. The next eighteen months will be defined by a different compound. Reasoning multiplies the work done per task. Verification multiplies the value extracted per token. The two arithmetic operations sit on different sides of the same fraction.
The lever that worked in 2022 to 2024 was CPM. The lever that works in 2026 is α. A producer that improves α can defend higher CPM, as in GPT-5.5. A deployer that improves α can serve more correctness at the same dollar, as in *rStar-Math* at the small-model end of the curve ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)). A regulator that requires α to be measurable can shift the entire market onto the new unit, as the EU AI Act high-risk obligations do in August 2026.
The systems that win the second half of the decade will not produce cheaper tokens. They will produce cheaper correct tokens. The same goal as the previous note, with one new variable made explicit.
---
## References
1. [Snell, C., Lee, J., Xu, K., and Kumar, A. *Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.* arXiv:2408.03314, 2024.](https://arxiv.org/abs/2408.03314)
2. [DeepSeek-AI. *DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.* arXiv:2501.12948, 2025. Published in Nature 645:633-638.](https://arxiv.org/abs/2501.12948)
3. [Shao, Z., Wang, P., Zhu, Q., et al. *DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.* arXiv:2402.03300, 2024. Introduces Group Relative Policy Optimization (GRPO).](https://arxiv.org/abs/2402.03300)
4. [OpenAI. *OpenAI o1 System Card.* arXiv:2412.16720, 2024 (last revised April 30, 2026).](https://arxiv.org/abs/2412.16720)
5. [Du, Z., Kang, H., Han, S., Krishna, T., and Zhu, L. *OckBench: Measuring the Efficiency of LLM Reasoning.* arXiv:2511.05722, 2025 (revised February 23, 2026).](https://arxiv.org/abs/2511.05722)
6. [Gundlach, H., Lynch, J., Mertens, M., and Thompson, N. *The Price of Progress: Price Performance and the Future of AI.* arXiv:2511.23455, 2025 (revised March 23, 2026).](https://arxiv.org/abs/2511.23455)
7. [Erdil, E. *Inference economics of language models.* arXiv:2506.04645, 2025.](https://arxiv.org/abs/2506.04645)
8. [Deng, X., Da, J., Pan, E., et al. *SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?* arXiv:2509.16941, 2025 (revised November 14, 2025).](https://arxiv.org/abs/2509.16941)
9. [Lightman, H., Kosaraju, V., Burda, Y., et al. *Let's Verify Step by Step.* arXiv:2305.20050, 2023. Releases PRM800K.](https://arxiv.org/abs/2305.20050)
10. [Cobbe, K., Kosaraju, V., Bavarian, M., et al. *Training Verifiers to Solve Math Word Problems.* arXiv:2110.14168, 2021. Introduces GSM8K.](https://arxiv.org/abs/2110.14168)
11. [Wang, X., Wei, J., Schuurmans, D., et al. *Self-Consistency Improves Chain of Thought Reasoning in Language Models.* arXiv:2203.11171, 2022. ICLR 2023.](https://arxiv.org/abs/2203.11171)
12. [Lambert, N., Morrison, J., Pyatkin, V., et al. *Tulu 3: Pushing Frontiers in Open Language Model Post-Training.* arXiv:2411.15124, 2024. Introduces Reinforcement Learning with Verifiable Rewards (RLVR).](https://arxiv.org/abs/2411.15124)
13. [Gandhi, K., Lee, D., Grand, G., et al. *Stream of Search (SoS): Learning to Search in Language.* arXiv:2404.03683, 2024.](https://arxiv.org/abs/2404.03683)
14. [Guan, X., Zhang, L. L., Liu, Y., et al. *rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking.* arXiv:2501.04519, 2025.](https://arxiv.org/abs/2501.04519)
15. [Yao, S., Yu, D., Zhao, J., et al. *Tree of Thoughts: Deliberate Problem Solving with Large Language Models.* arXiv:2305.10601, 2023. NeurIPS 2023.](https://arxiv.org/abs/2305.10601)
16. [apidog. *GPT-5.5 Pricing.* April 2026.](https://apidog.com/blog/gpt-5-5-pricing/)
17. [Anthropic. *Pricing.* Accessed May 6, 2026.](https://platform.claude.com/docs/en/about-claude/pricing)
18. [DeepSeek. *Pricing.* Accessed May 6, 2026.](https://api-docs.deepseek.com/quick_start/pricing)
19. [ARC Prize. *ARC Prize 2025 Results Analysis.* December 5, 2025.](https://arcprize.org/blog/arc-prize-2025-results-analysis)
20. [Future of Life Institute. *EU AI Act Implementation Timeline.* artificialintelligenceact.eu, 2024.](https://artificialintelligenceact.eu/implementation-timeline/)
21. [Bhardwaj, M. *The Inference Stack in 2026: A Field Note on Token Economics, Runtime Systems, and Model Architecture.* ifitsmanu.com, May 2026.](https://ifitsmanu.com/papers/the-inference-stack-2026)
---
## FAQ
### What is verification economics?
Verification economics is the framework that makes the verifier the primary cost-and-value lever in 2026 inference. It treats *cost-per-correct-answer*, not cost-per-token, as the operational unit. The unit equals blended public-API price times the reasoning multiplier *R* times one plus the rollout ratio ρ̄, divided by the verification accept rate α. The four 2022 to 2024 stack levers (quantization, runtime, decoding parallelism, hardware contestability) act on the price term in the numerator. The new lever, verification, acts on the accept rate in the denominator. Engineering effort in 2026 increasingly compresses the denominator.
### Why is the unit of account shifting from cost-per-token to cost-per-correct-answer?
Three reasons compose. First, reasoning chain-of-thought tokens are billed as output tokens at the standard rate, and reasoning models routinely emit chains tens to hundreds of times longer than the final answer. Second, recent benchmarks measure up to a 5x token-efficiency dispersion between models with comparable accuracy ([Du et al., 2026](https://arxiv.org/abs/2511.05722)), so the per-token unit hides large differences in delivered correctness. Third, the ARC-AGI-2 leaderboard shows that frontier configurations span roughly two orders of magnitude in cost per task at near-equivalent accuracy ([ARC Prize, 2025](https://arcprize.org/blog/arc-prize-2025-results-analysis)), making cost-per-correct-answer the only metric that distinguishes them.
### Why is GPT-5.5's price hike consistent with falling cost-per-correct-answer?
If the verification accept rate α improves enough that *Cost-correct* falls despite a doubled CPM, the per-token reprice is disinflation in the new unit, not inflation. The doubled price reflects the rate-limiting cost of producing answers that pass a stricter internal verification bar. The hypothesis is falsifiable. If GPT-5.5's α improvement on standardized verifier-bound benchmarks does not offset the doubled CPM, the price action is not justified by verification economics. The Artificial Analysis Intelligence Index and the ARC-AGI-2 leaderboard are the surfaces where this measurement will land.
### Where does RLVR fit in this framework?
Reinforcement Learning with Verifiable Rewards, as named in *Tulu 3* ([Lambert et al., 2024](https://arxiv.org/abs/2411.15124)) and exemplified in *DeepSeek-R1* ([DeepSeek-AI, 2025](https://arxiv.org/abs/2501.12948)), concentrates capital into verifier construction at training time so that inference-time generation produces a higher accept rate at the same reasoning multiplier. RLVR is the training-side complement to inference-time verification methods such as best-of-N, self-consistency, and Monte Carlo Tree Search with process reward models. The two sides are interchangeable in principle and complementary in production. The crossover point depends on workload volume.
### What does a small verifier serving a large generator look like?
The cleanest published example is *rStar-Math* ([Guan et al., 2025](https://arxiv.org/abs/2501.04519)). A 7B base model becomes competitive with o1-preview on the MATH benchmark by being trained against and routed through a process preference model that is similarly small. The economic claim is that a small generator plus a small verifier, well-coupled, beats a large monolithic reasoning model on a per-task-cost basis on math. This is the canonical architectural pattern that verification economics rewards. In production, small quantized verifiers can be deployed on-device or close to the user, while generation may remain in the cloud.
### Why does the EU AI Act matter for verification economics?
The remainder of the EU AI Act applies on August 2, 2026, except Article 6(1) ([artificialintelligenceact.eu, 2024](https://artificialintelligenceact.eu/implementation-timeline/)). High-risk system deployers must maintain demonstrable accuracy, transparency, and human-oversight measures. In implementation, these translate to verifier-and-evaluator construction. The α term in *Cost-correct* therefore acquires regulatory weight in addition to engineering weight, and the cost-per-correct-answer unit becomes a compliance unit. The Act forces verification onto every regulated deployer at exactly the moment the producer side is signaling the same shift.
---
## Cite this article
@misc{bhardwaj2026verification,
author = {Bhardwaj, Manu},
title = {The Cost of Being Right: Verification Economics in 2026},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/the-cost-of-being-right},
note = {Field note. Field Notes \#2. Version 1.0.}
}
Bhardwaj, M. (2026, May). The cost of being right: Verification economics in 2026. ifitsmanu.com. https://ifitsmanu.com/papers/the-cost-of-being-right
Bhardwaj, Manu. "The Cost of Being Right: Verification Economics in 2026." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/the-cost-of-being-right.
M. Bhardwaj, "The Cost of Being Right: Verification Economics in 2026," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/the-cost-of-being-right
---
[Previously. The Inference Stack in 2026.](/papers/the-inference-stack-2026) [Research index](/papers). [Home](/).
# https://ifitsmanu.com/papers/the-inference-stack-2026/
# The Inference Stack in 2026
### A Field Note on Token Economics, Runtime Systems, and Model Architecture
*Manu Bhardwaj. ifitsmanu.com. 3 May 2026. Last updated 3 May 2026. Version 3.0.*
[Download as PDF](/pdfs/the-inference-stack-2026.pdf) (12 pages, full math). [Cite this article](#cite-this-article). [Research index](/papers).
> **v3.0 update.** Introduces **Verified Capability per Dollar (VCpD)** as the operational unit of inference economics, with a multiplicative decomposition into four efficiency factors (quantization, runtime, decoding-time parallelism, hardware) calibrated against the 2023–2026 literature. Shows analytically that the Stanford 280-fold compression at fixed quality reduces to roughly $4 \times 3 \times 2.5 \times 3 = 90$ from stack improvements plus ~3x from model-architecture progress. Also explains why GPT-5.5 raised prices in April 2026 without contradicting the long-run trend: at the highest GPQA-Diamond bin, the model-architecture term dominates the cost decomposition. Full derivation, definitions, propositions, and pseudocode in the [PDF](/pdfs/the-inference-stack-2026.pdf).
> **Sequel.** The companion field note **[The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)** (Field Notes #2) develops the "cheaper correct tokens" framing into a formal *Cost-correct* decomposition with explicit reasoning-multiplier and verification-accept-rate terms, applies the framework to OpenAI's April 2026 GPT-5.5 reprice, and traces verification economics through the EU AI Act high-risk obligations entering force in August 2026.
Or view the full PDF inline.
TL;DR
Public LLM API prices fell sharply between 2023 and 2026, but not by a single clean scalar. [GPT-4 launched](https://openai.com/index/gpt-4-research/) in March 2023 at $30 / $60 per million input/output tokens; current pricing spans $0.20 / $1.25 (nano-class) to $5 / $30 (flagship). The compression came from four compounding stack-level changes: weight-only quantization (AWQ, GPTQ, FP8), memory-aware serving runtimes (PagedAttention, continuous batching), speculative decoding, and a hardware market competing on delivered tokens-per-dollar rather than peak TOPS. The operational unit of inference economics is no longer FLOPs or advertised TOPS. It is verified output quality per dollar at a specified latency, context length, and traffic distribution.
## Abstract
The economics of large language model deployment changed substantially between 2023 and 2026. The original GPT-4 API launched at $30 per million prompt tokens and $60 per million completion tokens for the 8K model, while current public API prices span a much wider envelope: from $0.20/$1.25 per million input/output tokens for nano-class models to $5/$30 for current flagship models. This note argues that the price decline should not be described as a single clean "GPT-4-equivalent" scalar. It is better understood as the compound result of four stack-level changes. (i) weight-only quantization and mixed-precision kernels, (ii) memory-aware serving systems such as PagedAttention and iteration-level scheduling, (iii) speculative decoding and related decoding-time parallelism, and (iv) a hardware market in which GPUs, hyperscaler ASICs, and inference-specialized accelerators are all competing on delivered tokens per dollar. The practical engineering implication is simple. The unit of inference economics is no longer FLOPs or advertised TOPS. It is verified output quality per dollar at a specified latency, context length, and traffic distribution.
---
## 1. Why the headline needed correction
The inference stack is the layered system that determines per-token cost in production LLMs: model architecture, weight precision and quantization scheme, serving runtime (memory management, batching, scheduling), decoding strategy (greedy, sampled, speculative), hardware (GPU, ASIC, edge accelerator), and the eval surface that decides whether the tokens are actually correct. Discussing inference economics without naming which of those layers moved is what produces compressed claims like "inference is now 1000x cheaper."
The phrase "GPT-4-equivalent inference is now $0.40 per million tokens" is too compressed to be defensible without a benchmark, a token mix, a latency target, and a definition of equivalence. A public API price can be measured. Model equivalence cannot be inferred from price alone.
A more precise claim is the following. Public language-model API prices have compressed sharply since GPT-4 launched in March 2023, but the compression is uneven across model classes. GPT-4 launched at $30 per million prompt tokens and $60 per million completion tokens for the 8K model, and $60 / $120 for GPT-4-32K. GPT-4o mini later launched at $0.15 / $0.60 per million input/output tokens, while current flagship pricing is materially higher than mini and nano-class pricing. As of this writing, OpenAI's public pricing page lists `gpt-5.5` at $5 / $30 per million input/output tokens, `gpt-5.4-mini` at $0.75 / $4.50, and `gpt-5.4-nano` at $0.20 / $1.25 for standard short-context use. These are price points, not quality-normalized capability statements.
For the rest of this note, I use a simple blended cost-per-million metric:
$$
\text{CPM}_{1:1} \;=\; \frac{P_{\text{input}} + P_{\text{output}}}{2}
$$
where Pinput and Poutput are public API prices per million tokens. This is deliberately simple. Real production CPM depends on cache hit rate, batch / flex tier, prompt-to-output ratio, retry behavior, tool calls, latency tier, and the cost of verification.
Figure 1. Selected public API prices, plotted as a 1:1 blended cost per million tokens. The y-axis is logarithmic. The chart is not quality-normalized. The point is to show the public price envelope, not to claim model equivalence.
Table 1. Public API price points used in Figure 1. Values are in dollars per million tokens.
Model / date
Input
Output
CPM1:1
GPT-4 8K, Mar. 2023
30.00
60.00
45.00
GPT-4 32K, Mar. 2023
60.00
120.00
90.00
GPT-4o mini, Jul. 2024
0.15
0.60
0.375
GPT-4.1, Apr. 2025
2.00
8.00
5.00
GPT-5.4 nano, Mar 2026
0.20
1.25
0.725
GPT-5.4 mini, Mar 2026
0.75
4.50
2.625
GPT-5.4, Mar 2026
2.50
15.00
8.75
GPT-5.5, Apr 2026
5.00
30.00
17.50
Stanford's [2025 AI Index](https://hai.stanford.edu/ai-index/2025-ai-index-report) anchors the decline concretely: at GPT-3.5 quality (MMLU 64.8), public-API inference cost fell from $20.00 per million tokens in November 2022 to $0.07 per million tokens (Gemini 1.5 Flash 8B) in October 2024, a 280-fold compression at that quality bin over that window. OpenAI separately reports that GPT-4o mini's cost per token had dropped 99 percent relative to text-davinci-003. The MIT FutureTech *Price of Progress* analysis ([arXiv:2511.23455](https://arxiv.org/abs/2511.23455)) decomposes the heterogeneity: in the highest GPQA-Diamond bin, frontier-quality cost falls roughly 31x per year; in the lowest bin, only 1.7x per year. A single "X-fold cheaper" headline is therefore wrong by a factor of about 18 depending on which bin is sampled.
Two observations make the picture more interesting than the headline. First, the decline is not monotonic at the frontier: GPT-5.5 was released April 23, 2026 at $5.00/$30.00 per million input/output tokens, a 2x **increase** over GPT-5.4 ($2.50/$15.00) and the first time in three years that an OpenAI flagship raised prices versus its predecessor. Second, dollars per million tokens is the wrong unit on its own: the same $0.20 per million tokens buys very different capability in 2024 versus 2026. The PDF develops the right unit (Verified Capability per Dollar) formally and decomposes it.
---
## 2. The market moved from training economics to inference economics
Training is capital-intensive and episodic. Inference is continuous. Once models are deployed into search, coding, agents, voice, document processing, and internal enterprise workflows, the relevant question becomes not "how many FLOPs can I buy?" but "how many correct, low-latency, policy-compliant tokens can I deliver per dollar?"
This is why cost per token has become a more useful operational metric than raw FLOPs. The metric folds together hardware acquisition or rental cost, memory bandwidth, batching efficiency, KV-cache utilization, software kernels, queueing behavior, and energy. It also exposes a frequent measurement error. A team may optimize a model benchmark while ignoring the serving path that dominates the user-visible bill.
[Deloitte's 2026 TMT prediction](https://www.deloitte.com/us/en/insights/industry/technology/technology-media-and-telecom-predictions/2026/compute-power-ai.html) estimates that inference workloads will account for roughly two-thirds of all AI compute in 2026, up from about one-third in 2023 and half in 2025, and that inference-optimized chips will exceed $50 billion in 2026. [McKinsey's workload model](https://www.mckinsey.com/featured-insights/week-in-charts/the-future-of-ai-workloads) projects that inference will become the dominant AI data-center workload by 2030. The direction is not controversial. The operational center of gravity is shifting from training runs to serving systems.
---
The operational unit of inference economics is no longer FLOPs or advertised TOPS. It is verified output quality per dollar at a specified latency, context length, and traffic distribution.
## 3. Quantization. Lower memory traffic, not free accuracy.
The first inference lever is quantization. The important production pattern is weight-only quantization. Store weights in a lower-bit format while keeping activations in higher precision. In W4A16, weights are represented with 4-bit integers and activations remain 16-bit. In the idealized case, moving from FP16 / BF16 weights to 4-bit weights cuts weight storage by roughly 75 percent. End-to-end memory reduction can be smaller because KV cache, activations, framework overhead, and batching policy still matter.
[AWQ](https://arxiv.org/abs/2306.00978), or Activation-aware Weight Quantization, observes that only a small fraction of weights are especially sensitive. The AWQ paper reports that protecting about 1 percent of salient weights can substantially reduce quantization error, and it identifies these channels using activation statistics rather than weight magnitude alone. [GPTQ](https://arxiv.org/abs/2210.17323) takes a different route. It performs one-shot post-training quantization with approximate second-order information. The GPTQ paper reports 3-bit and 4-bit quantization of very large GPT-family models with small degradation and end-to-end speedups over FP16 on A100 / A6000-class GPUs.
Quantized weights only produce production gains when the serving path uses kernels that avoid giving the savings back through dequantization overhead or poor memory layout. This is where [Marlin](https://arxiv.org/abs/2408.11743) matters. Marlin is a family of mixed-precision kernels designed for batched autoregressive inference. Its core observation is that quantized LLM inference is often memory-bound, so reducing weight movement can approach the theoretical speedup from lower precision if the kernel layout and scheduling are correct.
The engineering rule is not "always use AWQ." It is. Benchmark W4A16 / AWQ / GPTQ / FP8 / NVFP4 or equivalent formats on the exact hardware, model, batch regime, and quality suite you will serve. On NVIDIA Ampere, Ada, Hopper, and Blackwell, [vLLM's quantization documentation](https://docs.vllm.ai/en/latest/features/quantization/) lists AWQ, GPTQ, and Marlin paths among supported formats, which makes a quantized-kernel path a reasonable default candidate to test before shipping a full-precision server.
---
## 4. Serving runtime. Memory management and scheduling.
The second lever is the runtime. Autoregressive inference stresses systems in a specific way. Prefill is compute-heavy, decode is often memory-bandwidth-bound, request lengths vary, and the KV cache grows and shrinks dynamically.
[PagedAttention](https://arxiv.org/abs/2309.06180) addressed a central memory-management problem. In vLLM, KV-cache memory is managed in blocks analogous to virtual memory pages. This reduces fragmentation and permits sharing of key-value blocks across requests. The vLLM paper reports near-zero KV-cache waste and 2 to 4x throughput improvement at the same latency compared with prior serving systems such as FasterTransformer and Orca.
Continuous batching, also called iteration-level scheduling, attacks a different bottleneck. Static batching forces the whole batch to wait for the slowest request. [Orca](https://www.usenix.org/conference/osdi22/presentation/yu) instead schedules at the granularity of generation iterations, so completed requests can leave and new requests can enter without waiting for the entire batch to finish. Orca's OSDI paper reports a 36.9x throughput improvement over FasterTransformer at the same latency on a GPT-3 175B serving setup. That number should be read as a systems-paper result against a specific baseline, not as a universal multiplier. The underlying principle is the important part.
Speculative decoding adds a decoding-time parallelism lever. A small draft model proposes a short continuation. The large target model verifies multiple candidate tokens in one pass. If the draft agrees with the target, multiple tokens are accepted. If not, the system falls back to the first mismatch. The original [speculative decoding paper](https://arxiv.org/abs/2211.17192) reports 2 to 3x acceleration on T5-XXL with identical outputs, and DeepMind's [speculative sampling paper](https://arxiv.org/abs/2302.01318) reports 2 to 2.5x speedup on a 70B Chinchilla model without compromising sample quality.
These techniques compound, but not linearly. The bottleneck changes as each improvement lands. Quantization reduces weight movement. PagedAttention improves KV-cache packing. Continuous batching lifts occupancy under heterogeneous request lengths. Speculation reduces the number of expensive target-model passes. A serving stack that gets all four right can be dramatically cheaper than a naive PyTorch / Hugging Face loop, but the only honest number is the one measured under the production traffic distribution.
---
## 5. Hardware. GPUs remain central, but the inference market is contested.
The hardware story is not "NVIDIA lost inference" or "ASICs replaced GPUs." The more accurate claim is that inference made specialization economically attractive. Once a workload stabilizes, buyers can optimize for tokens per watt, tokens per dollar, memory locality, networking, and software support.
Deloitte lists inference-optimized chips and accelerators from Meta, Google, Amazon, Intel, AMD, Qualcomm, Groq, SambaNova, Cerebras, Graphcore, and others. This does not remove the need for GPU clusters. It creates a heterogeneous procurement problem. GPUs retain advantages in flexibility, ecosystem maturity, training, post-training, and fast model churn. ASICs and inference-specialty accelerators can be attractive when workloads are predictable, batchable, and large enough to justify integration costs.
For engineers, the decision variable is not peak TOPS. Peak TOPS usually ignores memory bandwidth, interconnect, KV-cache behavior, software support, and the cost of hitting latency SLOs. The correct benchmark, [as NVIDIA's own 2026 framing acknowledges](https://blogs.nvidia.com/blog/lowest-token-cost-ai-factories/), is tokens per second per dollar at a fixed quality target, context length, concurrency distribution, and latency SLO.
---
## 6. Architecture. Long context pushed the stack beyond pure attention.
Pure Transformer attention was the default production architecture from roughly 2017 through 2024. It still anchors most production today, but long-context serving exposes the cost of KV-cache growth. At 128K-plus contexts, KV cache can dominate memory and limit batch size.
State-space models such as [Mamba](https://arxiv.org/abs/2312.00752) offer a different scaling profile. The Mamba paper reports linear scaling in sequence length and 5x higher inference throughput than Transformers in its setting. Hybrid architectures combine attention with state-space layers. Attention is retained where global mixing is valuable, while linear-complexity layers carry much of the sequence-processing burden.
[Jamba-1.5](https://arxiv.org/abs/2408.12570) is the clean reference case. The Jamba-1.5 paper describes a hybrid Transformer-Mamba mixture-of-experts model with 398B total parameters, 94B active parameters, and an effective 256K-token context. It reports roughly an order-of-magnitude reduction in KV-cache memory at 256K context compared with similarly sized open models. This is the architectural reason long-context inference is no longer only a question of renting more HBM.
The practical conclusion is not that every production model should be Mamba-like. It is that long-context architecture and serving architecture must be designed together. A retrieval-heavy 8K system, a 256K document-analysis system, and a real-time voice agent should not share the same default inference assumptions.
---
The inference stack in 2026 is not one breakthrough. It is a compound curve.
## 7. Hallucination is also an inference-stack problem.
Hallucination belongs in an inference-stack note because production reliability is part of delivered token quality. A cheap token that is confidently wrong can be more expensive than no token.
OpenAI's 2025 paper, [*Why Language Models Hallucinate*](https://arxiv.org/abs/2509.04664), argues that hallucinations persist partly because standard training and evaluation procedures reward guessing over calibrated uncertainty. [Stanford HAI's legal-domain work](https://hai.stanford.edu/news/hallucinating-law-legal-mistakes-large-language-models-are-pervasive) found hallucination rates ranging from 69 percent to 88 percent on specific legal queries for GPT-3.5, Llama 2, and PaLM 2. Those legal numbers should not be generalized to every modern model or every domain, but they show the key pattern. Hallucination rates vary sharply by task, model, data availability, and verification surface.
The production mitigation is not a better prompt alone. It is a system. Abstention-aware evaluation, retrieval with source constraints, span-level verification, uncertainty surfacing, domain-specific eval sets, and a human escalation path for high-risk outputs.
---
## 8. Engineering implications
1. **Report CPM with context.** A useful CPM number includes model, token mix, cache rate, batch tier, average input/output lengths, SLO, tool-call overhead, and quality gate. A naked price-per-million-tokens number is incomplete.
2. **Benchmark quantized serving before shipping full precision.** W4A16, AWQ, GPTQ, FP8, NVFP4, and related formats should be treated as candidates, not slogans. The best choice depends on model family, hardware, batch size, context length, and eval sensitivity.
3. **Profile prefill and decode separately.** The bottleneck during prefill is not necessarily the bottleneck during decode. Track TTFT, TPOT, queueing delay, KV-cache occupancy, accepted speculative tokens, and tokens per watt.
4. **Do not design long-context systems as prompt-length extensions only.** At 128K-plus contexts, architecture, retrieval, KV-cache layout, prefix caching, and verification become one design problem.
5. **Treat factuality as part of serving quality.** Production inference should measure not only latency and throughput, but also abstention, citation accuracy, retrieval coverage, and verified answer rate.
---
## 9. Conclusion
The inference stack in 2026 is not one breakthrough. It is a compound curve. Public API prices fell because models became smaller and better, quantized serving became practical, kernels improved, KV-cache memory was managed more intelligently, schedulers stopped wasting batches, speculation reduced serial decode cost, and hardware competition moved from peak FLOPs to delivered tokens.
The next engineering regime will be defined less by whether inference becomes cheaper in the abstract and more by how precisely teams can trade off cost, latency, context, reliability, and verification. The systems that win will not simply generate cheaper tokens. They will generate cheaper correct tokens under production constraints.
The systems that win will not simply generate cheaper tokens. They will generate cheaper correct tokens under production constraints.
> **Sequel.** The companion field note **[The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right)** (Field Notes #2) develops the "cheaper correct tokens" framing into a formal *Cost-correct* decomposition with explicit reasoning-multiplier and verification-accept-rate terms, applies the framework to OpenAI's April 2026 GPT-5.5 reprice, and traces verification economics through the EU AI Act high-risk obligations entering force in August 2026.
---
## References
1. [OpenAI. *GPT-4.* March 14, 2023.](https://openai.com/index/gpt-4-research/)
2. [OpenAI. *GPT-4o mini: advancing cost-efficient intelligence.* July 18, 2024.](https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/)
3. [OpenAI. *API Pricing.* Accessed May 3, 2026.](https://openai.com/api/pricing/)
4. [OpenAI Developers. *Pricing.* Accessed May 3, 2026.](https://developers.openai.com/api/docs/pricing)
5. [Stanford Institute for Human-Centered AI. *The 2025 AI Index Report.* 2025.](https://hai.stanford.edu/ai-index/2025-ai-index-report)
6. [NVIDIA. *Rethinking AI TCO. Why Cost per Token Is the Only Metric That Matters.* April 15, 2026.](https://blogs.nvidia.com/blog/lowest-token-cost-ai-factories/)
7. [Deloitte. *Why AI's next phase will likely demand more computational power, not less.* November 18, 2025.](https://www.deloitte.com/us/en/insights/industry/technology/technology-media-and-telecom-predictions/2026/compute-power-ai.html)
8. [McKinsey. *The future of AI workloads.* February 24, 2026.](https://www.mckinsey.com/featured-insights/week-in-charts/the-future-of-ai-workloads)
9. [Lin, J. et al. *AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration.* arXiv:2306.00978, 2023.](https://arxiv.org/abs/2306.00978)
10. [Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. *GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers.* arXiv:2210.17323, 2022.](https://arxiv.org/abs/2210.17323)
11. [Frantar, E. et al. *MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on GPUs.* arXiv:2408.11743, 2024.](https://arxiv.org/abs/2408.11743)
12. [vLLM. *Quantization.* Accessed May 3, 2026.](https://docs.vllm.ai/en/latest/features/quantization/)
13. [vLLM. *INT4 W4A16.* Accessed May 3, 2026.](https://docs.vllm.ai/en/latest/features/quantization/int4/)
14. [Kwon, W. et al. *Efficient Memory Management for Large Language Model Serving with PagedAttention.* SOSP 2023. arXiv:2309.06180.](https://arxiv.org/abs/2309.06180)
15. [Yu, G.-I. et al. *Orca: A Distributed Serving System for Transformer-Based Generative Models.* OSDI 2022.](https://www.usenix.org/conference/osdi22/presentation/yu)
16. [Leviathan, Y., Kalman, M., and Matias, Y. *Fast Inference from Transformers via Speculative Decoding.* arXiv:2211.17192, 2022.](https://arxiv.org/abs/2211.17192)
17. [Chen, C. et al. *Accelerating Large Language Model Decoding with Speculative Sampling.* arXiv:2302.01318, 2023.](https://arxiv.org/abs/2302.01318)
18. [Gu, A. and Dao, T. *Mamba: Linear-Time Sequence Modeling with Selective State Spaces.* arXiv:2312.00752, 2023.](https://arxiv.org/abs/2312.00752)
19. [Lieber, O. et al. *Jamba-1.5: Hybrid Transformer-Mamba Models at Scale.* arXiv:2408.12570, 2024.](https://arxiv.org/abs/2408.12570)
20. [Kalai, A. T., Nachum, O., Vempala, S. S., and Zhang, E. *Why Language Models Hallucinate.* arXiv:2509.04664, 2025.](https://arxiv.org/abs/2509.04664)
21. [Stanford HAI. *Hallucinating Law: Legal Mistakes with Large Language Models are Pervasive.* January 11, 2024.](https://hai.stanford.edu/news/hallucinating-law-legal-mistakes-large-language-models-are-pervasive)
---
## FAQ
### How much did public LLM API prices fall between 2023 and 2026?
Per the [Stanford 2025 AI Index](https://hai.stanford.edu/ai-index/2025-ai-index-report), inference cost fell more than 280-fold between November 2022 and October 2024 for GPT-3.5-class quality. Headline "1000x" claims conflate model classes. The defensible decline is uneven across nano, mini, and flagship tiers. See Table 1 above for OpenAI public pricing across seven model checkpoints from March 2023 through May 2026.
### What is the most useful operational metric for LLM inference economics?
Verified output quality per dollar at a specified latency, context length, and traffic distribution. Naked $/MTok numbers omit cache hit rate, batch tier, prompt/output ratio, retry behavior, tool calls, and the cost of verification. A useful CPM is conditioned on all of these.
### What four stack-level changes drove the inference price decline?
(i) Weight-only quantization (AWQ, GPTQ, FP8, NVFP4) and matched mixed-precision kernels (Marlin). (ii) Memory-aware serving runtimes (PagedAttention, continuous batching, iteration-level scheduling). (iii) Speculative decoding and related decoding-time parallelism. (iv) A hardware market in which GPUs, hyperscaler ASICs, and inference-specialized accelerators compete on delivered tokens-per-dollar rather than peak TOPS.
### Are GPUs still the right default for inference in 2026?
For most production LLM workloads, yes. GPUs retain advantages in flexibility, ecosystem maturity, training, post-training, and fast model churn. Inference-specialty accelerators (Groq, Cerebras, SambaNova, hyperscaler ASICs from Meta, Google, Amazon) become attractive when workloads are predictable, batchable, and large enough to justify integration costs.
### What is the architectural reason long-context inference changed in 2026?
KV-cache memory grows linearly with context length, and at 128K-plus contexts it can dominate memory and limit batch size. Hybrid architectures such as [Jamba-1.5](https://arxiv.org/abs/2408.12570) (Transformer + Mamba state-space + Mixture-of-Experts) report roughly an order-of-magnitude reduction in KV-cache memory at 256K context compared with similarly sized open Transformers. Long-context architecture and serving architecture must now be designed together.
### Why does hallucination belong in an inference-stack note?
A cheap token that is confidently wrong can be more expensive than no token. Production inference quality is the product of latency, throughput, AND verified factuality. The mitigation is a system, not a prompt: abstention-aware evaluation, retrieval with source constraints, span-level verification, uncertainty surfacing, and a human escalation path for high-risk outputs.
---
## Cite this article
@misc{bhardwaj2026inference,
author = {Bhardwaj, Manu},
title = {The Inference Stack in 2026: A Field Note on
Token Economics, Runtime Systems, and Model Architecture},
year = {2026},
month = {May},
url = {https://ifitsmanu.com/papers/the-inference-stack-2026},
note = {Field note. Version 1.0.}
}
Bhardwaj, M. (2026, May). The inference stack in 2026: A field note on token economics, runtime systems, and model architecture. ifitsmanu.com. https://ifitsmanu.com/papers/the-inference-stack-2026
Bhardwaj, Manu. "The Inference Stack in 2026: A Field Note on Token Economics, Runtime Systems, and Model Architecture." ifitsmanu.com, May 2026. https://ifitsmanu.com/papers/the-inference-stack-2026.
M. Bhardwaj, "The Inference Stack in 2026: A Field Note on Token Economics, Runtime Systems, and Model Architecture," ifitsmanu.com, May 2026. [Online]. Available: https://ifitsmanu.com/papers/the-inference-stack-2026
---
[Research index](/papers). [Home](/).
# https://ifitsmanu.com/research/glossary/verification-economics
# Verification economics
**Verification economics** is the framework that treats *cost-per-correct-answer* as the operational unit of inference economics in 2026, replacing cost-per-token. The binding lever in this regime is the verifier: the small model, RL reward function, programmatic check, or self-consistency aggregator that decides which generated tokens are worth keeping.
## Definition
The Cost-correct unit decomposes as
> **Cost-correct = (CPM × R × (1 + ρ̄)) / α(θ, V)**
where
- **CPM** is the blended public-API cost per million tokens (input plus output, divided by two).
- **R** is the reasoning multiplier: the ratio of total billed output tokens (chain-of-thought plus final answer) to final-answer-only tokens for the same task. R = 1 for non-reasoning models. R can exceed 100 for reasoning models that perform extensive search.
- **ρ̄** is the average rollout-or-rejection ratio under verifier-guided decoding (best-of-N, MCTS-at-decode, self-consistency). For a model that samples once, ρ̄ = 0. For a system that samples 16 candidates and verifies, ρ̄ ≈ 15.
- **α(θ, V)** is the verification accept rate at quality threshold θ on verifier V.
The Verified Capability per Dollar framework introduced in Field Notes #1 is the special case R → 1, ρ̄ → 0, α → 1. Cost-correct extends VCpD by making the reasoning, rollout, and verification terms first-class denominators of the unit.
## Why this matters in 2026
Three observable shifts justify the new unit.
First, reasoning is billed as output tokens. Across every major lab's public pricing schedule as of May 2026, internally generated chain-of-thought tokens are charged at the standard output rate. A reasoning model that emits a 50,000-token chain-of-thought before a 500-token final answer is a 100-to-1 reasoning-to-answer ratio billed entirely at the output rate.
Second, the multiplier is large and variable. Recent benchmarks (OckBench, arXiv:2511.05722) measure up to a 5x token-efficiency dispersion between reasoning models that achieve similar accuracy on the same problem.
Third, the ARC-AGI-2 leaderboard shows a 70x-plus cost-per-task spread across published frontier configurations at near-equivalent accuracy. The dispersion is verification-conditional, not capability-conditional.
## The lever
CPM compresses through stack-level engineering: quantization, kernels, runtime, hardware. α (the verification accept rate) compresses through training-side and inference-side verifier engineering. The two are different disciplines.
Training-side verifiers concentrate capital into RL with verifiable rewards (RLVR, named in Tulu 3, Lambert et al. 2024) and process reward models (PRM800K, Lightman et al. 2023). DeepSeek-R1 (Nature 645:633-638) is the canonical demonstration of pure-RL reasoning with verifiable rewards.
Inference-side verifiers include best-of-N selection, self-consistency over sampled paths, Monte Carlo Tree Search at decode time (rStar-Math, Guan et al. 2025), and self-evaluation in Tree of Thoughts (Yao et al., NeurIPS 2023).
The economic claim is that a small generator coupled to a small verifier can beat a large monolithic reasoning model on a per-task-cost basis. *rStar-Math* improves Phi3-mini-3.8B's MATH accuracy from 41.4% to 86.4% by routing through a process preference model, surpassing o1-preview at small scale.
## Production guidance
- Report Cost-correct, not CPM, when communicating production economics.
- Specify the verifier alongside the model: any "X% accuracy at $Y per task" claim is incomplete without naming the verifier under which X is measured.
- Track α as a first-class production metric. A regression in α is a more expensive failure than a CPM spike.
- Treat the verifier as a deployable artifact: versioned, evaluated, monitored for drift, often smaller and quantized, often deployable on-device.
## Related
- [The Cost of Being Right. Verification Economics in 2026.](/papers/the-cost-of-being-right). Field note that introduces the framework with full bibliography and PDF.
- [The Inference Stack in 2026](/papers/the-inference-stack-2026). Defines Verified Capability per Dollar (VCpD); Cost-correct extends it.
- [AWQ quantization](/research/glossary/awq-quantization). One of the four CPM levers.
- [Speculative decoding](/research/glossary/speculative-decoding). Decoding-time parallelism lever.
## References
1. Bhardwaj, M. *The Cost of Being Right: Verification Economics in 2026.* ifitsmanu.com, May 2026. [link](https://ifitsmanu.com/papers/the-cost-of-being-right)
2. Lambert, N. et al. *Tulu 3: Pushing Frontiers in Open Language Model Post-Training.* arXiv:2411.15124, 2024. [link](https://arxiv.org/abs/2411.15124)
3. Lightman, H. et al. *Let's Verify Step by Step.* arXiv:2305.20050, 2023. [link](https://arxiv.org/abs/2305.20050)
4. DeepSeek-AI. *DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.* arXiv:2501.12948, 2025. [link](https://arxiv.org/abs/2501.12948)
5. Du, Z. et al. *OckBench: Measuring the Efficiency of LLM Reasoning.* arXiv:2511.05722, 2025. [link](https://arxiv.org/abs/2511.05722)
---
[Glossary](/research/glossary). [Research index](/papers). [Home](/).
# https://ifitsmanu.com/research/glossary/awq-quantization
# AWQ quantization
**AWQ (Activation-Aware Weight Quantization)** is a post-training quantization method for large language models. It compresses model weights from 16-bit floating point to 4-bit integer representation, reducing memory footprint by roughly 75 percent while preserving most of the model's quality.
## Definition
AWQ analyzes activation patterns during a calibration pass over a small dataset, identifies the small subset of weights that carry disproportionate signal in the model's output, and protects those weights from aggressive quantization. The remaining weights are quantized to INT4 with per-group scaling factors. The result is a model that fits in roughly one quarter of the VRAM of its BF16 baseline, runs faster on memory-bound inference workloads, and degrades quality less than naive INT4 quantization.
## Mechanism
The key observation behind AWQ is that not all weights matter equally. Activation magnitudes vary across channels, and the channels with large activations are sensitive to weight quantization error. AWQ uses an activation-aware scaling search to find a per-channel scale that minimizes the impact of quantization on the most important channels.
Concretely, the method:
1. Runs calibration data through the unquantized model and collects activation statistics per channel.
2. Solves for a per-channel scale factor that, when applied to the weights before quantization, minimizes the error introduced by 4-bit rounding.
3. Quantizes weights with the chosen scales to INT4 with per-group dequantization at inference time.
## Tradeoffs
- **Pros.** Roughly 75 percent VRAM reduction. Faster inference on memory-bound workloads. Quality degradation is acceptable for most production tasks (summarization, classification, code completion).
- **Cons.** Quality degradation is noticeable on hard reasoning and math benchmarks. Requires a representative calibration dataset. Choice of group size (commonly 128) trades quality for memory.
## Production status, 2026
AWQ is widely used for production LLM serving alongside GPTQ. Both are supported in vLLM, SGLang, and TensorRT-LLM. The throughput advantage of AWQ over baseline FP16 grows substantially when paired with **Marlin kernels**, a kernel family optimized for INT4 weight matrices on modern GPUs. Together, AWQ plus Marlin can deliver an order of magnitude more tokens per second than vanilla FP16 on the same hardware [1].
## Related
- [Speculative decoding](/research/glossary/speculative-decoding). Runtime technique that compounds with quantization for end-to-end throughput gains.
- [The Inference Stack in 2026](/papers/the-inference-stack-2026). Field note on the broader inference cost collapse.
## References
[1] VRLATech. *LLM Quantization Explained: INT4, INT8, FP8, AWQ, and GPTQ in 2026.* [link](https://vrlatech.com/llm-quantization-explained-int4-int8-fp8-awq-and-gptq-in-2026/)
---
[Glossary](/research/glossary). [Research index](/papers). [Home](/).
# https://ifitsmanu.com/research/glossary/speculative-decoding
# Speculative decoding
**Speculative decoding** is an inference-time technique that accelerates large language model serving by 2 to 3 times with no quality loss. It uses a small draft model to propose multiple tokens in advance, then verifies them in a single forward pass of the larger target model.
## Definition
In standard autoregressive decoding, generating *n* tokens requires *n* sequential forward passes through the model. Each pass produces one token, conditioned on all previous tokens. The bottleneck is the sequential nature of the dependency.
Speculative decoding breaks this dependency by introducing a fast draft model that runs in parallel. The draft model proposes *k* candidate tokens at once. The target model then performs a single forward pass over those *k* tokens, computing the probability distributions it would have produced if generating them itself. The longest prefix where the target model agrees with the draft is accepted in one shot. The first disagreement is corrected and decoding continues from there.
## Why it works
Modern LLM inference is memory-bandwidth-bound. A single forward pass of a large model spends most of its time loading parameters from HBM into compute, not actually computing. Verifying *k* tokens in one pass is nearly free relative to verifying one. The draft model's work is amortized.
When the draft model is good (high acceptance rate), most generations get multiple tokens per target-model pass. End-to-end latency drops, throughput rises, quality is unchanged.
## Tradeoffs
- **Pros.** No quality loss versus the target model. Compounds with quantization and other runtime tricks. Production-ready in vLLM, TensorRT-LLM, and SGLang.
- **Cons.** Requires a compatible draft model (smaller, same tokenizer, similar distribution). Acceptance rate dominates effective speedup; a poor draft model gives marginal gains.
## Practical speedups
In production, end-to-end speedups of 2 to 3 times are routine when the draft model has a high acceptance rate (60 to 80 percent). For long-context generation with predictable structure, gains can be higher.
## Related
- [AWQ quantization](/research/glossary/awq-quantization). Reduces memory pressure; compounds with speculative decoding.
- [The Inference Stack in 2026](/papers/the-inference-stack-2026). Section 3 explains the runtime stack including continuous batching, PagedAttention, and speculative decoding.
---
[Glossary](/research/glossary). [Research index](/papers). [Home](/).
# https://ifitsmanu.com/research/glossary/mamba-state-space
# Mamba and state-space models
**Mamba** is a selective state-space model (SSM) architecture for sequence modeling. It achieves transformer-class quality on language tasks while running in linear time and constant memory with respect to sequence length, in contrast to the quadratic-time, linear-memory attention layer.
## Definition
State-space models are a family of sequence models drawn from classical control theory. They maintain a continuous-time hidden state that evolves through linear differential equations, summarizing the entire sequence history in a fixed-size representation. Mamba (Gu and Dao, 2023) made SSMs competitive with transformers by introducing selectivity: the parameters of the state-space dynamics depend on the input, allowing the model to selectively retain or forget information per token.
## Why it matters
Pure-transformer attention is *O(n²)* in sequence length and requires a key-value (KV) cache that grows linearly with context. At long contexts (128K, 256K, 1M tokens), this becomes economically punishing both in memory and in compute.
Mamba and related selective SSMs are *O(n)* in sequence length with constant per-step memory. For long-context workloads, the throughput advantage is substantial.
## Hybrid is the production frontier
Pure Mamba models underperform pure transformers on some short-context retrieval-style tasks, where attention's ability to directly query any prior token is the right primitive. The 2025 to 2026 production frontier is **hybrid**: transformer attention layers interleaved with Mamba layers, often with Mixture-of-Experts on top.
The flagship example is **Jamba 1.5** (AI21): 398B total parameters, 94B active, 256K-token context, with Mamba and attention layers at a 1:7 ratio and MoE every two blocks. Mamba-3 was published in 2026.
## Tradeoffs
- **Pros.** Linear sequence complexity. Smaller inference-time memory. Up to 5x throughput vs equivalent pure-transformer at long context. Smaller KV cache.
- **Cons.** Pure SSMs lag on tasks requiring sharp attention to specific prior tokens. Hybrid architectures recover this at the cost of architectural complexity.
## Related
- [The Inference Stack in 2026](/papers/the-inference-stack-2026). Section 5 covers hybrid architectures and Jamba 1.5 in detail.
- [Edge AI silicon: CV5 vs Jetson vs Hexagon](/research/glossary/edge-ai-silicon). Where memory constraints make linear-complexity sequence models particularly valuable.
## References
- AI21. *Jamba 1.5: Hybrid Transformer-Mamba MoE Models.* [link](https://www.ai21.com/blog/announcing-jamba/)
- Gu, A. and Dao, T. *Mamba: Linear-Time Sequence Modeling with Selective State Spaces.* [link](https://github.com/state-spaces/mamba)
---
[Glossary](/research/glossary). [Research index](/papers). [Home](/).
# https://ifitsmanu.com/research/glossary/edge-ai-silicon
# Edge AI silicon. CV5 vs Jetson vs Hexagon.
A field comparison of the three edge silicon platforms most relevant to drone autonomy, embedded vision, and on-device inference in 2026.
## At a glance
Table 1. Edge AI silicon, 2026. TOPS figures are vendor-published peaks; effective workload throughput depends on model, kernel, and memory. Sources: Nvidia developer pages, Ambarella product briefs.
Platform
Peak TOPS
Power envelope
Best fit
Ambarella CV5
~20 TOPS
Low (battery-budget)
Small drones, video-first vision, on-device 8K capture
Nvidia Jetson AGX Orin
~275 TOPS
Medium to high
Industrial robotics, autonomous mobile robots, dev-friendly stack
Nvidia Jetson Thor
~2070 FP4 TFLOPS
High
Industrial robotics, medical AI, edge LLM serving
Qualcomm Hexagon
~40 TOPS (Ventuno Q)
Low to medium
Mobile, voice, robotics, on-device LLMs
## Ambarella CV5
CV5 is an imaging-first SoC. Its differentiator is a high-quality video pipeline (8K, HDR, low-light) layered with AI acceleration optimized for vision tasks. For small drones with strict battery and weight budgets, CV5 wins on power efficiency and on the quality of the underlying imaging stack. Where it loses ground is on raw AI compute for large models. CV5 powers the Antigravity A1 drone shown at CES 2026.
## Nvidia Jetson AGX Orin
Jetson AGX Orin is the workhorse of industrial robotics in 2026. Roughly 275 TOPS, mature CUDA tooling, JetPack SDK, broad model support, and a large developer ecosystem. The cost is power: AGX Orin draws meaningfully more than CV5 or Hexagon. For robotics platforms with reasonable power budgets, AGX Orin is the default.
## Nvidia Jetson Thor
Thor is the next-generation Jetson, targeted at industrial robotics, medical AI, and edge generative-AI workloads. With around 2070 FP4 TFLOPS and 128 GB of memory, Thor is capable of running meaningfully larger models on-device than Orin. Useful for humanoid robotics, multimodal perception, and on-edge LLM serving.
## Qualcomm Hexagon
Hexagon is Qualcomm's tensor processor, integrated into Snapdragon SoCs and the standalone Arduino Ventuno Q dev board (~40 TOPS). It targets mobile, robotics, and on-device LLM workloads with low to medium power budgets. The Ventuno Q broke the developer-board market open with an 8-core ARM CPU plus Adreno GPU plus Hexagon NPU. For voice agents, on-device LLMs, and mobile robotics, Hexagon is increasingly competitive.
## How to choose
- **Drone with strict battery, video-first.** CV5.
- **Industrial robot with reasonable power, mature tooling.** Jetson AGX Orin.
- **Humanoid or industrial robot needing on-device LLMs.** Jetson Thor.
- **Mobile, voice, or robotics with low power and modern SDK access.** Qualcomm Hexagon (Snapdragon or Ventuno Q).
In practice, the right answer is workload-dependent. A drone needs different silicon than a humanoid. The TOPS number alone is not the answer. Memory bandwidth, video pipeline quality, SDK maturity, power envelope, and total cost of ownership all matter.
## Related
- [GPS-denied navigation](/research/glossary/gps-denied-navigation). What the silicon actually runs in a drone autonomy stack.
- [The Inference Stack in 2026](/papers/the-inference-stack-2026). Field note on the broader inference economics, including the rise of custom silicon.
---
[Glossary](/research/glossary). [Research index](/papers). [Home](/).
# https://ifitsmanu.com/research/glossary/gps-denied-navigation
# GPS-denied navigation
**GPS-denied navigation** is the problem of localizing and navigating an autonomous vehicle (drone, robot, ground vehicle) when GPS signals are unavailable, unreliable, or deliberately denied. It is one of the central engineering problems in modern drone autonomy.
## Definition
A GPS receiver gives a vehicle position to within a few meters in open sky. Indoors, in urban canyons, under tree canopy, in tunnels, or under active jamming, GPS is degraded or absent. GPS-denied navigation systems replace satellite-derived position with onboard sensing and computation.
## The sensor stack
A typical GPS-denied stack combines several sensor modalities:
- **Visual-inertial odometry (VIO).** Cameras paired with an inertial measurement unit (IMU). The IMU integrates acceleration and rotation to estimate motion. The camera observes the world; visual features are tracked across frames to correct IMU drift.
- **LiDAR.** Direct depth sensing. Useful for SLAM (simultaneous localization and mapping) at higher cost and weight than cameras.
- **Stereo cameras.** Depth from disparity between two cameras at known baseline.
- **Radar and event cameras.** Less common but valuable in low-light or high-speed scenarios.
- **Magnetometer, barometer, temperature.** Auxiliary signals.
These streams are fused, often by an extended Kalman filter or a learned model, into a continuous estimate of position, orientation, and velocity.
## Where edge AI fits
Three places.
**Visual feature extraction.** Modern VIO uses learned feature detectors and descriptors that outperform classical SIFT or ORB features, especially in low-texture or low-light scenes. Running these models on edge silicon (Ambarella CV5, Nvidia Jetson, Qualcomm Hexagon) at frame rate is a real-time inference problem with hard latency budgets.
**Object recognition and obstacle classification.** Identifying what is in the scene matters for both navigation and downstream autonomy. Edge AI runs object detectors and segmenters in real time on power-constrained platforms.
**End-to-end learned localization.** Newer research uses neural networks to learn the localization function directly from sensor inputs, bypassing some of the classical estimation pipeline. Practical deployment requires careful eval against classical baselines.
## Why it matters in 2026
Drones for delivery, inspection, surveying, agriculture, search and rescue, and defense increasingly operate in environments where GPS cannot be assumed. The military case has been clear for years; the commercial case is becoming clear as drones move beyond hobby use into industrial deployment.
The combination of low-power edge silicon, modern visual-inertial models, and increasingly capable on-device inference makes GPS-denied navigation a practical product feature, not just a research topic.
## Related
- [Edge AI silicon: CV5 vs Jetson vs Hexagon](/research/glossary/edge-ai-silicon). The chips that run the perception stack on real drones.
---
[Glossary](/research/glossary). [Research index](/papers). [Home](/).